Clear Sky Science · es
Preentrenamiento contrastivo imagen‑lenguaje guiado por objetos para reconocimiento de objetos inéditos
Ojos más inteligentes para cielos y mares concurridos
Los sistemas modernos de seguridad y respuesta ante desastres dependen de cámaras en el cielo y en el mar para detectar aeronaves, embarcaciones y otros objetos críticos. Pero enseñar a los ordenadores a distinguir un caza de un avión de pasajeros, o un buque de guerra de un carguero, resulta sorprendentemente difícil cuando las escenas están saturadas, los datos son escasos y aparecen continuamente nuevos modelos de equipo. Este artículo presenta OG‑CLIP, un nuevo sistema de IA diseñado para reconocer objetivos militares y civiles en los que nunca se ha entrenado explícitamente, combinando conocimiento previo a gran escala con un enfoque visual más preciso en los objetos que importan.
Por qué la IA tradicional falla el objetivo
La mayoría de los sistemas de reconocimiento de imágenes aprenden a partir de enormes colecciones de imágenes etiquetadas: cada imagen se asocia a una lista fija de categorías, como “gato” o “coche”. Ese enfoque se rompe en dominios especializados como defensa y teledetección, donde los datos son sensibles, el etiquetado requiere expertos y la variedad de equipos es enorme. Modelos visión‑lenguaje más recientes, como CLIP, emparejan imágenes con breves leyendas de texto recogidas de la web, lo que les permite reconocer conceptos nuevos descritos con palabras. Sin embargo, en la imaginería militar estos modelos aún tienen dificultades: las leyendas suelen ser vagas, fondos como nubes y olas dominan los píxeles, y sus características internas no son lo bastante flexibles para ejecutarse eficazmente en dispositivos que van desde pequeños drones hasta servidores potentes. OG‑CLIP aborda los tres problemas de forma directa.
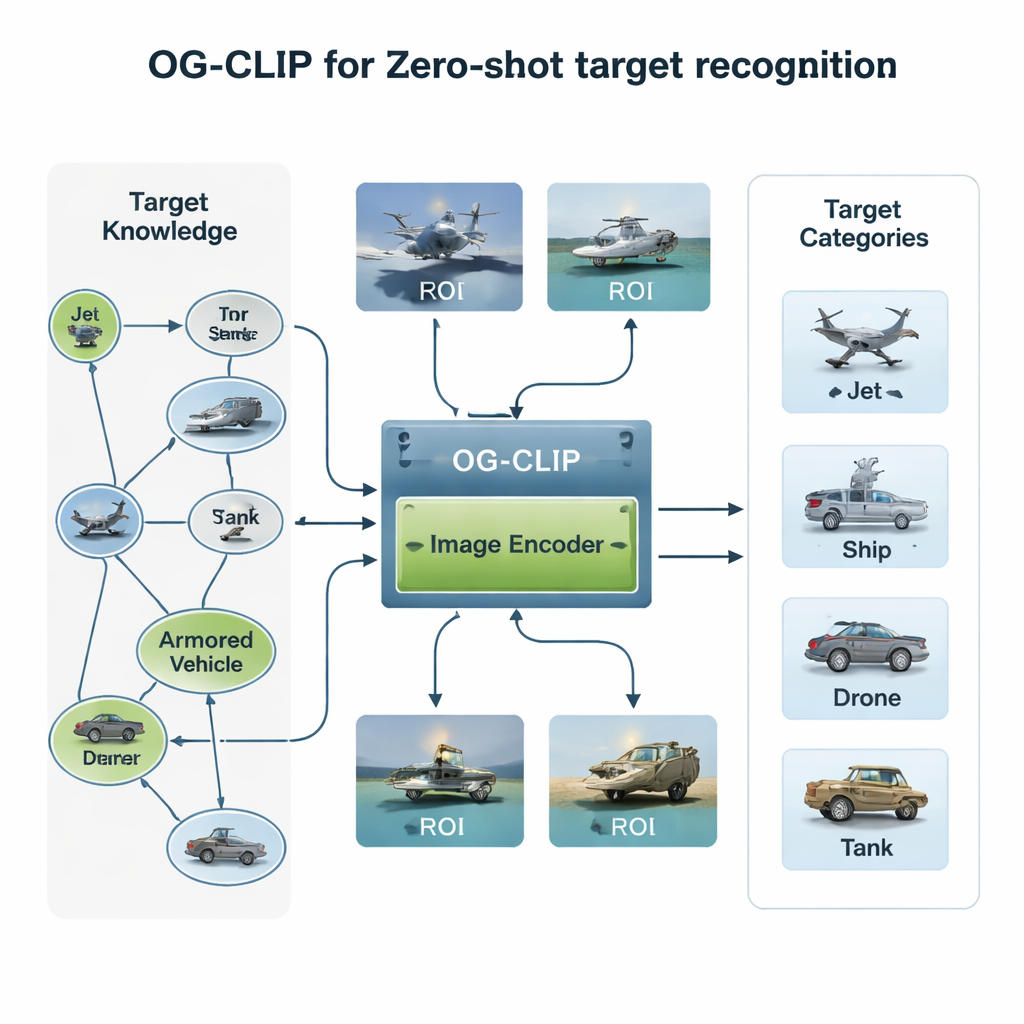
Construir un mundo de entrenamiento rico en conocimiento
El primer ingrediente de OG‑CLIP es un universo de entrenamiento cuidadosamente diseñado. Los autores reunieron una base de datos de 5.000 tipos de objetivos—que van desde cazas y bombarderos hasta buques de guerra y aeronaves civiles—y los organizaron en un grafo de conocimiento detallado. Cada entrada incluye hechos estructurados como alcance, peso y configuración de armamento, extraídos de referencias públicas de defensa, enciclopedias y documentos técnicos. A continuación recopilaron alrededor de un millón de imágenes usando conjuntos de datos públicos, búsquedas web, archivos internos antiguos e incluso escenas simuladas de motores de juego. Para mantener la fiabilidad de los datos, agruparon las imágenes con un modelo existente para detectar valores atípicos, siguieron con revisión experta y filtraron etiquetas erróneas. Finalmente, emplearon herramientas avanzadas visión‑lenguaje para convertir el grafo de conocimiento en descripciones ricas en lenguaje natural de cada imagen, de modo que el sistema aprenda no solo “esto es un jet”, sino “una aeronave de pasillo único con winglets curvados hacia arriba” o “un bombardero furtivo con forma de ala volante”.
Enseñar al modelo a ignorar el ruido
La segunda innovación reside en dónde mira el modelo. En muchas imágenes satelitales o aéreas, el buque o la aeronave ocupa solo un parche pequeño, rodeado por cielo, mar o terreno que distraen. OG‑CLIP añade un módulo de región de interés (ROI) que imita cómo un humano dirigiría la mirada al objeto clave en vez de al marco completo. Una herramienta de segmentación de última generación delimita automáticamente los objetos probables en la imagen, produciendo máscaras suaves que resaltan el objetivo y atenúan el fondo. Estas máscaras se introducen, junto con la imagen original, en la columna vertebral visual del modelo, de modo que su atención se concentra de forma natural en rasgos distintivos como la forma del ala, el diseño de la cubierta o la silueta del casco. Este diseño plug‑in puede añadirse a sistemas existentes sin reescribir su arquitectura central, dotándolos de una mirada más “guiada por objetos”.

Adaptar el nivel de detalle al hardware
La tercera pieza responde a una preocupación práctica pero crucial: no todos los dispositivos pueden permitirse el mismo nivel de detalle. Una estación terrestre satelital puede procesar características ricas y de alta dimensionalidad, mientras que un pequeño dron necesita cómputos más rápidos y ligeros. Los métodos tradicionales fijan un único tamaño de característica o entrenan varios modelos separados para diferentes tamaños. OG‑CLIP, en cambio, utiliza una representación al estilo “Matrioshka”, empaquetando información en varios niveles de detalle dentro de un único vector, como muñecas rusas anidadas. El sistema puede cortar porciones más cortas o más largas de este vector—descripciones más gruesas o más finas de lo que hay en la imagen—sin necesidad de reentrenar. Un mecanismo de ponderación anima a cada nivel a conservar la información más útil para la clasificación, y un término de pérdida adicional empuja a que los niveles se mantengan semanticamente coherentes entre sí.
¿Qué tal funciona en la práctica?
Para evaluar OG‑CLIP, los investigadores construyeron un conjunto de prueba exigente de 99 categorías de objetivos, que incluye 51 tipos de aeronaves militares, 29 tipos de buques de guerra y 19 objetivos civiles o mixtos. De forma crucial, ninguna de estas categorías aparece en los datos de entrenamiento, por lo que el sistema debe apoyarse en su comprensión aprendida del lenguaje y de los patrones visuales—una prueba “zero‑shot”. En comparación con varias líneas base fuertes basadas en CLIP, OG‑CLIP mejoró la precisión media en más de 11 puntos porcentuales, alcanzando un 84,28 por ciento global. Funcionó especialmente bien en escenas concurridas y complejas y en distinciones finas entre modelos similares, como diferentes cazas, donde el módulo ROI y las descripciones ricas en conocimiento le dieron una ventaja clara. Estudios de ablación mostraron que cada componente—los datos del grafo de conocimiento, el enfoque ROI y las representaciones adaptativas—aportó mejoras mensurables.
Qué significa esto para la vigilancia en el mundo real
Para no especialistas, la conclusión clave es que OG‑CLIP es un paso hacia sistemas de seguridad y vigilancia que pueden reconocer con mayor fiabilidad aeronaves y buques desconocidos a partir de imágenes del mundo real, incluso cuando los ejemplos etiquetados son escasos. Al combinar conocimiento experto estructurado, enfoque automático en el objeto de interés y niveles ajustables de detalle, el enfoque hace que la IA visión‑lenguaje sea tanto más inteligente como más práctica. Más allá de la defensa, ideas similares podrían ayudar a la monitorización ambiental, la respuesta a desastres y los sistemas de inspección industrial a interpretar escenas complejas mientras operan en una amplia gama de hardware.
Cita: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Palabras clave: reconocimiento zero‑shot, modelos visión‑lenguaje, detección de objetos, teledetección, grafos de conocimiento