Clear Sky Science · es
Marco de aprendizaje por refuerzo para pruebas adaptativas informatizadas usando un enfoque de multi-armed bandit
Pruebas más inteligentes para el aula digital
Quien haya pasado por un examen largo y único para todos sabe lo aburrido e injusto que puede resultar. Algunas preguntas son demasiado fáciles, otras imposibles, y la puntuación final puede no reflejar realmente lo que sabes. Este artículo presenta una nueva forma de diseñar pruebas por ordenador que se adaptan, en tiempo real, a las respuestas de cada persona. Tomando ideas de la inteligencia artificial moderna, los autores buscan que los exámenes sean más breves, más precisos y mejor ajustados a la verdadera habilidad de cada examinando.
Por qué las pruebas fijas se quedan cortas
Los exámenes tradicionales proponen a todos los estudiantes la misma colección de preguntas. Eso facilita la creación de pruebas, pero desperdicia información: los estudiantes fuertes se ven obligados a responder muchos ítems fáciles mientras que los que tienen dificultades se abruman rápidamente. Las pruebas adaptativas informatizadas intentan solucionar esto eligiendo cada pregunta según las respuestas previas, pero la mayoría de los sistemas actuales aún se apoyan en modelos estadísticos de hace décadas y en reglas hechas a mano. Estos enfoques antiguos tienen problemas para capturar patrones de respuesta complejos y, a menudo, no logran abarcar completamente la gran diversidad de aprendices en entornos grandes y en línea modernos.
Incorporando la IA moderna a la evaluación
Los autores proponen un nuevo marco que combina aprendizaje profundo y aprendizaje por refuerzo para guiar las pruebas adaptativas de principio a fin. El sistema opera en ciclos repetidos. Primero, una red neuronal convolucional unidimensional (1D-CNN) analiza las respuestas recientes de la persona, la dificultad de las preguntas y otras estadísticas resumidas. A partir de ese flujo de datos produce un único número que representa el nivel de habilidad actual de la persona en una escala normalizada, similar a cómo las teorías tradicionales de evaluación describen la habilidad, pero aprendida directamente de los datos. Esta red se entrena para reconocer patrones sutiles, como el éxito consistente en preguntas más difíciles o errores inesperados en las más fáciles. 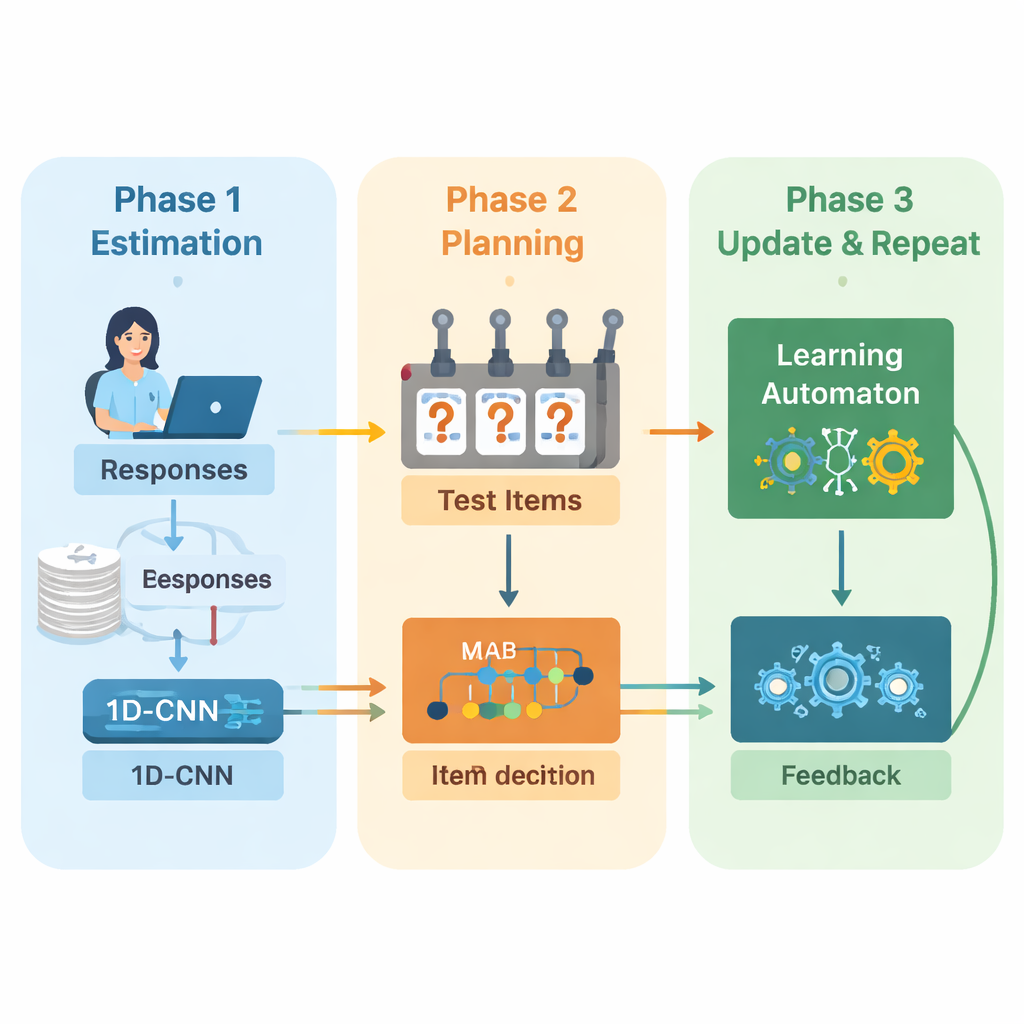
Elegir la siguiente pregunta adecuada
Una vez que el sistema tiene una estimación actualizada de la habilidad, debe decidir qué preguntar a continuación. Aquí los autores emplean una estrategia de "multi-armed bandit" (banda multi-brazo), una herramienta clásica de la teoría de la decisión donde cada acción posible se trata como tirar de una palanca en una tragaperras. En este contexto, cada pregunta del banco de ítems es un brazo. El algoritmo examina preguntas cuya dificultad coincide aproximadamente con la estimación de habilidad actual y luego selecciona las que se esperan más informativas. Equilibra dos objetivos: lograr un buen ajuste de dificultad, para que las respuestas no sean ni demasiado fáciles ni demasiado difíciles, y cubrir la mayor cantidad posible de áreas de contenido, para que la prueba no ignore temas importantes. Una puntuación de recompensa que mezcla estos dos objetivos guía el proceso de selección.
Aprender de sus propias decisiones
Para seguir mejorando a medida que avanza la prueba, el sistema añade otro componente de aprendizaje llamado autómata de aprendizaje. Este módulo observa cómo cambia la habilidad estimada a lo largo de las rondas y si la precisión de la persona mejora o empeora. Ajusta un pequeño conjunto de probabilidades que resumen si el modelo espera que la habilidad suba, se mantenga o baje. Estas probabilidades se retroalimentan como entrada adicional a la red neuronal en la siguiente ronda. De este modo, el motor de la prueba no solo aprende sobre el estudiante, sino también sobre sus propias decisiones pasadas: recompensa las tendencias que llevaron a estimaciones precisas y penaliza las que no lo hicieron. 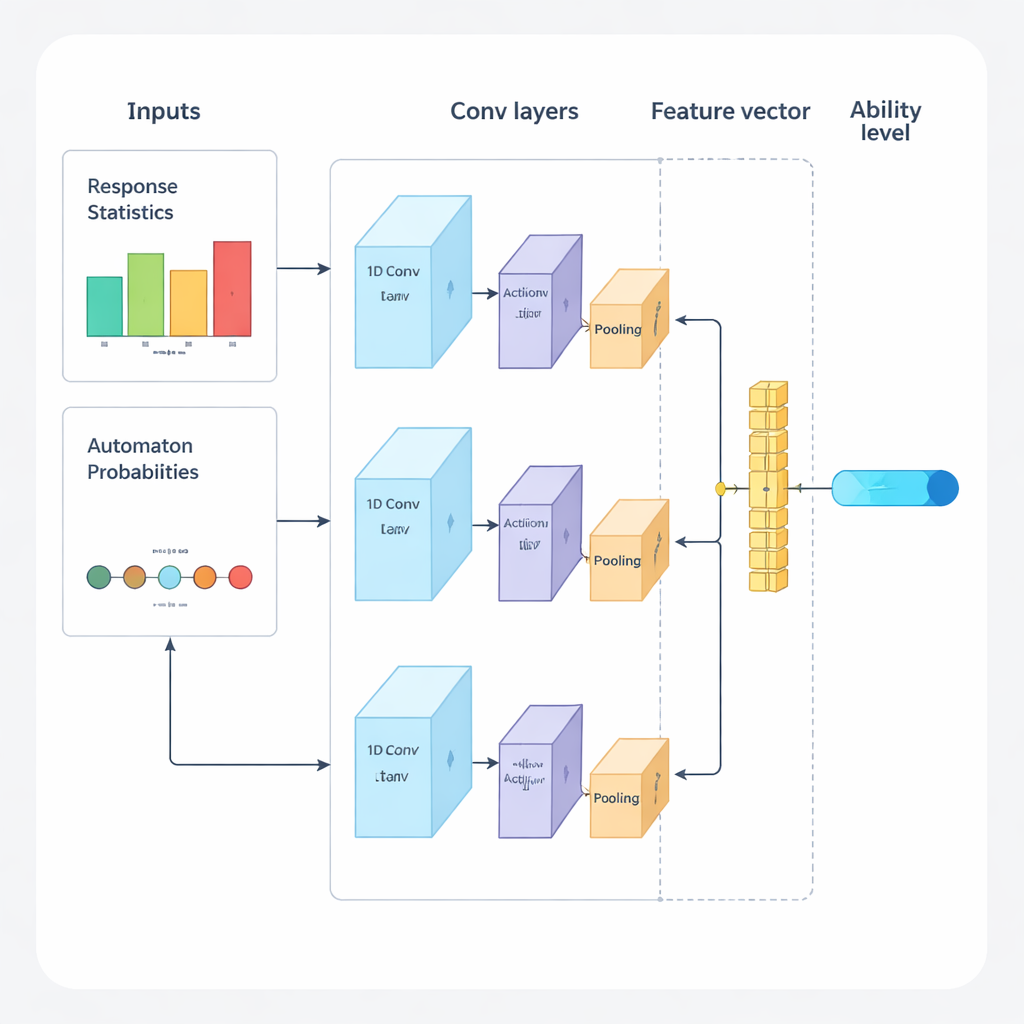
¿Qué tan bien funciona en la práctica?
Los investigadores evaluaron su marco usando un extenso conjunto de datos multilingüe de exámenes y miles de examinandos simulados cuyos niveles reales de habilidad eran conocidos. Compararon su enfoque con varios métodos líderes de pruebas adaptativas. En una variedad de medidas de error y correlación, el nuevo sistema produjo estimaciones de habilidad más precisas mientras requería menos preguntas. Sus errores—medidos por estadísticas comunes como el error cuadrático medio y el error absoluto medio—fueron claramente menores que los de los métodos competidores. Al mismo tiempo, distribuyó el uso de las preguntas de forma más uniforme por el banco de ítems, reduciendo el riesgo de que ciertas preguntas se expongan en exceso y se filtren.
Qué significa esto para los exámenes futuros
En términos sencillos, este trabajo sugiere que las futuras pruebas informatizadas podrían sentirse más como una sesión de tutoría a medida que como un examen rígido. Las preguntas se ajustarían rápidamente a la dificultad adecuada para cada persona, explorarían el abanico completo de temas relevantes y terminarían cuando el sistema tenga confianza en tu nivel—frecuentemente con menos ítems que las pruebas actuales. Aunque el método aún depende de buenos datos de entrenamiento y de capacidad de cómputo, y hasta ahora se ha probado en un único conjunto de datos, apunta hacia una nueva generación de evaluaciones más inteligentes, más justas y más eficientes que se adaptan de forma natural a los aprendices individuales.
Cita: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Palabras clave: pruebas adaptativas informatizadas, evaluación educativa, aprendizaje profundo, aprendizaje por refuerzo, banda multi-brazo