Clear Sky Science · es
Análisis del rendimiento de una red dependiente a largo plazo en cascada optimizada por atención y shuffle para e‑learning adaptativo entre profesionales de TI
Formación online más inteligente para profesionales tecnológicos en activo
Para muchos profesionales de tecnologías de la información (TI), los cursos en línea son hoy la principal forma de mantener sus competencias actualizadas. Pero la mayoría de las plataformas de formación sigue evaluando con herramientas toscas como totales de cuestionarios o insignias de finalización. Este estudio presenta una manera más inteligente de interpretar las «huellas» digitales que dejan los alumnos y convertirlas en información precisa y en tiempo real sobre cuánto está aprendiendo realmente cada persona.
Por qué los cursos online estándar se quedan cortos
El e‑learning convencional trata a la mayoría de los alumnos por igual: todos ven los mismos módulos, hacen los mismos cuestionarios y se les juzga con los mismos exámenes fijos. Ese enfoque pasa por alto las diferencias en el progreso de los profesionales, especialmente en campos que cambian rápido como la ciberseguridad o la computación en la nube. Investigaciones anteriores intentaron corregir esto con aprendizaje automático —combinando notas de cuestionarios, tiempo dedicado y datos de clics para predecir el éxito—, pero muchos modelos se atrancaron ante datos ruidosos o incompletos, no pudieron escalar a plataformas reales o no supieron seguir cómo evoluciona el aprendizaje a lo largo de semanas y meses. El resultado era a menudo una retroalimentación tardía y burda que no orientaba fácilmente contenidos personalizados ni intervenciones oportunas.
Convertir registros crudos del curso en datos limpios y equitativos
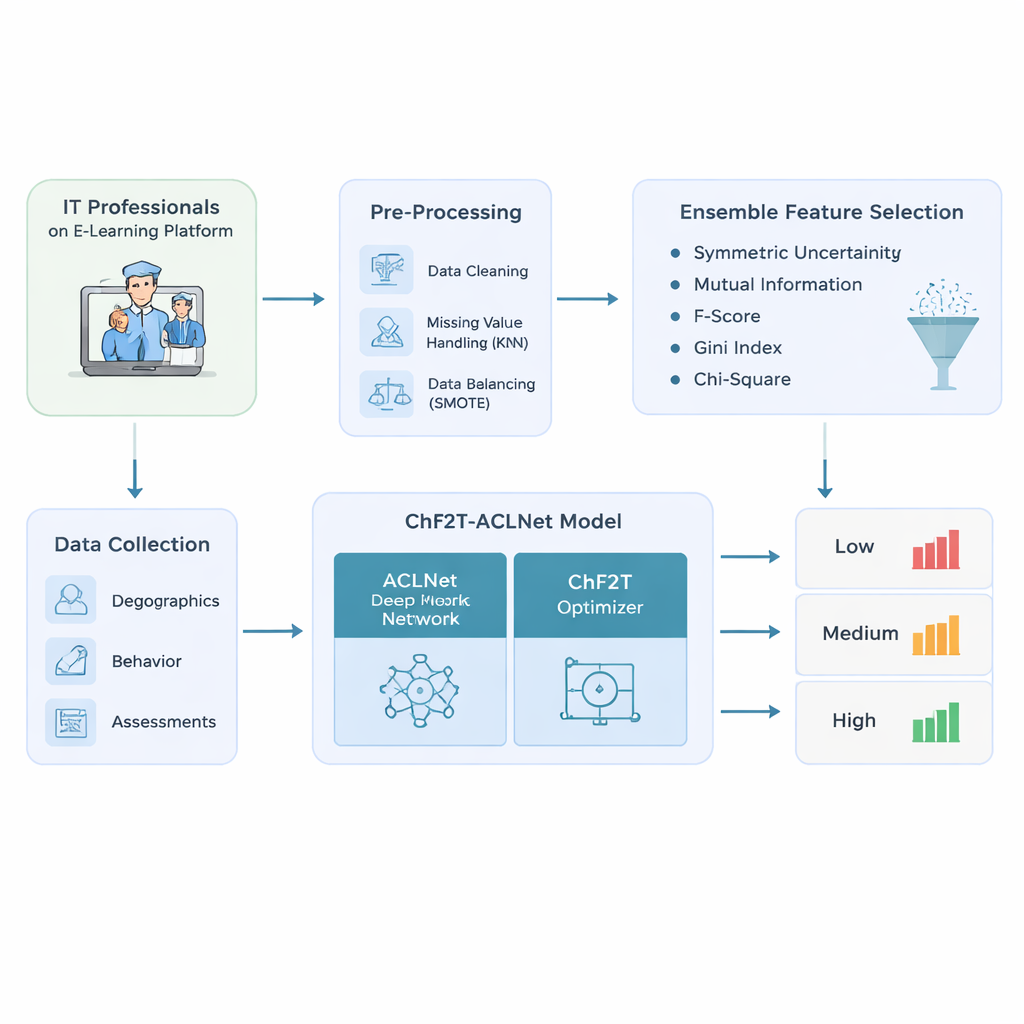
Los autores empiezan diseñando una canalización de datos cuidadosa para profesionales de TI que usan plataformas de e‑learning adaptativo. Recogen una mezcla rica de información: datos de perfil básicos como edad y puesto; rastros de comportamiento como tiempo dedicado, fechas de acceso y días activos; e indicadores de rendimiento que incluyen puntuaciones de cuestionarios, intentos, certificados y valoraciones de feedback. Antes de modelar, limpian los datos: eliminan registros duplicados, estiman valores faltantes observando alumnos similares y corrigen distribuciones de clases sesgadas para que los rendimientos bajos, medios y altos estén representados de forma más justa. Este paso de balance evita modelos que solo sean excesivamente confiados para los alumnos «medios» más comunes y ciegos ante quienes tienen dificultades o sobresalen.
Seleccionar solo las señales más reveladoras
Desde el conjunto de datos limpio, el sistema no se limita a introducir todas las columnas disponibles en una caja negra. En su lugar, utiliza un conjunto de cinco métodos simples de clasificación para decidir qué características importan realmente para predecir los resultados de aprendizaje. Cada método examina la conexión entre una característica candidata —como intentos en cuestionarios o tiempo dedicado— y la etiqueta final de rendimiento. Al combinar sus clasificaciones mediante una puntuación mediana, el enfoque filtra señales ruidosas o redundantes y conserva solo las más informativas. Esto no solo reduce la cantidad de cálculo que necesita el modelo posterior, sino que también le ayuda a centrarse en patrones que distinguen de forma significativa a los alumnos de bajo, medio y alto rendimiento.
Una red híbrida entrenada como un equipo deportivo
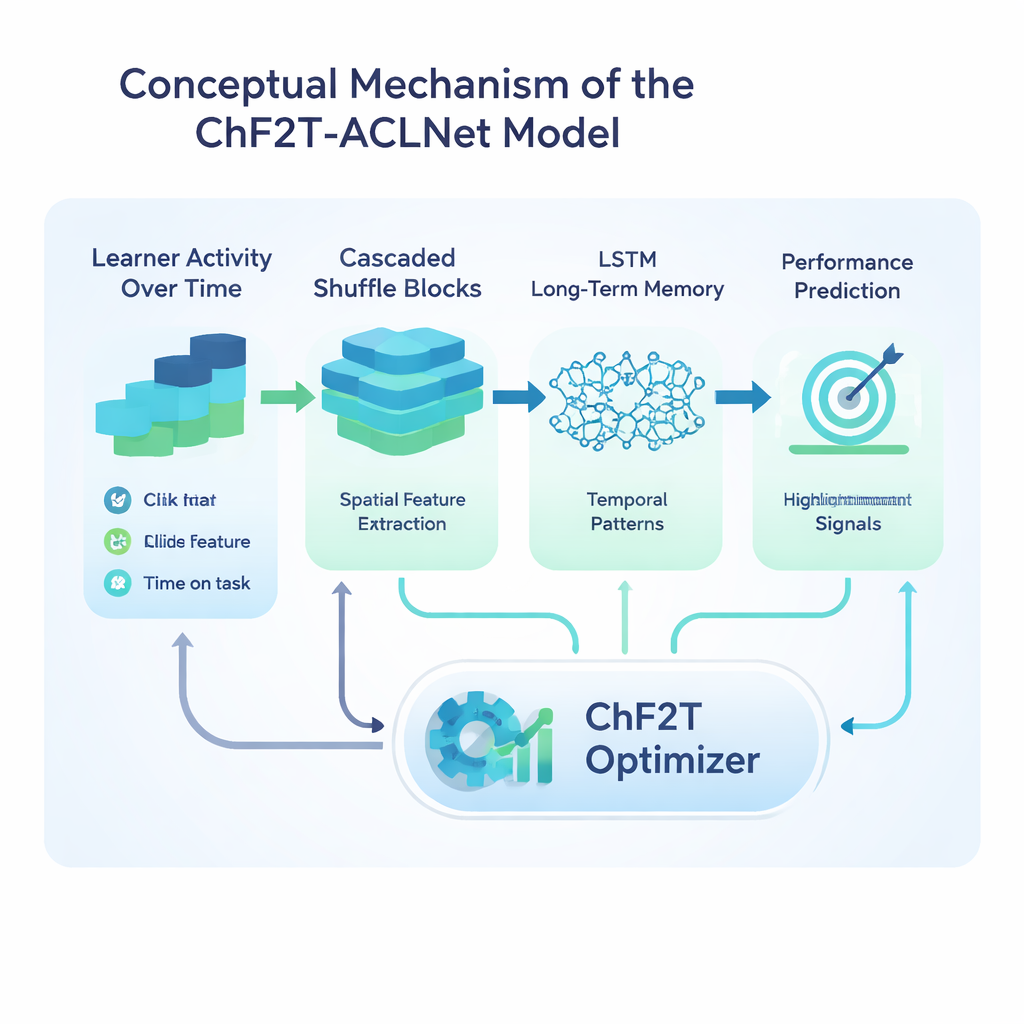
El núcleo del estudio es un modelo híbrido de aprendizaje profundo llamado ACLNet, acompañado de una estrategia de entrenamiento poco convencional inspirada en los deportes de equipo. ACLNet usa primero bloques ligeros de «shuffle» para comprimir y mezclar las señales de entrada de forma eficiente, y luego las envía a un módulo de memoria que rastrea cómo cambia el comportamiento del alumno a lo largo del tiempo. Una capa de atención en la parte superior destaca los canales más influyentes —como caídas bruscas en la actividad o puntuaciones de cuestionarios consistentemente altas— antes de emitir una predicción final sobre la clase de rendimiento del alumno. Para ajustar los numerosos parámetros internos de esta red, los autores introducen un algoritmo Chaotic Football Team Training (ChF2T). Aquí, «jugadores» virtuales exploran distintos ajustes de parámetros, imitando a los más eficaces, evitando a los débiles y realizando ocasionalmente saltos grandes y caóticos que ayudan a escapar de elecciones locales pobres. Esta mezcla de estructura y aleatoriedad controlada acelera la convergencia y reduce el sobreajuste.
Cómo funciona el sistema en la práctica
Los investigadores prueban su canalización con un conjunto de datos sintético pero realista de 1.200 profesionales de TI, construido para reflejar registros de sistemas de gestión de aprendizaje con distribuciones de clases deliberadamente desiguales. Comparan su modelo ChF2T‑ACLNet frente a varias líneas base sólidas, incluidos entornos de aprendizaje federado, redes avanzadas estilo imagen adaptadas a la educación y otros modelos profundos o en conjunto. En múltiples configuraciones de validación cruzada, el método propuesto alcanza alrededor de un 98,9% de exactitud, con precisiones, recalls y puntuaciones F igualmente altas. También logra una puntuación de acuerdo casi perfecta que corrige por azar y ofrece valores sólidos de área bajo la curva, lo que significa que separa niveles de rendimiento de forma fiable a través de muchos umbrales. A pesar de su complejidad, el sistema se ejecuta más rápido que enfoques competidores, gracias a la selección cuidadosa de características, un diseño de red eficiente y la rápida convergencia del optimizador.
Qué supone esto para el aprendizaje online diario
En términos sencillos, este trabajo demuestra que es posible observar cómo los profesionales avanzan en los cursos online e inferir, con alta confianza, quién está teniendo dificultades, quién está avanzando sin mayor esfuerzo y quién está dominando el material—sin esperar a un examen final. Un sistema así podría activar sugerencias tempranas, recomendar ejercicios distintos o alertar a mentores mucho antes de que un alumno se quede atrás. Los autores señalan desafíos pendientes, como escalar a plataformas muy grandes, adaptarse a diseños de curso que cambian rápido y hacer las decisiones del modelo más fáciles de explicar. Aun así, su enfoque supone un paso sólido hacia sistemas de e‑learning que actúen más como entrenadores personales atentos que como libros de texto digitales estáticos.
Cita: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Palabras clave: e‑learning adaptativo, analítica del aprendizaje, aprendizaje profundo, formación de profesionales de TI, predicción del rendimiento estudiantil