Clear Sky Science · es
Meta-aprendizaje para el reconocimiento de tareas abiertas con pocos ejemplos
Por qué importa enseñar a la IA con muy pocos ejemplos
Los sistemas modernos de IA pueden reconocer rostros, animales y objetos cotidianos con una precisión notable, pero normalmente solo después de ver millones de imágenes etiquetadas. En muchas situaciones reales —como diagnosticar una enfermedad rara o detectar un nuevo tipo de defecto en una línea de producción— simplemente no disponemos de tantos datos. Este artículo explora cómo entrenar modelos de IA que puedan aprender nuevas tareas visuales a partir de apenas unos pocos ejemplos, incluso cuando esas tareas son muy diferentes de lo que el modelo vio durante el entrenamiento. Presenta un método llamado Open-MAML que pretende hacer este tipo de aprendizaje flexible y con pocos datos más fiable y predecible.
De ejercicios de aula fijos a exámenes sorpresa de respuesta abierta
La mayor parte de la investigación sobre «few-shot learning» evalúa los sistemas de IA en condiciones muy controladas. El modelo se entrena y prueba en tareas muy similares, por ejemplo siempre teniendo que distinguir entre exactamente cinco categorías (llamado «5-way») con un ejemplo por categoría («1-shot»). Esto es como preparar a un estudiante únicamente con cuestionarios de cinco preguntas y un ejemplo de práctica por tipo de pregunta. Las aplicaciones en el mundo real son mucho más caóticas: el número de categorías puede cambiar y la cantidad de datos etiquetados por cada una puede aumentar o disminuir con el tiempo. Los autores denominan esta situación más realista el escenario de tareas abiertas, donde los modelos deben gestionar tareas con números de clases y ejemplos distintos a los que vieron durante el entrenamiento. 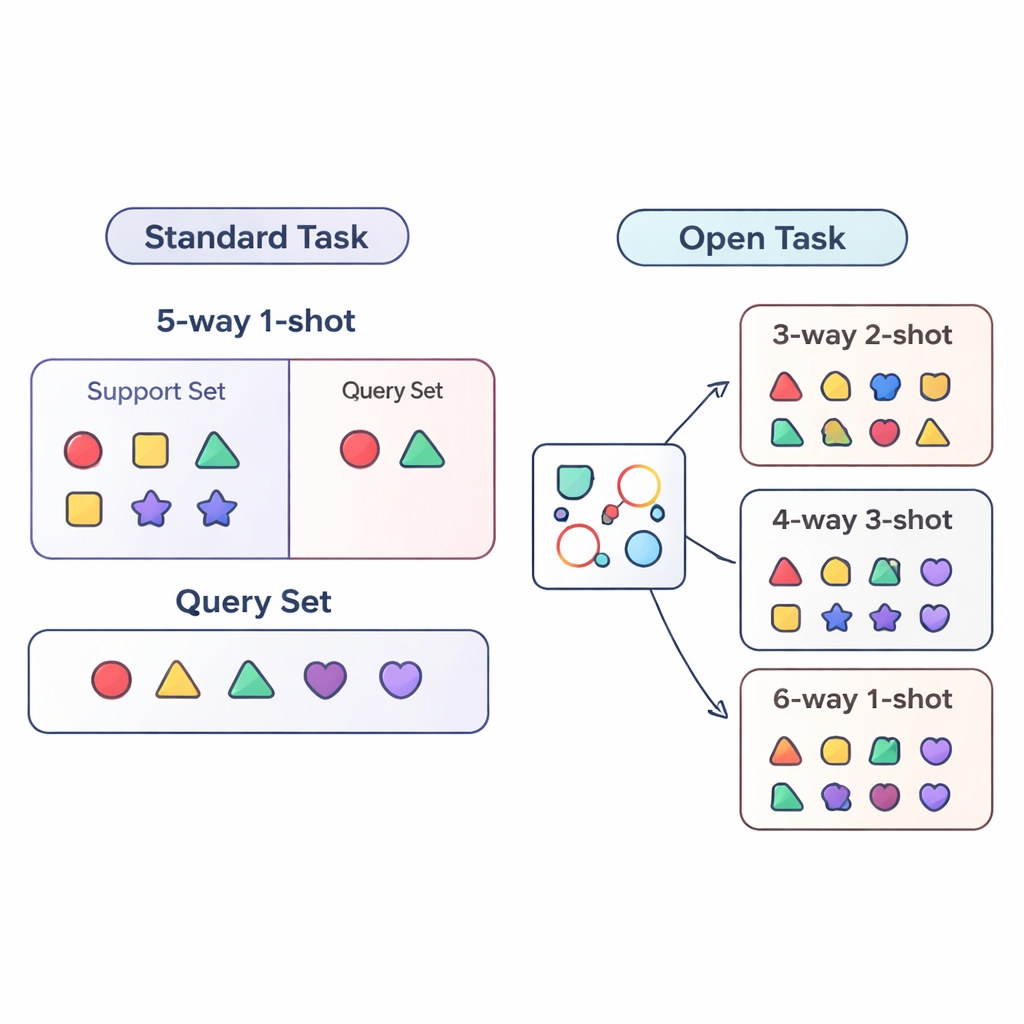
Redefiniendo cómo evaluamos a los aprendices de pocos ejemplos
Para estudiar de forma sistemática este mundo de tareas abiertas, el artículo propone tres regímenes de evaluación. En el régimen cross-way, solo cambia el número de clases: el modelo puede entrenarse con cinco clases pero probarse con tres o quince. En el régimen cross-shot, varía el número de ejemplos por clase, desde una sola imagen etiquetada hasta varias. El caso más difícil es cross-way–cross-shot, donde tanto el número de clases como la cantidad de datos por clase cambian simultáneamente. Los autores también examinan qué ocurre cuando cambia el estilo visual de los datos, entrenando en un conjunto genérico de objetos y probando en un conjunto de aves de alta resolución. Estos montajes están diseñados para poner de manifiesto si un método puede realmente generalizar más allá de una receta de entrenamiento fija.
Cómo Open-MAML se adapta sobre la marcha
Open-MAML se basa en una estrategia popular de meta-aprendizaje llamada Model-Agnostic Meta-Learning (MAML), que entrena un modelo para que pueda adaptarse rápidamente a una nueva tarea con unos pocos pasos de gradiente. Sin embargo, el MAML estándar asume que el número de categorías en la prueba coincide con el del entrenamiento y utiliza una capa de clasificación final fija. Open-MAML introduce tres ajustes clave para romper esta limitación. Primero, emplea construcción dinámica del clasificador: cuando una nueva tarea tiene más clases que antes, crea unidades de salida adicionales copiando la media de las existentes, dando al modelo un punto de partida neutral pero razonable. Segundo, ajusta la tasa de aprendizaje interna en función de cuántas clases y ejemplos tiene la tarea, de modo que la adaptación sea estable tanto si los datos son escasos como abundantes. Tercero, añade un regularizador llamado AdaDropBlock que oculta temporalmente regiones contiguas en los mapas de características durante el entrenamiento, empujando al modelo a usar señales visuales más diversas en lugar de sobreajustarse a detalles pequeños y frágiles. 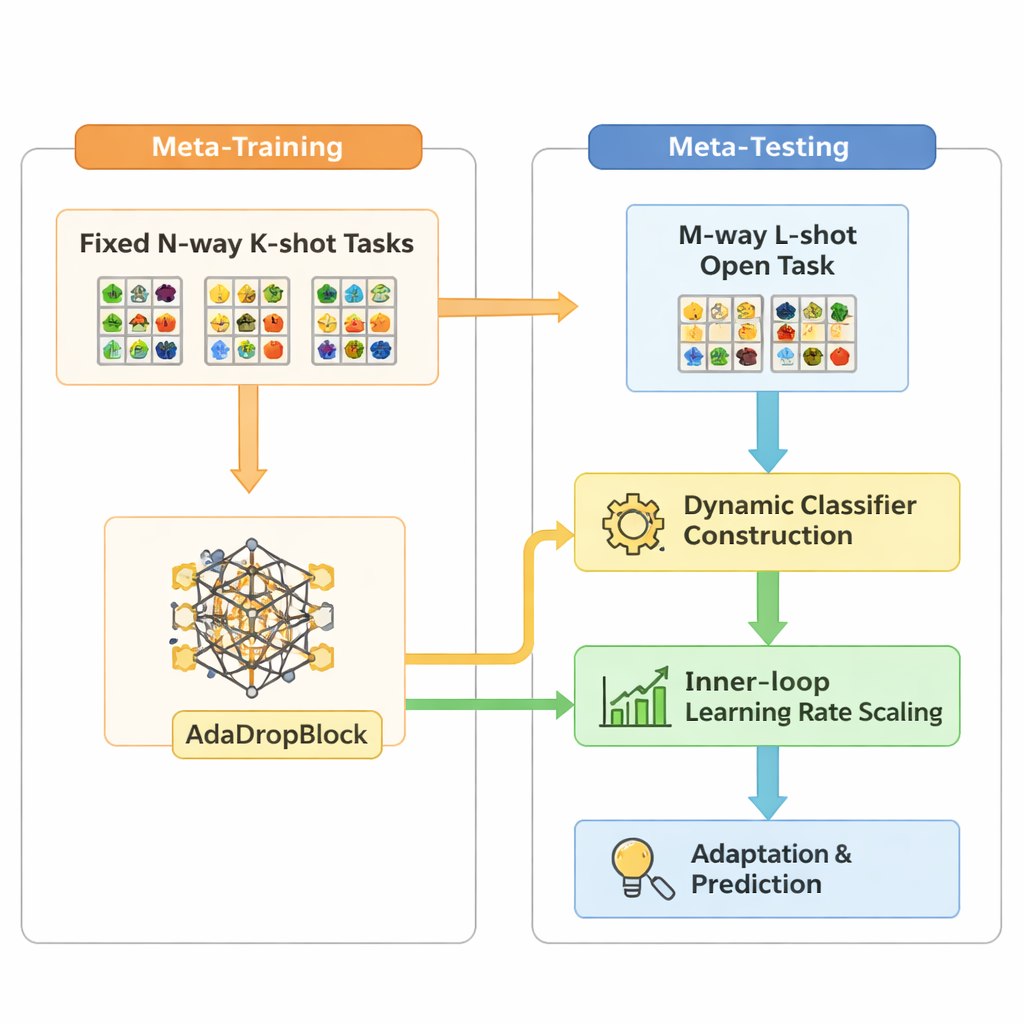
Poniendo a prueba el aprendizaje flexible
Los investigadores evalúan Open-MAML en benchmarks estándar de few-shot y en los nuevos escenarios de tareas abiertas, comparándolo con varias líneas base conocidas. Estas incluyen modelos entrenados desde cero para cada tarea, modelos que usan un extractor de características preentrenado sólido más un clasificador afinado, y métodos basados en métricas que clasifican imágenes según su distancia a «prototipos» de clase. Todos los métodos comparten la misma red base para que las diferencias provengan de la estrategia de aprendizaje y no de la arquitectura. A lo largo de decenas de miles de tareas de prueba, Open-MAML consigue de forma consistente una mayor precisión —típicamente entre 1 y 7 puntos porcentuales mejor cuando solo cambia el número de clases o de ejemplos, y entre 3 y 6 puntos mejor cuando ambos varían. Las ganancias son aún más pronunciadas en escenarios más difíciles con más clases, más ejemplos por clase, o con el cambio al conjunto de aves, lo que sugiere que sus mecanismos de adaptación realmente ayudan en territorios complejos y poco familiares.
Qué significa esto para los sistemas de IA en el mundo real
Para un lector general, la conclusión es que no todos los aprendices de pocos ejemplos son iguales una vez que salimos de la zona de confort del laboratorio. Un método que destaca en un benchmark único y fijo puede fallar cuando cambia el número de categorías o la cantidad de datos etiquetados. Open-MAML demuestra que, al planificar explícitamente para esos cambios estructurales —permitiendo que el clasificador crezca o se reduzca, escalando la tasa de aprendizaje con el tamaño de la tarea y regularizando las características de forma independiente a la tarea—, los sistemas de IA pueden afrontar mejor las condiciones cambiantes que encontrarán en la práctica. En escenarios como imagen médica, vigilancia por satélite o inspección industrial, donde tanto el conjunto de categorías como la disponibilidad de etiquetas cambian constantemente, este tipo de robustez frente a tareas abiertas podría hacer que el few-shot learning sea mucho más utilizable fuera de benchmarks cuidadosamente curados.
Cita: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Palabras clave: aprendizaje con pocos ejemplos, meta-aprendizaje, reconocimiento de tareas abiertas, clasificación de imágenes, generalización