Clear Sky Science · es
IASUNet: extracción de edificios basada en Swin-UperNet con atención mejorada
Por qué es importante detectar cada edificio desde el espacio
A medida que las ciudades crecen y el clima cambia, conocer con exactitud dónde están los edificios —y cómo cambian con el tiempo— se ha vuelto vital. Desde planificar vecindarios más seguros y vigilar construcciones ilegales hasta guiar la respuesta ante desastres tras inundaciones o terremotos, los mapas detallados de edificios son hoy un ingrediente central de las ciudades inteligentes y resilientes. Este artículo presenta IASUNet, un nuevo sistema de inteligencia artificial que aprende a identificar automáticamente edificios en imágenes satelitales de alta resolución con una precisión notable, incluso en escenas reales desordenadas y densamente pobladas.
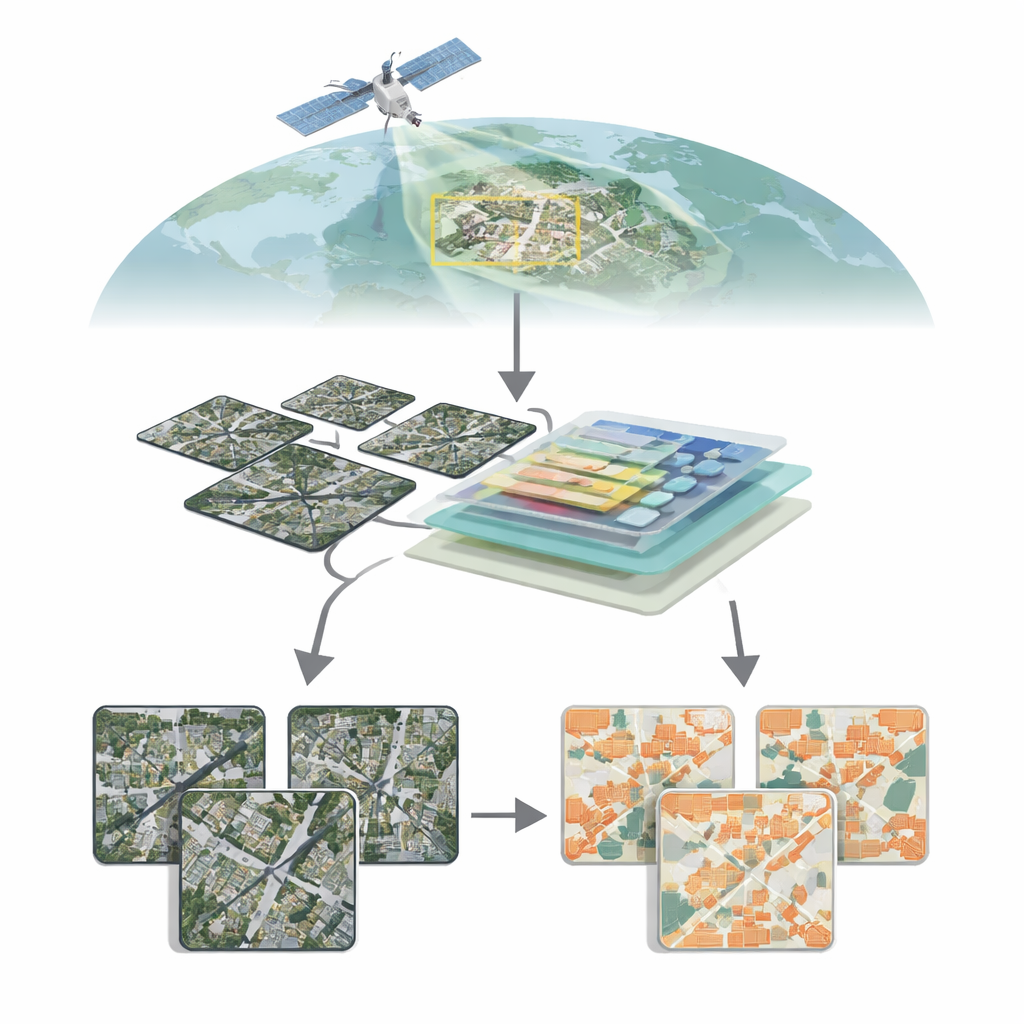
Ver las ciudades desde arriba
Los satélites modernos pueden fotografiar la Tierra con un detalle extraordinario, revelando tejados individuales, carreteras e incluso callejones estrechos. Convertir ese mar de píxeles en mapas de edificios limpios, sin embargo, está lejos de ser trivial. Los edificios varían de forma drástica en tamaño, forma, color y entorno: rascacielos de vidrio en el centro, casas bajas en las afueras, construcciones agrícolas dispersas en el campo. En zonas rurales o mixtas, los edificios pueden ocupar solo una fracción muy pequeña de cada imagen, mientras que la vegetación, el suelo y el agua dominan. Los métodos tradicionales de visión por computador, basados principalmente en redes neuronales convolucionales, pueden tener dificultades para captar la visión global de una escena entera al tiempo que respetan límites finos, lo que conduce a estructuras pequeñas perdidas o bordes difuminados.
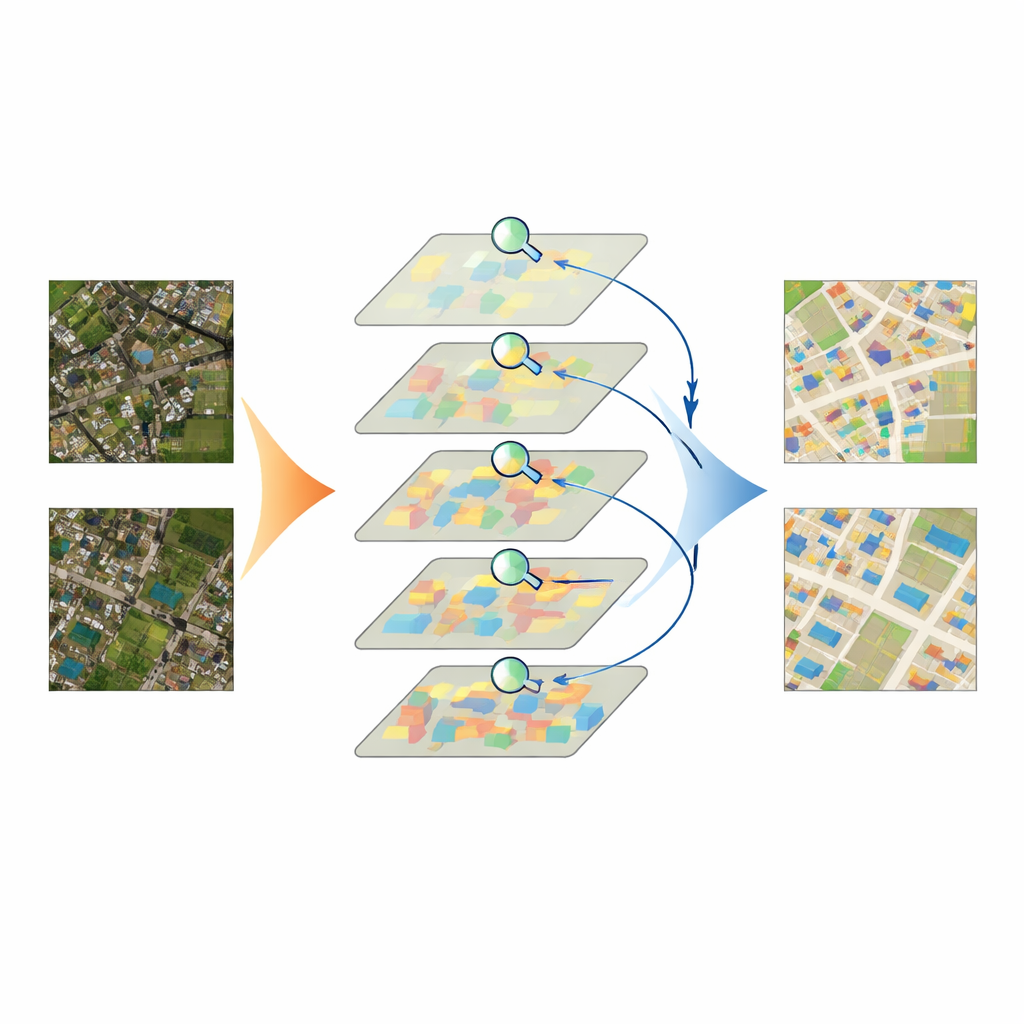
Una atención más inteligente a los detalles
IASUNet afronta estos desafíos combinando dos ideas poderosas: un codificador basado en Transformer llamado Swin Transformer y un decodificador flexible conocido como UperNet. El Swin Transformer divide la imagen en muchos pequeños parches y aprende cómo se relacionan entre sí a lo largo de toda la escena, en lugar de mirar solo a través de una ventana de tamaño fijo. Esto ayuda al modelo a comprender el contexto más amplio —por ejemplo, si un rectángulo brillante está dentro de una manzana densa o en un campo aislado— manteniendo al mismo tiempo el detalle. Además, los autores integran un mecanismo de atención llamado Convolutional Block Attention Module (CBAM) en varias etapas. CBAM aprende, canal por canal y región por región, qué características de la imagen tienen más probabilidades de pertenecer a edificios y cuáles son ruido de fondo, realzando las primeras y suprimiendo las segundas antes de que el decodificador reconstruya el mapa completo de edificios.
Equilibrar las probabilidades cuando los edificios son raros
Otro obstáculo práctico es el desequilibrio: en muchas escenas satelitales, la mayoría de píxeles muestran carreteras, campos, árboles o agua, mientras que los edificios ocupan solo pequeñas islas. Los métodos de entrenamiento estándar tienden a favorecer lo que aparece con mayor frecuencia, lo que corre el riesgo de enseñar al modelo a tratar los edificios menos frecuentes como una nota al pie. Para contrarrestar esto, los autores adaptan una función de pérdida llamada Focal Cross‑Entropy. Esta estrategia reduce la influencia de los píxeles de fondo “fáciles” y amplifica el impacto de los píxeles de edificios difíciles de clasificar durante el entrenamiento. Como resultado, el modelo presta atención adicional a estructuras pequeñas, difusas o inusuales que de otro modo podrían pasarse por alto, mejorando la recuperación sin inundar el mapa de falsas alarmas.
Poniendo el modelo a prueba
El equipo evaluó IASUNet en tres conjuntos de datos de edificios bien conocidos de Alemania, Nueva Zelanda y Estados Unidos, así como en una colección cuidadosamente seleccionada de imágenes satelitales chinas que prepararon y verificaron con control de calidad. En estos bancos de pruebas, IASUNet igualó o superó de forma consistente a los enfoques líderes, incluidos potentes modelos convolucionales y otros modelos basados en Transformer. En el conjunto Potsdam, de ultra alto detalle, alcanzó una superposición casi perfecta entre las regiones de edificios predichas y las reales, manteniendo a la vez velocidades prácticas en hardware gráfico moderno. Incluso en paisajes más irregulares, donde los edificios están dispersos, parcialmente ocultos o muy juntos, IASUNet trazó contornos más limpios, capturó más objetivos pequeños y evitó muchas de las omisiones y errores de límite observados en métodos competidores.
De los píxeles a mejores ciudades
En términos prácticos, el estudio muestra que ahora podemos enseñar a los ordenadores a leer los paisajes urbanos desde la órbita con una claridad sin precedentes. Al dirigir cuidadosamente la “atención” del modelo hacia las partes correctas de una imagen y ponderar deliberadamente los píxeles de edificios raros pero cruciales, IASUNet convierte imágenes satelitales crudas en mapas de edificios precisos y actualizados con un coste computacional adicional moderado. Estos mapas pueden alimentar la planificación urbana, estudios de energía y de islas de calor, regulación del uso del suelo y la evaluación rápida de daños tras desastres. Aunque el trabajo es técnico en su núcleo, su conclusión es simple: una IA más inteligente puede ofrecer a los responsables una visión más nítida y fiable del entorno construido, ayudando a que las ciudades crezcan de manera más segura y sostenible.
Cita: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Palabras clave: teledetección, extracción de edificios, segmentación semántica, redes transformer, cartografía urbana