Clear Sky Science · es
Un método de desambiguación de entidades en textos breves basado en el modelo BERT y el algoritmo de camino más corto
Por qué es importante aclarar nombres confusos
Cada día buscamos, navegamos y chateamos usando fragmentos de texto cortos y a menudo desordenados—tuits, consultas de búsqueda, mensajes—que contienen nombres de personas, lugares, empresas y cosas que pueden tener más de un significado, como “Apple” la fruta o “Apple” la empresa. Los ordenadores deben adivinar qué sentido pretendemos y, cuando fallan, los resultados de búsqueda, las recomendaciones y los servicios online pierden mucha utilidad. Este artículo presenta una manera nueva de ayudar a las máquinas a interpretar correctamente esos nombres ambiguos en textos breves, especialmente en medios sociales y búsquedas en chino, combinando modelos de lenguaje modernos con un algoritmo de grafos ingenioso.
De textos breves y confusos a objetivos claros
Los textos breves son sorprendentemente difíciles de entender para las máquinas. A diferencia de los artículos largos, contienen muy poco contexto y están llenos de jerga, abreviaturas y frases incompletas. Los métodos tradicionales intentaban emparejar un nombre del texto con entradas de una base de conocimiento o usaban reglas hechas a mano y modelos de aprendizaje automático más simples. Estos enfoques a menudo tratan cada palabra como si tuviera un único significado fijo, lo que falla estrepitosamente cuando la misma palabra puede representar un puesto de trabajo, una empresa o una canción según el uso. El resultado son confusiones frecuentes sobre a qué entidad del mundo real se refiere una palabra en un tuit o una consulta.
Enseñar al sistema a detectar nombres ambiguos
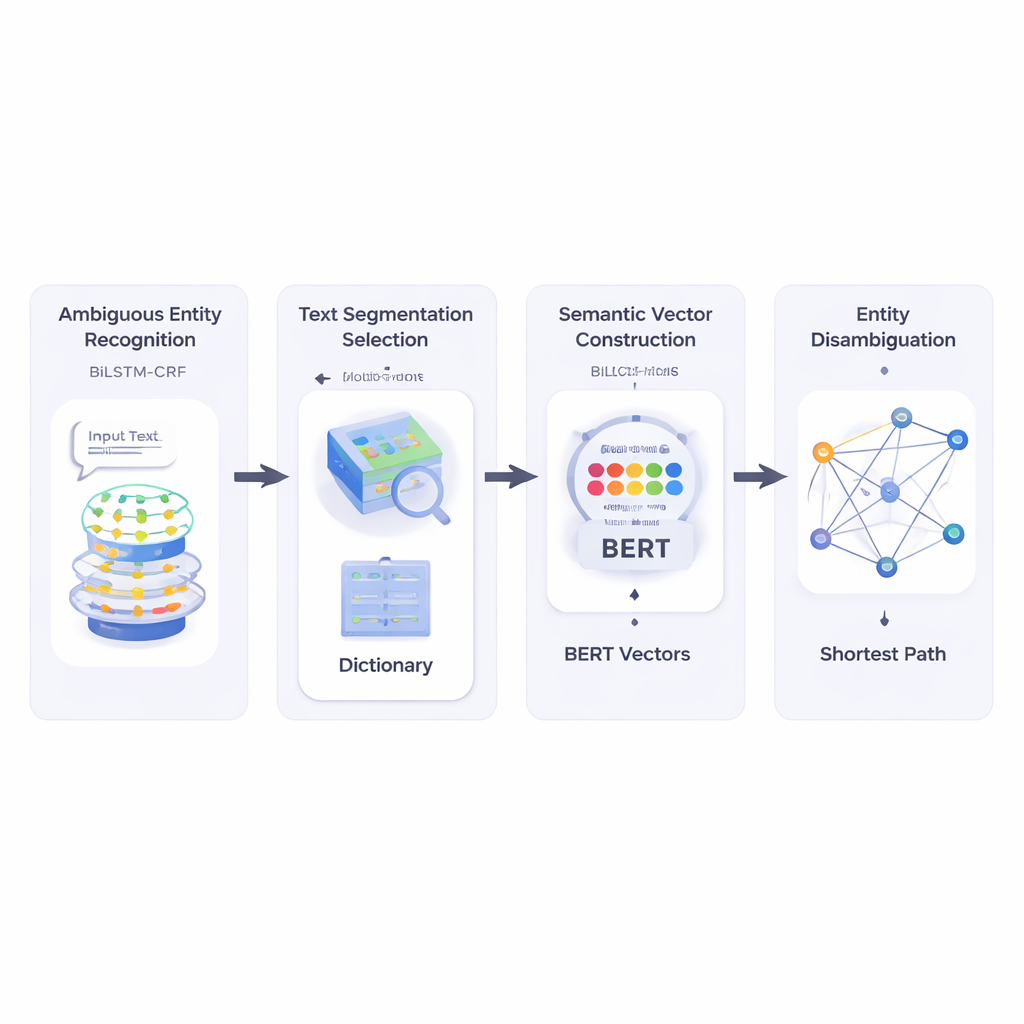
Los autores primero construyen un sistema que lee un texto breve e identifica qué partes son nombres de entidades y cuáles de ellas podrían ser ambiguas. Usan una combinación de redes neuronales llamada BiLSTM‑CRF, que es buena para etiquetar secuencias de palabras al mirar el contexto a la izquierda y a la derecha. Una vez marcadas las entidades potenciales, el sistema consulta un recurso léxico amplio llamado HowNet. Si HowNet lista varios sentidos para una palabra, esa palabra se marca como ambigua; si solo hay un sentido, la palabra se considera ya clara. Este paso proporciona al sistema una lista concentrada de nombres que realmente necesitan desambiguación.
Convertir significados en puntos en el espacio
A continuación, el método segmenta el texto breve en candidatos de fragmentos de palabras y elige la mejor segmentación comprobando qué tan bien cada posible corte se alinea, en significado, con palabras de referencia claramente entendidas en la misma oración. Para medir esto, los autores se apoyan en BERT, un potente modelo de lenguaje preentrenado que produce un “vector semántico” numérico para cada uso de una palabra, capturando su significado dependiente del contexto. Calculando la similitud del coseno entre estos vectores, el sistema encuentra la segmentación cuyas piezas son más compatibles semánticamente con los términos de referencia no ambiguos. Esto permite al modelo representar cada posible sentido de cada palabra como un punto en un espacio multidimensional.
Encontrar la ruta más corta hacia el sentido correcto
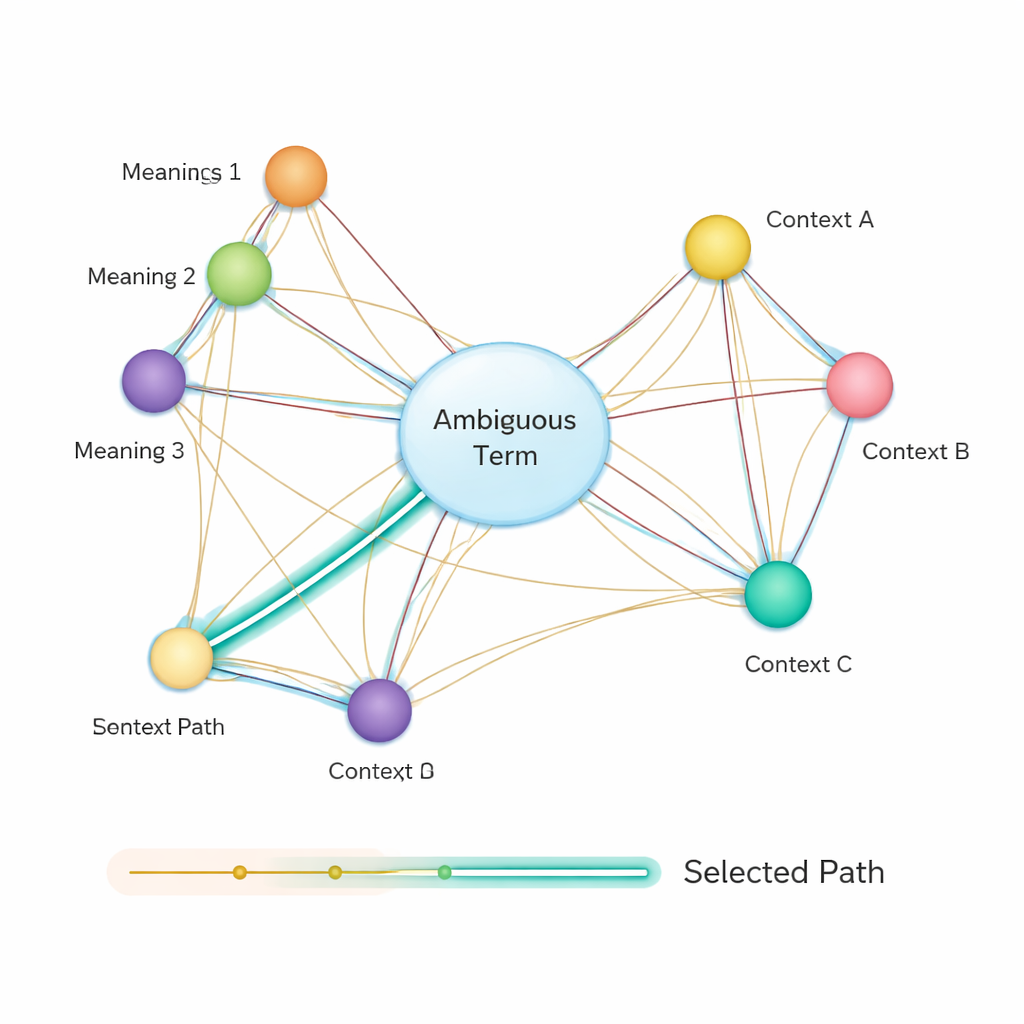
Después de eso, el método construye una red semántica: un grafo donde cada posible significado de cada término es un nodo, y las aristas conectan significados que podrían aparecer juntos en la misma oración. La fuerza de cada arista se basa en la similitud entre los significados, nuevamente usando vectores derivados de BERT. Para decidir qué sentido de una palabra ambigua encaja mejor en la oración, los autores aplican un algoritmo clásico conocido como el algoritmo de camino más corto de Dijkstra. Intuitivamente, el sistema busca el camino a través de este grafo de significados que mantenga la “distancia” semántica global lo más pequeña posible. El camino elegido corresponde a una interpretación consistente de todos los términos, y el sentido de la entidad ambigua que se encuentra en ese camino se selecciona como la respuesta final.
¿Cuánto mejora esto?
Los investigadores probaron su método en un conjunto de datos público en chino del benchmark CLUE, que simula escenarios reales de textos breves como publicaciones en redes sociales y consultas. Compararon cuatro enfoques: versiones que usan incrustaciones Word2Vec tradicionales, el modelo de lenguaje ELMo, un sistema basado en BERT sin el paso de camino más corto y su canal completo BiLSTM‑CRF‑BERT‑SPA. A lo largo de miles de textos, su método completo mejoró la precisión, la recall y la puntuación F1 en aproximadamente una cuarta parte de media en comparación con los otros. En términos prácticos, el sistema fue mejor tanto en identificar las entidades correctas como en hacerlo de forma consistente a través de distintos tamaños de datos.
Qué significa esto para la tecnología cotidiana
Para el público general, la conclusión es sencilla: al combinar un potente modelo de comprensión del lenguaje (BERT) con una búsqueda de camino más corto basada en grafos, los autores ofrecen a las máquinas una forma más fiable de decidir a qué se refiere realmente un nombre ambiguo en textos breves y ruidosos. Esto puede hacer que los motores de búsqueda sean más inteligentes, ayudar a las plataformas sociales a entender mejor las publicaciones y mejorar herramientas posteriores como sistemas de recomendación y grafos de conocimiento. Aunque el método está actualmente orientado al chino y todavía tiene margen de mejora en eficiencia, demuestra cómo la mezcla de IA moderna con algoritmos clásicos puede reducir drásticamente la confusión en la interpretación que las máquinas hacen de nuestro lenguaje cotidiano.
Cita: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Palabras clave: desambiguación de entidades, texto breve, BERT, grafo de conocimiento, procesamiento del lenguaje natural