Clear Sky Science · es
Modelo híbrido de aprendizaje profundo para la predicción de la calidad del aire y su impacto en la salud
Por qué importan un aire más limpio y previsiones más inteligentes
La contaminación del aire es más que un horizonte brumoso: empeora silenciosamente los problemas respiratorios, sobrecarga el corazón y acorta la vida. Las autoridades municipales ahora confían en el Índice de Calidad del Aire (ICA) para advertir a la población cuando no es seguro salir, pero esas alertas frecuentemente se basan en datos de días anteriores o en previsiones sencillas que no detectan picos repentinos. Este artículo explora una nueva forma de predecir la calidad del aire a corto plazo usando una combinación de modelos informáticos avanzados y variables cuidadosamente diseñadas, con el objetivo de ofrecer advertencias más tempranas y fiables a las personas y a los sistemas de salud.
Del aire sucio a un único número de alerta sanitaria
El estudio se centra en Gurugram, una ciudad de rápido crecimiento en India donde el tráfico, la industria y la construcción contribuyen a la mala calidad del aire. Se recopilaron seis contaminantes clave —partículas finas (PM2.5 y PM10), ozono troposférico, dióxido de nitrógeno, dióxido de azufre y monóxido de carbono— de forma horaria durante cuatro meses mediante el servicio de contaminación del aire de OpenWeather. Estas mediciones se convirtieron en un único valor de ICA comparando cada contaminante con los límites nacionales de seguridad y tomando luego el más desfavorable como la puntuación global de la ciudad. Este valor de ICA es lo que la gente ve en las apps meteorológicas como categorías tales como “Bueno”, “Moderado”, “Malo” o “Grave”, cada una asociada a diferentes niveles de preocupación sanitaria.
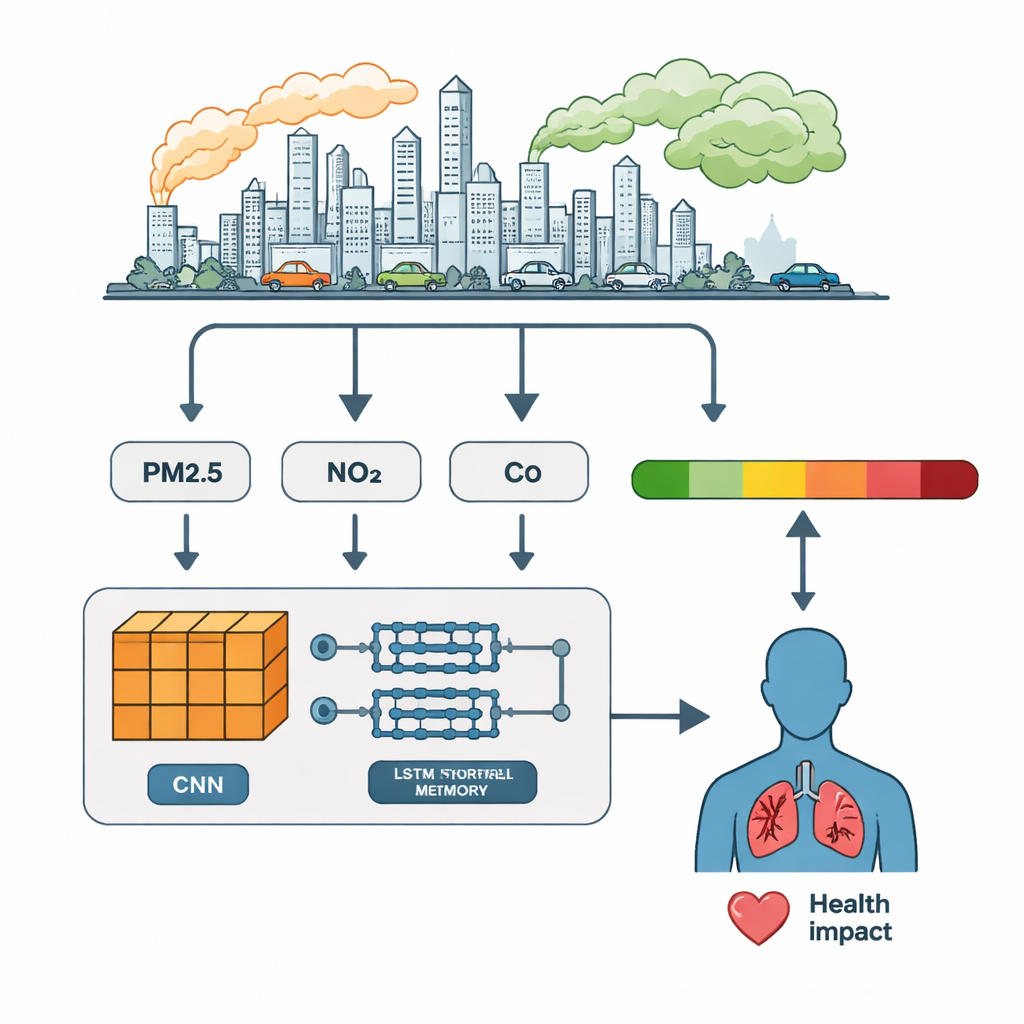
Enseñar a las máquinas a leer los ritmos de la contaminación
En lugar de alimentar al modelo únicamente con las lecturas brutas de los contaminantes, los autores primero crearon características adicionales que reflejan cómo se comporta el aire en la práctica. Añadieron valores rezagados para mostrar cómo era la contaminación unas horas antes, medias móviles para suavizar picos breves y cocientes como PM2.5/PM10 para distinguir el polvo fino del grueso. También codificaron patrones del calendario —como la hora del día, el día de la semana y el mes— usando señales cíclicas para capturar la actividad humana rutinaria, por ejemplo el tráfico entre semana o la reducción de actividad los fines de semana. Estas señales diseñadas por expertos pretendían ayudar a los modelos a detectar tendencias sutiles e interacciones que los números crudos por sí solos pueden ocultar.
Combinando dos tipos de aprendizaje profundo
Los investigadores compararon tres enfoques de aprendizaje profundo. Una red neuronal convolucional unidimensional (CNN) destaca en identificar patrones locales —ráfagas breves o formas en los datos. Una red de memoria a largo plazo (LSTM) sobresale en recordar cómo evolucionan los valores a lo largo del tiempo. El modelo híbrido CNN–LSTM encadena estas fortalezas: primero, capas CNN comprimen y resaltan las características importantes de las secuencias de contaminantes; luego, capas LSTM siguen cómo cambian esas características hora a hora. Los tres modelos se entrenaron con la mayor parte de los datos y se evaluaron con el resto, usando métricas estándar como precisión, recall y F1-score para juzgar qué tan bien asignaban cada hora a la categoría correcta del ICA.
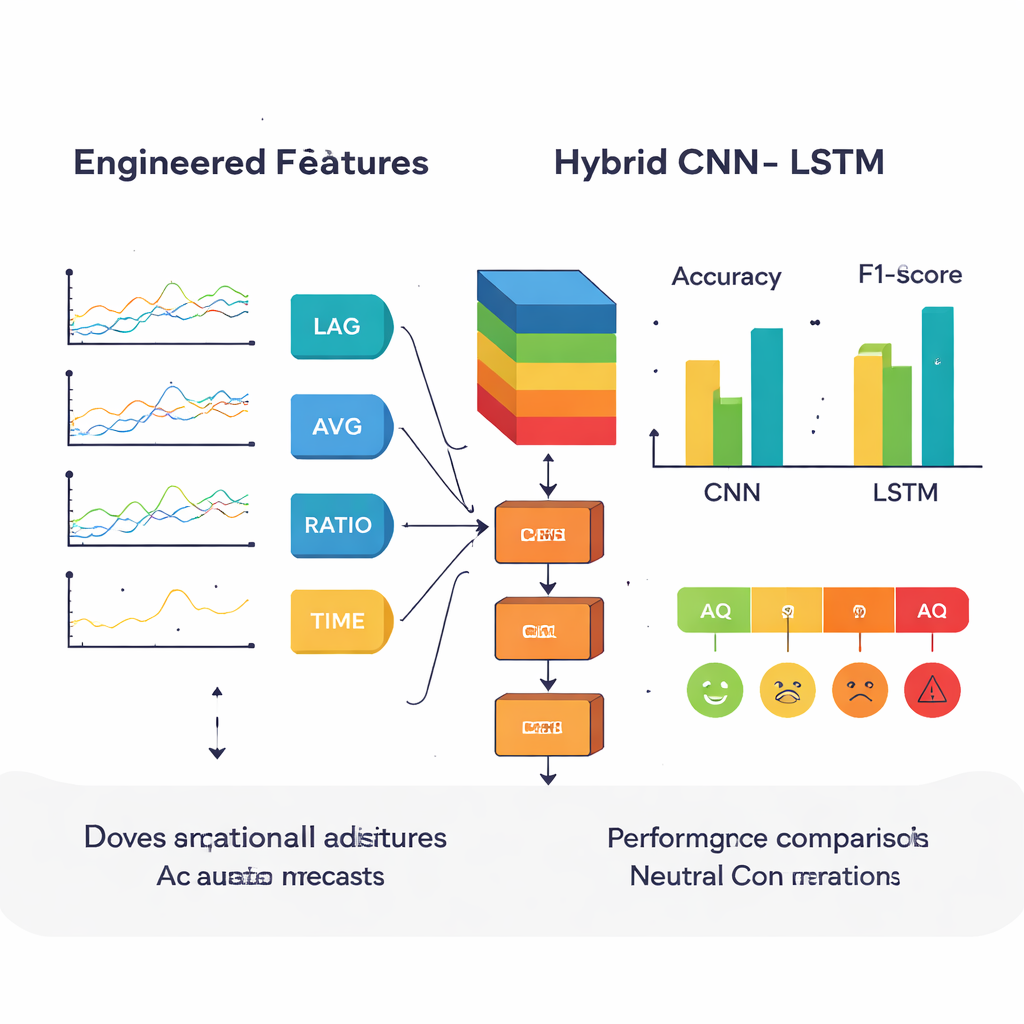
Previsiones más precisas y su significado para la salud
En experimentos repetidos, el modelo híbrido ofreció de forma consistente el mejor equilibrio entre precisión y fiabilidad. Con las características diseñadas incluidas, alcanzó un F1-score de aproximadamente el 91 por ciento, ligeramente por delante del LSTM individual y claramente superior a la CNN. Además, distinguió especialmente bien en el extremo más contaminado de la escala, raramente confundiendo aire “Grave” con categorías más seguras. Un complemento sencillo tradujo cada nivel de ICA predicho en una estimación aproximada de riesgo para la salud, indicando, por ejemplo, que condiciones “Muy malas” y “Graves” corresponden a probabilidades mucho mayores de sufrir problemas respiratorios y cardíacos. Los autores subrayan que estas puntuaciones de riesgo son orientativas y no diagnósticos médicos, pero muestran cómo las previsiones de calidad del aire pueden convertirse en señales de salud más intuitivas.
Qué implica esto para las ciudades y los ciudadanos
El estudio concluye que combinar entradas diseñadas con cuidado con una arquitectura híbrida CNN–LSTM puede hacer que las previsiones de ICA a corto plazo sean tanto más precisas como más estables que el uso de un único modelo. Aunque el trabajo se limita a una ciudad y a unos pocos meses de datos, apunta hacia herramientas prácticas que podrían informar cierres escolares, horarios de trabajo al aire libre, preparación hospitalaria y decisiones personales como cuándo hacer ejercicio fuera o usar mascarilla. Con conjuntos de datos más largos y pruebas más amplias, sistemas similares podrían convertirse en la columna vertebral de la supervisión de la calidad del aire basada en datos, proporcionando advertencias más tempranas sobre aire no saludable y ayudando a los responsables a actuar antes de que la contaminación alcance su punto máximo.
Cita: Madan, T., Sagar, S., Singh, Y. et al. Hybrid deep learning model for air quality prediction and its impact on healthcare. Sci Rep 16, 6036 (2026). https://doi.org/10.1038/s41598-026-36564-5
Palabras clave: índice de calidad del aire, aprendizaje profundo, CNN-LSTM, riesgo para la salud, predicción de contaminación