Clear Sky Science · es
Percepción visual basada en transformers de aprendizaje profundo para clasificar pinturas y fotografías mediante extracción de características
Por qué importa para las imágenes de uso cotidiano
En una era en la que cualquiera puede generar una imagen realista con unos pocos clics, cada vez resulta más difícil distinguir si una imagen es una fotografía real, una pintura tradicional o algo creado totalmente por algoritmos. Este estudio explora cómo la inteligencia artificial moderna puede distinguir automáticamente las pinturas hechas por humanos de las fotos tomadas con cámara e incluso de las imágenes generadas por IA, ayudando a proteger mercados del arte, archivos y usuarios en línea frente a la confusión y la falsificación.
El arte, las fotos y el auge de las imágenes hechas por máquinas
Pinturas y fotografías pueden parecer similares a primera vista en una pantalla, pero portan huellas visuales muy distintas. Las pinturas tienden a mostrar pinceladas visibles, colores estilizados y composiciones más abstractas, mientras que las fotografías suelen contener detalles más nítidos e iluminación natural. Al mismo tiempo, los nuevos generadores de imágenes están produciendo obras que imitan ambos medios con creciente habilidad. Museos, galerías, coleccionistas y plataformas digitales necesitan cada vez más herramientas que puedan identificar rápida y de forma fiable el tipo de imagen con el que tratan, tanto para autenticar obras como para gestionar la avalancha de contenido sintético.
Un nuevo flujo de trabajo para enseñar a las máquinas a ver
Los investigadores construyeron una canalización completa de análisis de imágenes basada en un Vision Transformer, un modelo de aprendizaje profundo reciente desarrollado originalmente para el procesamiento del lenguaje y ahora adaptado a imágenes. Entrenaron este sistema con un conjunto de datos público de Kaggle que contiene 1.361 pinturas y 3.747 fotografías, representando una amplia variedad de escenas y estilos. Cada imagen se estandariza inicialmente: se redimensiona, se recorta ligeramente y luego se aumenta mediante volteos, pequeñas rotaciones, cambios de brillo y eliminación de ruido para que el modelo experimente muchas variaciones realistas. Tras esta preparación, el Vision Transformer divide cada imagen en pequeños parches y aprende cómo se relacionan las distintas partes de la imagen entre sí en todo el encuadre. 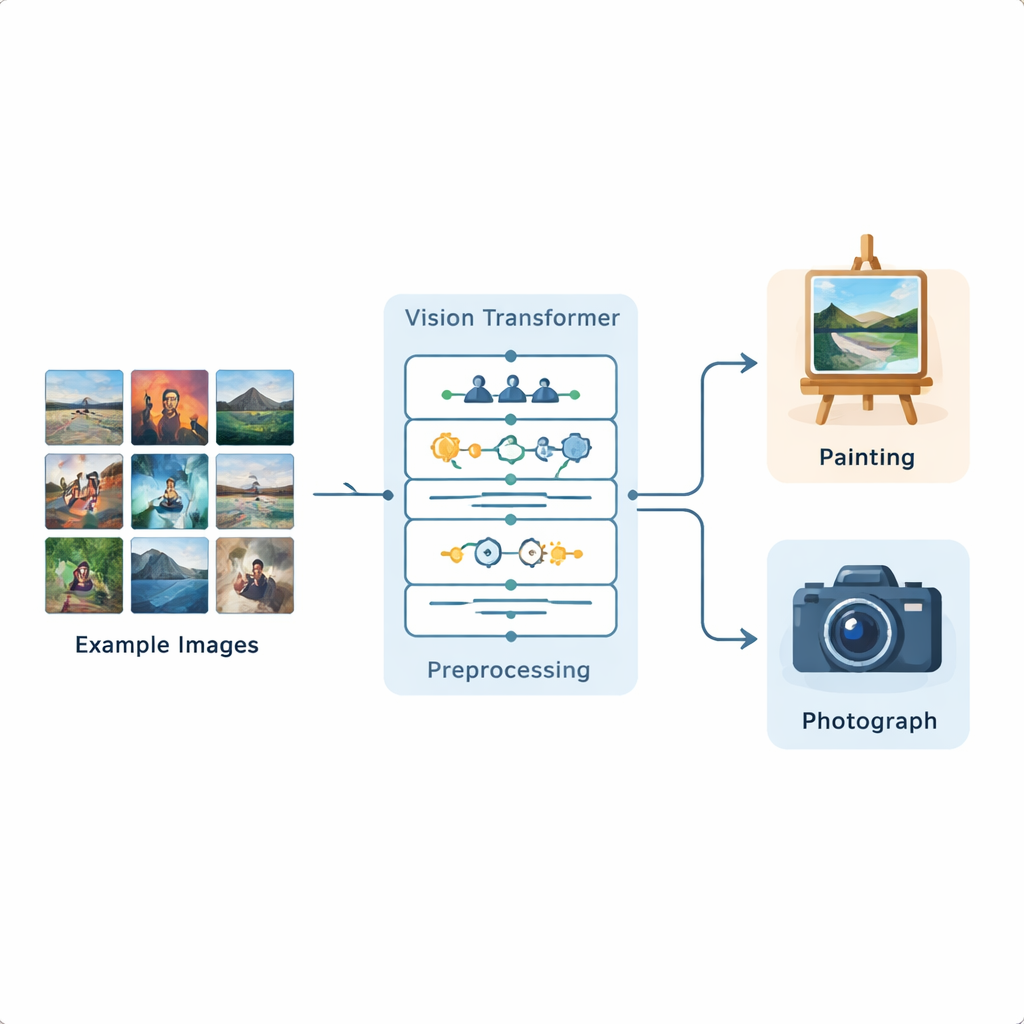
Cómo el modelo se centra en los detalles relevantes
A diferencia de redes neuronales anteriores que miraban principalmente patrones locales, el Vision Transformer utiliza un mecanismo de “atención” para decidir qué partes de una imagen importan más para la tarea. Efectivamente se pregunta, para cada parche, con cuánta intensidad debe atender a cada otro parche. Esto le permite captar mejor la estructura global: cómo fluyen los colores en un lienzo, cómo cae la luz en una escena o cómo se repiten las texturas. Para comprobar que el modelo no adivina a ciegas, los autores también aplican un método de visualización llamado Grad-CAM, que resalta las regiones específicas que influyeron en cada decisión. En las pinturas, estos realces tienden a concentrarse en texturas de pinceladas y áreas estilizadas; en las fotografías, se agrupan alrededor de bordes finos, superficies realistas y transiciones de iluminación. 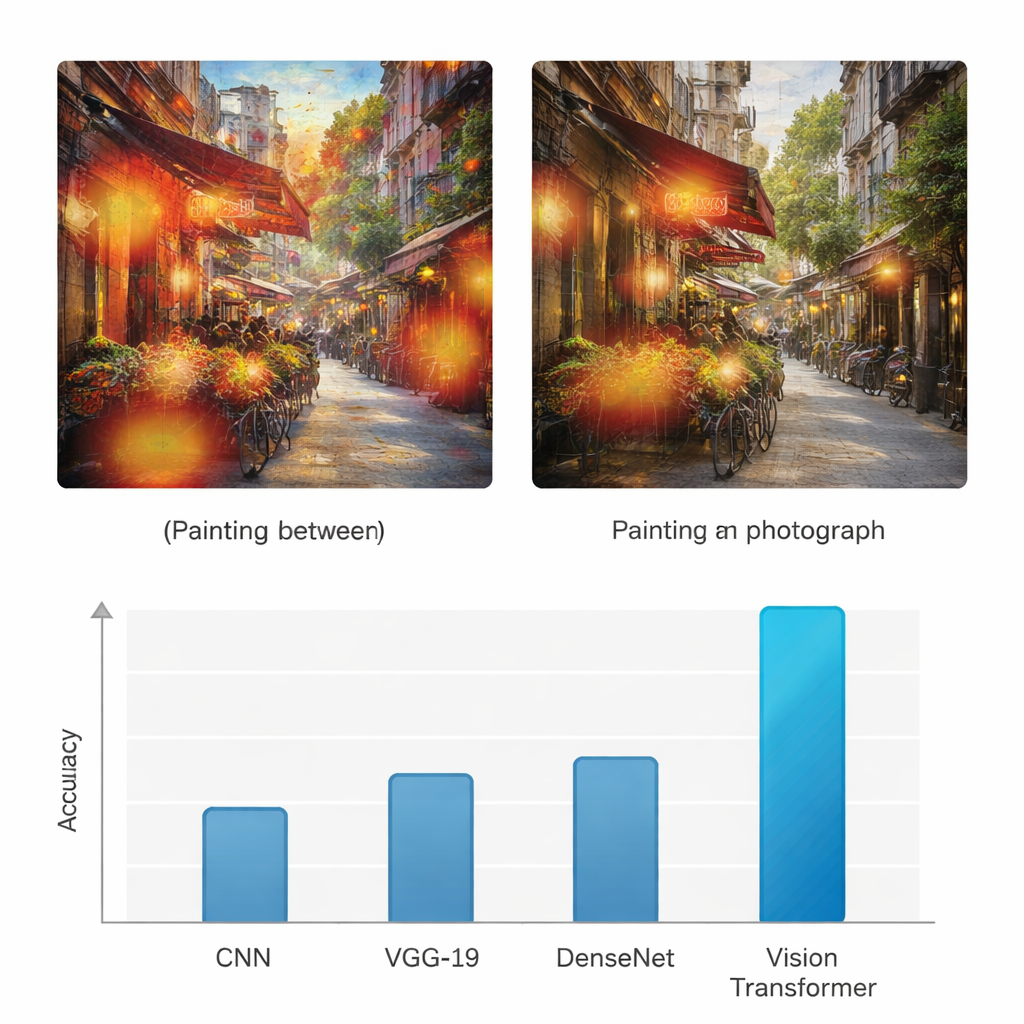
Superando a métodos previos de reconocimiento de imágenes
Para evaluar si este enfoque aporta valor real, el estudio compara el Vision Transformer con tres arquitecturas de aprendizaje profundo ampliamente usadas: una red neuronal convolucional (CNN) estándar, la red VGG-19 y DenseNet. Todos los modelos se entrenan y prueban sobre el mismo conjunto de datos, y se evalúan con medidas comunes como precisión (accuracy), precision, recall y F1-score, que equilibran las detecciones correctas y los errores para ambas clases. Mientras que las redes de referencia alcanzan precisiones en el rango medio del 70% a medio 80%, el Vision Transformer logra un 95% de precisión tanto para pinturas como para fotografías, con valores de precision y recall igualmente altos. Los autores además realizan múltiples pruebas estadísticas para confirmar que esta mejora no se debe al azar, demostrando que el modelo basado en transformers es consistentemente mejor a lo largo de ensayos repetidos y distintos criterios de evaluación.
Qué significa esto para el arte, la confianza y la tecnología
Los hallazgos sugieren que los modelos transformers modernos pueden servir como herramientas potentes y explicables para separar pinturas de fotografías y para detectar imágenes generadas por IA que imitan cualquiera de los dos medios. Para el público no especialista, la conclusión es que los ordenadores ya pueden detectar señales sutiles —como la pincelada, la suavidad o los gradientes de iluminación— que incluso observadores humanos atentos podrían pasar por alto, y hacerlo a gran escala. Estos sistemas podrían ayudar a galerías y coleccionistas a verificar obras, asistir a curadores y archiveros a organizar vastas colecciones digitales y apoyar a plataformas en línea a etiquetar o filtrar contenido sintético. A medida que los generadores de imágenes continúan difuminando la línea entre realidad e invención, métodos como el presentado aquí ofrecen una forma práctica de mantener la confianza en lo que vemos.
Cita: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Palabras clave: imágenes generadas por IA, autenticación de arte, clasificación de imágenes, vision transformer, análisis de arte digital