Clear Sky Science · es
Red neuronal profunda Inception con conexiones residuales para el reconocimiento de caracteres manuscritos en tamil
Salvar la escritura a mano en la era digital
Desde antiguos manuscritos en hojas de palma hasta anotaciones cotidianas, gran parte del patrimonio escrito en tamil aún vive en papel. Convertir esta rica colección de páginas manuscritas en texto digital y indexable es esencial para preservar la cultura, apoyar la educación y desarrollar mejores tecnologías lingüísticas. Este artículo presenta un nuevo sistema de visión por ordenador, llamado TamHNet, que lee escritura a mano en tamil con una precisión casi perfecta, incluso cuando las letras se parecen confusamente entre sí.
Por qué las letras tamil son difíciles para las máquinas
El tamil lo hablan más de 80 millones de personas y utiliza una escritura con 247 caracteres, que incluye vocales, consonantes y numerosas combinaciones de ambos. Muchas letras se diferencian solo por pequeños remates o trazos adicionales, y los escritores varían mucho en la forma de trazar cada carácter. Parejas como எ/ஏ u ஒ/ஓ pueden parecer casi idénticas a simple vista, y caracteres como ல y வ se confunden con facilidad. Programas informáticos anteriores e incluso sistemas modernos de aprendizaje automático a menudo tenían problemas con estas sutilezas, lo que provocaba palabras mal leídas y una digitalización poco fiable de los documentos.
Construir un conjunto de datos de escritura real
Para entrenar y evaluar su sistema en condiciones realistas, los investigadores crearon un nuevo Conjunto de Caracteres Aislados en Tamil utilizando muestras manuscritas de 1.000 estudiantes universitarios. En lugar de depender de imágenes sintéticas o generadas por ordenador, recopilaron caracteres auténticos trazados con pluma sobre papel que cubren 12 vocales, 18 consonantes y 214 combinaciones comunes. El equipo etiquetó cuidadosamente estas muestras y puso el conjunto de datos a disposición pública para que otros grupos puedan comparar métodos y avanzar sobre este trabajo. Al organizar la escritura en 104 símbolos base que abarcan los 247 caracteres, redujeron la redundancia sin dejar de representar la gama completa de formas que aparecen en la escritura real.
Limpiar, deformar y enseñar las imágenes
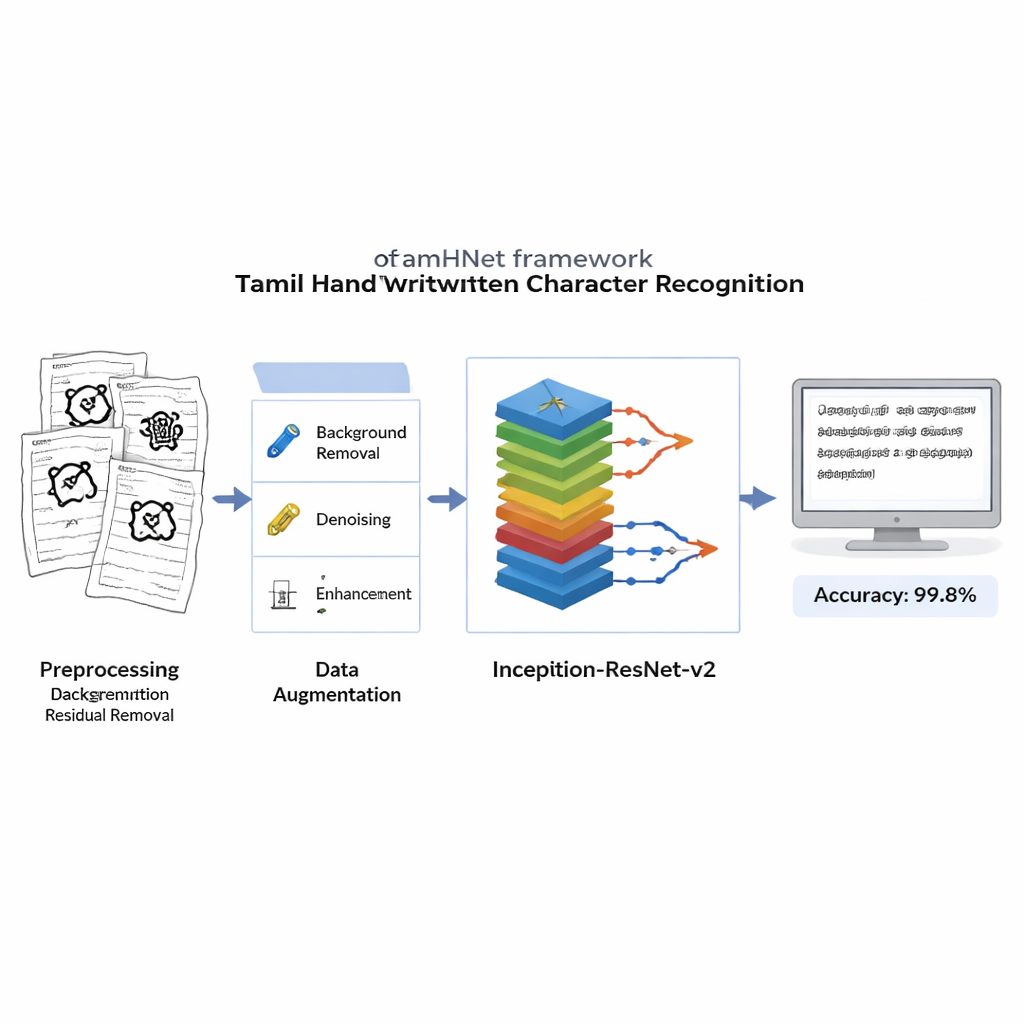
Antes de cualquier aprendizaje, cada imagen escaneada se limpia para eliminar fondos ruidosos, manchas y una iluminación desigual, preservando al mismo tiempo los trazos delicados que definen cada letra. Las imágenes se convierten a blanco y negro nítido y se redimensionan a un formato estándar para que el ordenador vea cada ejemplo de la misma manera. Para hacer el sistema robusto frente a distintos estilos de escritura, los autores aplican luego distorsiones controladas: desplazan ligeramente puntos clave en la imagen y aplican deformaciones suaves, generando nuevas versiones de cada carácter que siguen pareciendo la misma letra para un humano. Este conjunto de entrenamiento ampliado ayuda al modelo a reconocer caracteres incluso cuando están inclinados, comprimidos o escritos con proporciones inusuales.
Una red profunda que aprende diferencias sutiles
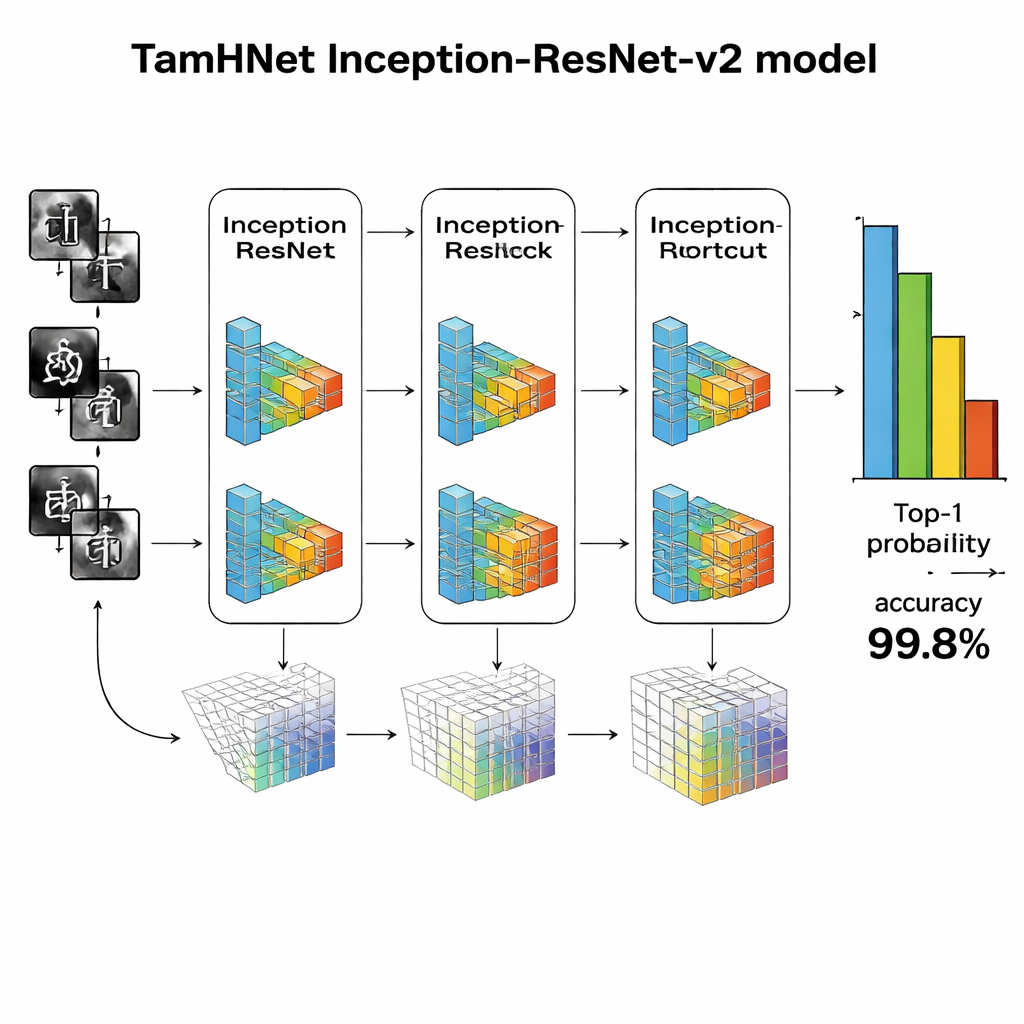
En el núcleo de TamHNet hay una potente arquitectura de aprendizaje profundo llamada Inception-ResNet-v2, diseñada originalmente para el reconocimiento general de objetos. Los autores adaptan y afinan esta red específicamente para la escritura a mano en tamil. El modelo procesa cada imagen a través de muchas capas que transforman gradualmente los píxeles crudos en patrones de nivel superior, como bordes, curvas y partes de caracteres. Conexiones directas especiales, conocidas como enlaces residuales, estabilizan el entrenamiento y ayudan a la red a centrarse en diferencias pequeñas pero cruciales entre letras similares. En lugar de ajustar todos los parámetros internos a la vez, el equipo “descongela” selectivamente las capas más útiles y las ajusta para esta tarea. Usan una técnica de optimización llamada Adam, que adapta automáticamente la velocidad de aprendizaje de cada parámetro, lo que permite que la red aprenda de forma eficiente a partir de una caligrafía compleja y a veces desordenada.
Qué tan bien lee el sistema la escritura
Los investigadores evalúan TamHNet en el nuevo conjunto de datos usando medidas estándar de calidad de reconocimiento. El sistema alcanza alrededor del 99,8 % de precisión en 104 clases de caracteres, superando a una amplia gama de métodos anteriores basados en máquinas de vectores de soporte, redes convolucionales tradicionales y otros diseños avanzados de aprendizaje profundo. Pruebas detalladas muestran que incluso letras con formas extremadamente similares se distinguen correctamente en la mayoría de los casos, y las curvas estadísticas confirman que el modelo rara vez confunde un carácter con otro. En comparación con trabajos previos, esto representa un avance claro en fiabilidad para el reconocimiento de caracteres manuscritos en tamil.
Qué significa esto para lectores y archivos
Para el público general, la conclusión principal es que las máquinas están mejorando drásticamente en la lectura de la escritura a mano en tamil. Un sistema como TamHNet puede impulsar herramientas que conviertan pilas de cuadernos, manuscritos históricos y formularios manuscritos en texto digital buscable con una corrección humana mínima. Aunque el modelo actual aún no maneja ciertos símbolos basados en puntos ni variantes antiguas del guion, los autores describen planes para extenderlo a estilos de escritura antiguos. En términos prácticos, esta investigación nos acerca a la digitalización precisa y a gran escala de documentos en tamil, ayudando a salvaguardar el patrimonio cultural y facilitando el acceso al conocimiento escrito para las generaciones futuras.
Cita: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Palabras clave: reconocimiento de caracteres manuscritos en tamil, reconocimiento óptico de caracteres, aprendizaje profundo, Inception-ResNet, preservación digital