Clear Sky Science · es
Un modelo híbrido ResNet50-transformador visual con un mecanismo de atención para la clasificación de imágenes aéreas
Por qué importan ojos más inteligentes en el cielo
Las fotos aéreas tomadas por drones y satélites orientan hoy la respuesta a desastres, la planificación urbana, la agricultura e incluso el control del tráfico. Pero enseñar a los ordenadores a comprender estas vistas complejas y abarrotadas desde arriba sigue siendo difícil. Este estudio presenta dos nuevos modelos de inteligencia artificial que combinan diferentes modos de “ver” las imágenes para reconocer diez tipos de objetos en fotos de drones —como edificios, coches, árboles y carreteras— con mayor precisión que métodos anteriores. Su enfoque podría hacer que la monitorización automatizada desde el aire sea más rápida, fiable y fácil de desplegar en escenarios reales.
Desafíos de mirar el mundo desde arriba
Las imágenes aéreas difieren de las fotos cotidianas que hacemos con el móvil. Los objetos son más pequeños, pueden aparecer en ángulos extraños y con frecuencia están muy agrupados. Un coche parcialmente oculto por un árbol, un sendero estrecho o montones de escombros tras un desprendimiento pueden ser difíciles incluso para un humano de detectar rápidamente. Sin embargo, gobiernos, equipos de emergencia y agencias medioambientales dependen cada vez más de las vistas de drones y satélites para rastrear inundaciones, incendios forestales, crecimiento urbano y daños en infraestructuras. Con miles de satélites en órbita y un mercado de imágenes aéreas en auge, el volumen de datos crece demasiado rápido para que las personas lo inspeccionen manualmente, lo que impulsa la necesidad de clasificación automática más precisa y eficiente.
Combinando dos maneras en que las máquinas aprenden a ver
La mayoría de los sistemas de reconocimiento de imágenes exitosos hoy en día se basan en aprendizaje profundo. Una familia, las redes neuronales convolucionales, sobresale en detectar patrones locales como bordes, texturas y formas pequeñas. Otra, más reciente, denominada transformadores visuales trata la imagen como una secuencia de parches y es especialmente buena captando relaciones a largo alcance, por ejemplo cómo una carretera, un conjunto de tejados y un campo abierto cercano encajan en una escena. Este trabajo combina ambos: un modelo convolucional conocido, ResNet-50, y un transformador visual. Cada uno procesa la misma imagen aérea y extrae su propio conjunto de características numéricas —resúmenes compactos de lo que la red ha aprendido sobre la escena—. Estas dos corrientes de información se unen después y se pasan a un módulo de “atención” que aprende qué características importan más para decidir entre las diez clases objetivo.
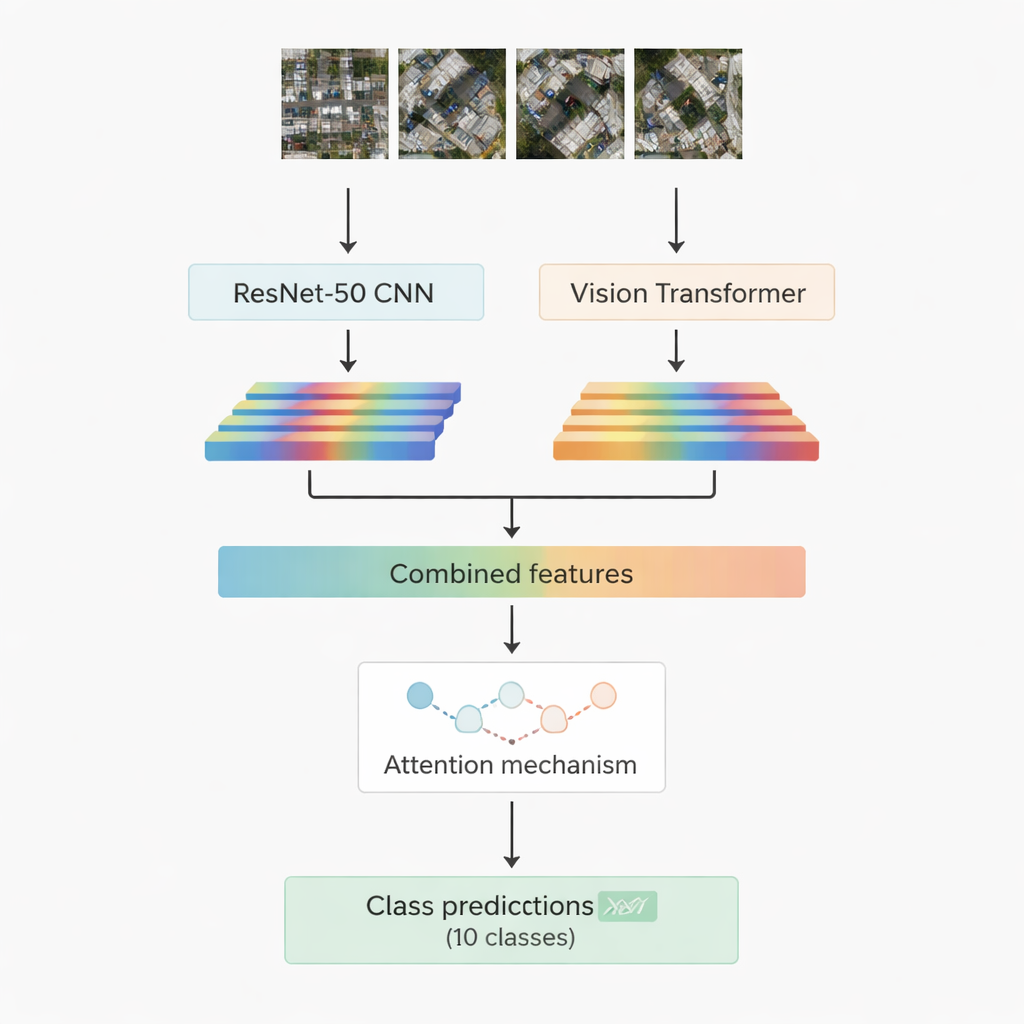
Dos estrategias de atención para centrarse en lo importante
Los autores diseñan y prueban dos versiones de su sistema híbrido. En la primera, simplemente combinan las características de ResNet-50 y del transformador y las alimentan a un módulo de atención multi-cabeza. Este mecanismo puede entenderse como muchos focos pequeños que miran las características desde ángulos ligeramente distintos y luego combinan sus hallazgos. En la segunda versión utilizan atención cruzada: las características de la red convolucional actúan como una consulta que le pide a las características del transformador dónde mirar, permitiendo que una corriente guíe a la otra. En ambos casos, la salida de atención se procesa mediante capas estándar que finalmente asignan el parche de imagen a una de las diez clases, incluidas edificaciones, coches, escombros, senderos, carreteras metálicas, campos abiertos, sombras, tanques, árboles y tejados.
Pruebas con imágenes de drones del mundo real
Para evaluar el desempeño de sus modelos, los autores utilizan un conjunto de datos público del estado indio de Sikkim, recopilado por un dron volando entre 60 y 120 metros sobre el suelo. Los datos cubren ríos, bosques, colinas y zonas urbanizadas, cortados en pequeños parches de modo que cada imagen pertenece a una de las diez categorías. El conjunto está equilibrado, con un número igual de imágenes de entrenamiento y prueba por clase, lo que lo convierte en un banco de pruebas justo. Los investigadores entrenan ambos modelos híbridos en condiciones idénticas y luego comparan su rendimiento usando medidas ampliamente conocidas: precisión, exactitud, sensibilidad (recall), puntuación F1, matrices de confusión y curvas ROC. También comparan sus resultados con varias redes bien conocidas y métodos más recientes basados en transformadores de la literatura reciente.

Clasificación más nítida y potencial en el mundo real
Ambos modelos híbridos superan a sistemas anteriores en este conjunto de datos, alcanzando precisiones globales del 95,52% y del 95,80%, con la versión de atención multi-cabeza ligeramente por delante. Su rendimiento se mantiene alto y estable en las diez categorías, y los análisis detallados muestran que incluso las clases más débiles se reconocen con tasas elevadas. Esto sugiere que mezclar redes convolucionales, transformadores visuales y mecanismos de atención es una receta potente para comprender escenas aéreas complejas. Para un lector general, la conclusión es que los ordenadores cada vez responden mejor a preguntas como “¿Dónde están las carreteras?” o “¿Qué parches muestran escombros o edificios?” en grandes colecciones de imágenes de drones. A medida que estos modelos se refinan y se extienden a nuevos conjuntos de datos, podrían sustentar respuestas a desastres más inteligentes, monitorización ambiental y servicios de ciudades inteligentes que dependan de una interpretación rápida y fiable de imágenes desde arriba.
Cita: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Palabras clave: clasificación de imágenes aéreas, imágenes de drones, aprendizaje profundo, transformador visual, teledetección