Clear Sky Science · es
Identificación de factores de riesgo en instalaciones recreativas a gran escala mediante mezcla de expertos y fusión de múltiples modelos
Por qué la seguridad de los parques temáticos necesita una lectura más inteligente
Cada año, cientos de millones de personas suben a montañas rusas, torres de caída y atracciones giratorias, confiando en que máquinas complejas y operadores ocupados les mantendrán a salvo. Tras bambalinas, reguladores e ingenieros generan enormes volúmenes de informes, registros de accidentes y quejas públicas, pero la mayor parte de esta información está en forma de texto y resulta difícil de revisar rápidamente. Este estudio explora cómo la inteligencia artificial avanzada puede "leer" estos documentos a escala, detectar patrones de peligro con antelación y ofrecer a las autoridades una imagen más clara de dónde es más probable que fallen las atracciones.
De informes dispersos a un panorama unificado del riesgo
China alberga ahora más de 25.000 grandes atracciones y más de 700 millones de visitantes al año. A pesar de las mejoras generales en seguridad, siguen ocurriendo accidentes raros pero graves, a menudo después de que las inspecciones no hayan detectado señales de advertencia tempranas ocultas en descripciones técnicas o quejas de usuarios. Los autores sostienen que la supervisión tradicional—basada en comprobaciones periódicas manuales, el juicio de expertos y los registros de mantenimiento—es demasiado lenta y subjetiva para un entorno tan dinámico. Reúnen una gran colección de textos del mundo real que incluye informes de accidentes, leyes y normas, registros de inspección y mantenimiento, y quejas en línea relacionadas con instalaciones recreativas. Tras una limpieza y filtrado cuidadosos, este corpus multisource se convierte en la materia prima para un sistema automatizado de monitorización de riesgos basado en datos. 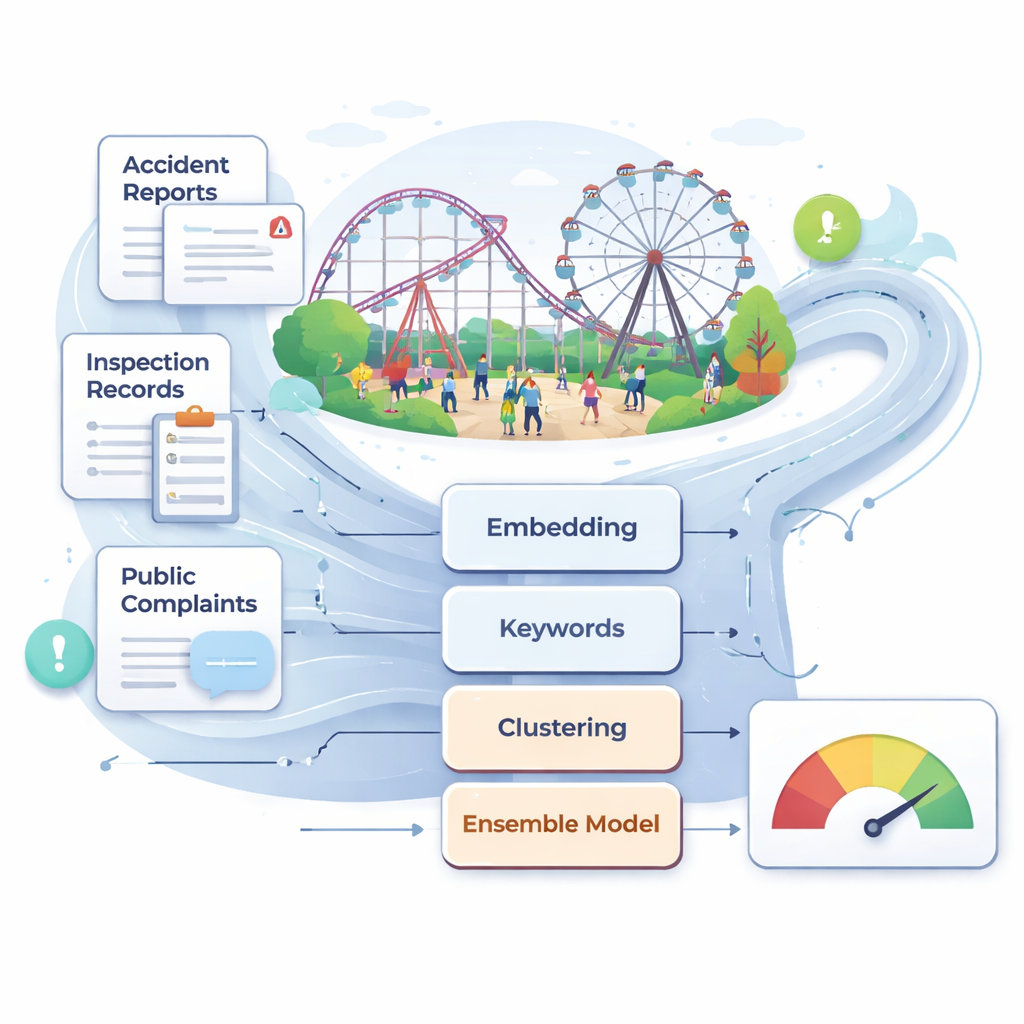
Enseñar a los ordenadores a entender el lenguaje del riesgo
Para dar sentido a estos textos desordenados, los investigadores se apoyan en modelos de lenguaje modernos que convierten oraciones en vectores numéricos que capturan su significado. Utilizan principalmente un modelo chino llamado BGE, que representa cada fragmento de texto como un punto de 1.024 dimensiones en el espacio, además de un conjunto compacto de 30 características basadas en palabras clave centradas en términos como «mantenimiento», «inspección» y «rectificación». Esta vista dual—contexto semántico profundo más frases de riesgo seleccionadas manualmente—ayuda al sistema a distinguir diferencias sutiles entre, por ejemplo, comprobaciones rutinarias y fallos graves. El equipo también experimenta con otro modelo de incrustación de última generación, Qwen3, para comprobar si cambiar la columna vertebral lingüística mejora el rendimiento; en la práctica, BGE demuestra ser ligeramente mejor en esta tarea de seguridad.
Encontrar patrones ocultos y puntos débiles clave
Antes de clasificar los textos en categorías concretas de riesgo, los autores usan métodos no supervisados para descubrir agrupaciones naturales. Aplican k-means a las incrustaciones y usan un método de visualización llamado UMAP para mostrar que los informes caen en varios clústeres temáticos claros. Luego construyen un grafo semántico en el que cada nodo es una palabra clave relacionada con la seguridad y los enlaces indican fuerte coocurrencia y similitud semántica. Un algoritmo de detección de comunidades agrupa estos nodos en clústeres que corresponden a temas amplios como seguridad del equipo y estructural, operación y mantenimiento diarios, respuesta a emergencias, y gestión y supervisión. Dentro de esta red, ciertas palabras—como «mantenimiento», «inspección» y «responsabilidad»—actúan como puentes entre clústeres, destacando debilidades transversales que pueden desencadenar accidentes de múltiples formas. A partir de esta estructura extraen 31 factores de riesgo nucleares que abarcan cuatro dimensiones principales, desde la monitorización en tiempo real del equipo hasta la claridad de las responsabilidades laborales. 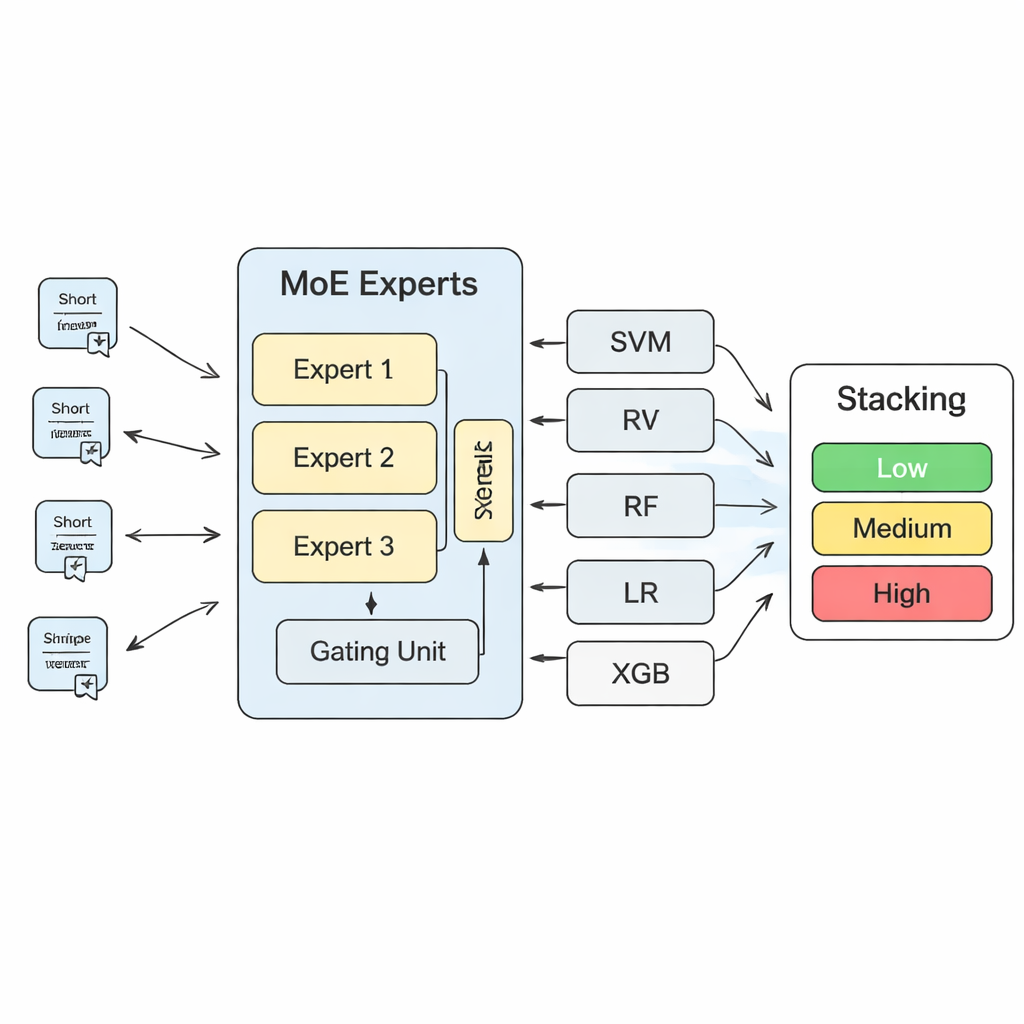
Combinar muchos modelos en un juez de seguridad más potente
Para convertir estos conocimientos en predicciones de riesgo concretas, el estudio construye un sistema de aprendizaje automático en capas. En su núcleo hay un modelo de "mezcla de expertos" (MoE): varias redes neuronales, o expertos, aprenden a especializarse en distintos tipos de patrones de riesgo, mientras que un componente de enrutamiento decide en cuál de los expertos confiar más para cada nuevo texto. Las salidas de este modelo MoE se combinan luego con las predicciones de algoritmos más tradicionales, como máquinas de vectores de soporte, bosques aleatorios, regresión logística y árboles potenciados por gradiente. Una capa final de "Stacking"—otro modelo de aprendizaje automático—aprende a ponderar todas estas opiniones para llegar a una decisión final. Mediante una validación cruzada extensa, los autores concluyen que usar tres expertos en la capa MoE logra el mejor equilibrio entre capacidad del modelo y estabilidad.
Qué significan las mejoras para la supervisión en el mundo real
En comparación con cualquier modelo individual, el sistema MoE más Stacking mejora sustancialmente la precisión, la exactitud, el recall y una medida de fiabilidad llamada LogLoss. En términos prácticos, esto se traduce en menos advertencias perdidas y menos falsas alarmas al filtrar grandes volúmenes de texto sobre seguridad. El modelo puede ejecutarse en un equipo de trabajo ordinario y ofrecer evaluaciones rápidas de riesgo para nuevos informes de inspección o quejas, por lo que es adecuado como herramienta de apoyo a la decisión y no como reemplazo del juicio humano. Los autores subrayan que su enfoque podría adaptarse más allá de las atracciones recreativas a otros equipos especiales como ascensores o teleféricos. Para el lector general, la conclusión clave es que al enseñar a los ordenadores a leer el lenguaje de la seguridad—a través de documentos técnicos, normativas y quejas cotidianas—los reguladores pueden detectar patrones de peligro antes, dirigir las inspecciones con más inteligencia y hacer que un día en el parque sea un poco más seguro para todos.
Cita: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Palabras clave: seguridad de atracciones, análisis de texto de riesgo, aprendizaje automático, mezcla de expertos, vigilancia de la seguridad pública