Clear Sky Science · es
Un modelo de sentimiento profundo que combina contexto impulsado por ALBERT y arquitectura optimizada por EHO
Por qué importa leer el sentimiento con más inteligencia
Cada día, millones de personas comparten opiniones sobre productos, servicios, política y eventos en Internet. Convertir este flujo de texto en información fiable es vital para empresas, gobiernos e investigadores. Sin embargo, nuestro lenguaje en línea es desordenado: las bromas sarcásticas, la jerga, los errores tipográficos y las emociones poco frecuentes pueden confundir con facilidad a los ordenadores. Este artículo presenta un nuevo sistema de análisis de sentimiento que pretende leer estas emociones con mayor precisión, empleando a la vez menos potencia de cálculo que muchos modelos de inteligencia artificial actuales.
De simples conteos de palabras a una lectura consciente del contexto
Las herramientas tempranas de análisis de sentimiento trataban el texto como una bolsa de palabras desconectadas, contando con qué frecuencia aparecían términos como “bueno” o “terrible”. Este enfoque ignoraba el orden de las palabras y el contexto sutil, como cuando “no está mal” significa algo más cercano a “bastante bien”. Los métodos de aprendizaje profundo mejoraron esto procesando el texto en secuencias, pero a menudo requerían grandes conjuntos de datos etiquetados y un gran coste computacional. Modelos transformadores como BERT aumentaron aún más la precisión, pero su gran tamaño los hace caros de ejecutar en entornos reales como plataformas de atención al cliente o sistemas de monitorización de redes sociales. Los autores de este artículo responden a ese reto combinando varios componentes más ligeros pero potentes en un único sistema optimizado.
Un cerebro más ligero para entender el texto
En el núcleo del modelo está ALBERT, un primo compacto del modelo de lenguaje BERT. ALBERT convierte cada palabra de una oración en una representación numérica consciente del contexto, captando cómo cambian los significados en función de las palabras vecinas. A diferencia de los modelos más grandes, ALBERT reduce el uso de memoria compartiendo parámetros entre capas y comprimiendo su vocabulario de palabras. Esto facilita su ejecución en hardware estándar sin sacrificar mucho nivel de comprensión. Estas representaciones basadas en ALBERT se convierten en la entrada a una secuencia de capas especializadas que se centran en cómo se despliega el sentimiento a lo largo de una oración.
Poner a trabajar juntos dos sistemas de memoria
Para seguir cómo cambia el significado de palabra a palabra, el sistema utiliza dos tipos de redes recurrentes: GRU (Gated Recurrent Units) y LSTM (Long Short-Term Memory), cada una ejecutada en direcciones hacia adelante y hacia atrás. Las GRU son eficaces para seguir frases cortas con menos parámetros, mientras que las LSTM son mejores para recordar información a lo largo de tramos de texto más largos. Al apilar una capa GRU bidireccional encima de una capa LSTM bidireccional y añadir un mecanismo de atención, el modelo puede resaltar las partes de cada oración con mayor carga sentimental —por ejemplo, la frase “excepto la duración de la batería” en una reseña por lo demás positiva. Este diseño híbrido busca capturar tanto los cambios rápidos de tono como el contexto de más largo alcance que puede invertir el sentimiento general.
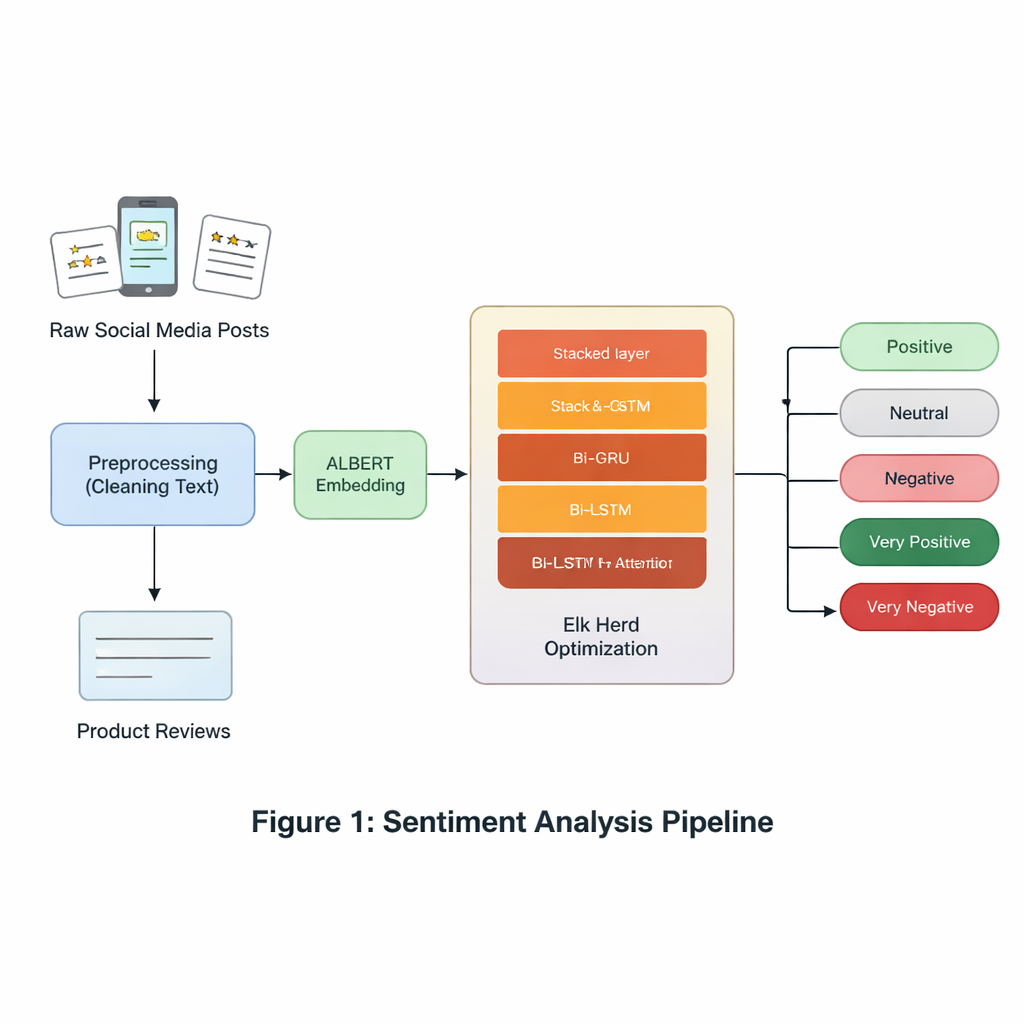
Ajuste inspirado en la naturaleza para casos difíciles
Más allá de la arquitectura, los autores abordan un obstáculo clave del mundo real: los conjuntos de datos de sentimiento suelen estar desequilibrados y ruidosos. Emociones como el asco o la sorpresa, y las declaraciones neutrales, aparecen con menos frecuencia que las claramente positivas o negativas, lo que hace que muchos modelos las ignoren. Para contrarrestarlo, el artículo emplea Elk Herd Optimization, una estrategia de búsqueda inspirada en la naturaleza modelada en cómo se mueven, compiten y forman grupos los alces. Tras producir vectores internos de sentimiento mediante la red neuronal, este paso de optimización ajusta con precisión cómo estos vectores representan cada clase, especialmente las raras, mejorando iterativamente una puntuación de “fitness”. Este proceso ayuda al modelo a evitar soluciones superficiales y mejora su capacidad para distinguir emociones sutiles o poco representadas.
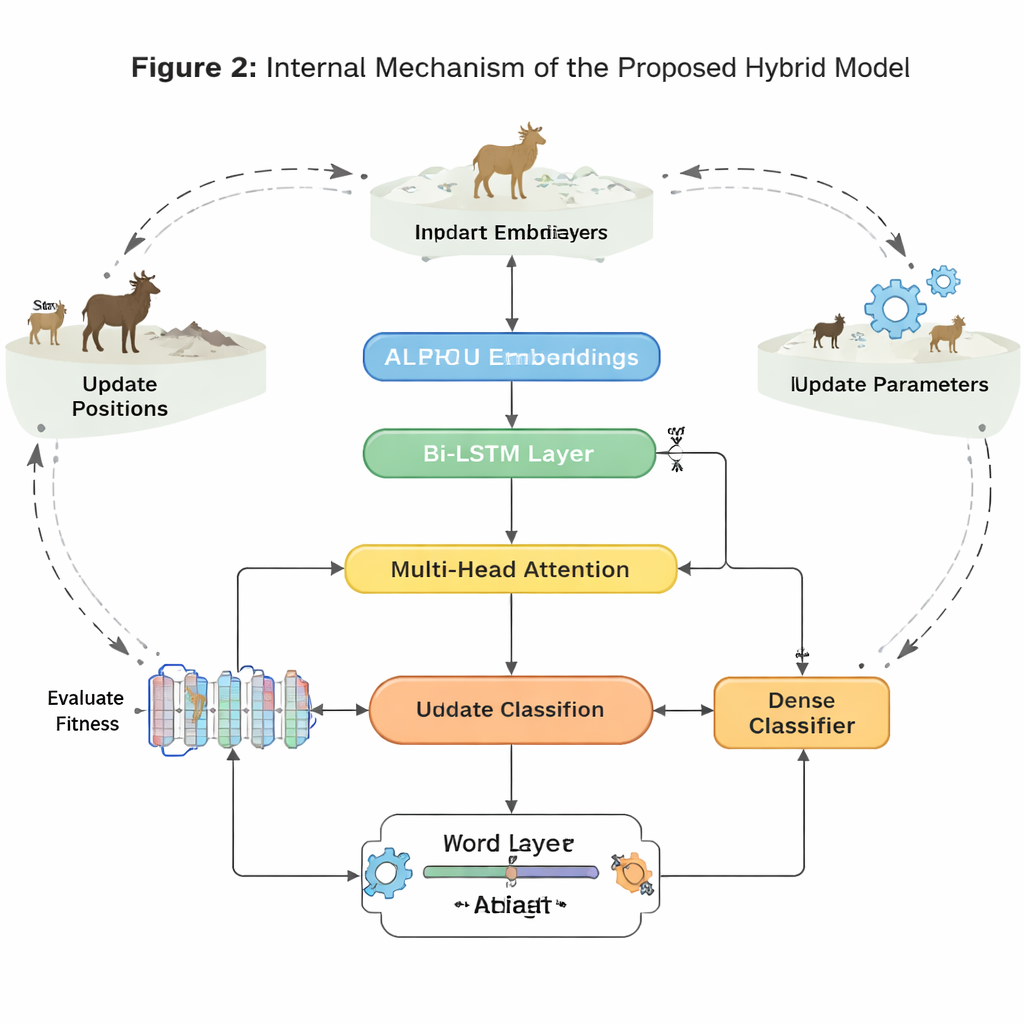
Poniendo el modelo a prueba
Los autores evalúan su sistema en seis conjuntos de datos de uso extendido, incluidos mensajes de Twitter, reseñas de restaurantes y portátiles, y un banco de pruebas de reseñas de películas con cinco niveles que distingue opiniones muy positivas y muy negativas de las más moderadas. A lo largo de estas fuentes variadas, el nuevo enfoque supera de forma consistente a varios competidores avanzados basados en grafos y transformadores tanto en precisión como en la puntuación F1, una métrica que equilibra aciertos correctos y casos perdidos. Las ganancias son especialmente fuertes en la tarea de reseñas de películas de cinco clases y en las clases de sentimiento subrepresentadas, lo que muestra que el método puede manejar tanto emociones finas como datos desequilibrados. Un estudio de ablación, en el que se eliminan componentes uno a uno, confirma que ALBERT, el diseño combinado GRU–LSTM, la atención y la optimización inspirada en los alces contribuyen cada uno al rendimiento general.
Qué significa esto para las aplicaciones cotidianas
Para los no especialistas, la idea principal es que esta investigación ofrece una forma más eficiente y fiable de interpretar grandes volúmenes de opinión en línea. Al combinar un modelo de lenguaje compacto con capas de memoria complementarias y un paso de ajuste inspirado biológicamente, el sistema lee entre líneas con mayor precisión, especialmente cuando los sentimientos son sutiles o los datos están sesgados. Esto lo hace prometedor para usos en el mundo real como el seguimiento de la satisfacción del cliente, la monitorización de actitudes de salud pública o la evaluación de reacciones a políticas y eventos, donde importan tanto la precisión como el coste computacional.
Cita: Oqaibi, H., Sharma, S. A deep sentiment model combining ALBERT-driven context and EHO-optimized architecture. Sci Rep 16, 5784 (2026). https://doi.org/10.1038/s41598-026-36389-2
Palabras clave: análisis de sentimiento, ALBERT, aprendizaje profundo, clasificación de texto, optimización metaheurística