Clear Sky Science · es
Un marco de aprendizaje híbrido que integra la evolución alfa de nicho caótico para la predicción del rendimiento académico estudiantil
Por qué importa predecir las notas con antelación
Las escuelas disponen cada vez más de una mina de información sobre sus estudiantes—desde registros de asistencia y puntuaciones de tareas hasta respuestas a encuestas sobre la vida en el hogar y hábitos de estudio. Este artículo explora cómo convertir esos datos sin procesar en alertas tempranas sobre quién podría tener dificultades o destacar en un curso. Los autores presentan un nuevo marco computacional que predice con mayor precisión las calificaciones finales de estudiantes de secundaria, abriendo la puerta a apoyos más tempranos y personalizados en lugar de esfuerzos de rescate de última hora.
De los boletines a rastro de datos ricos
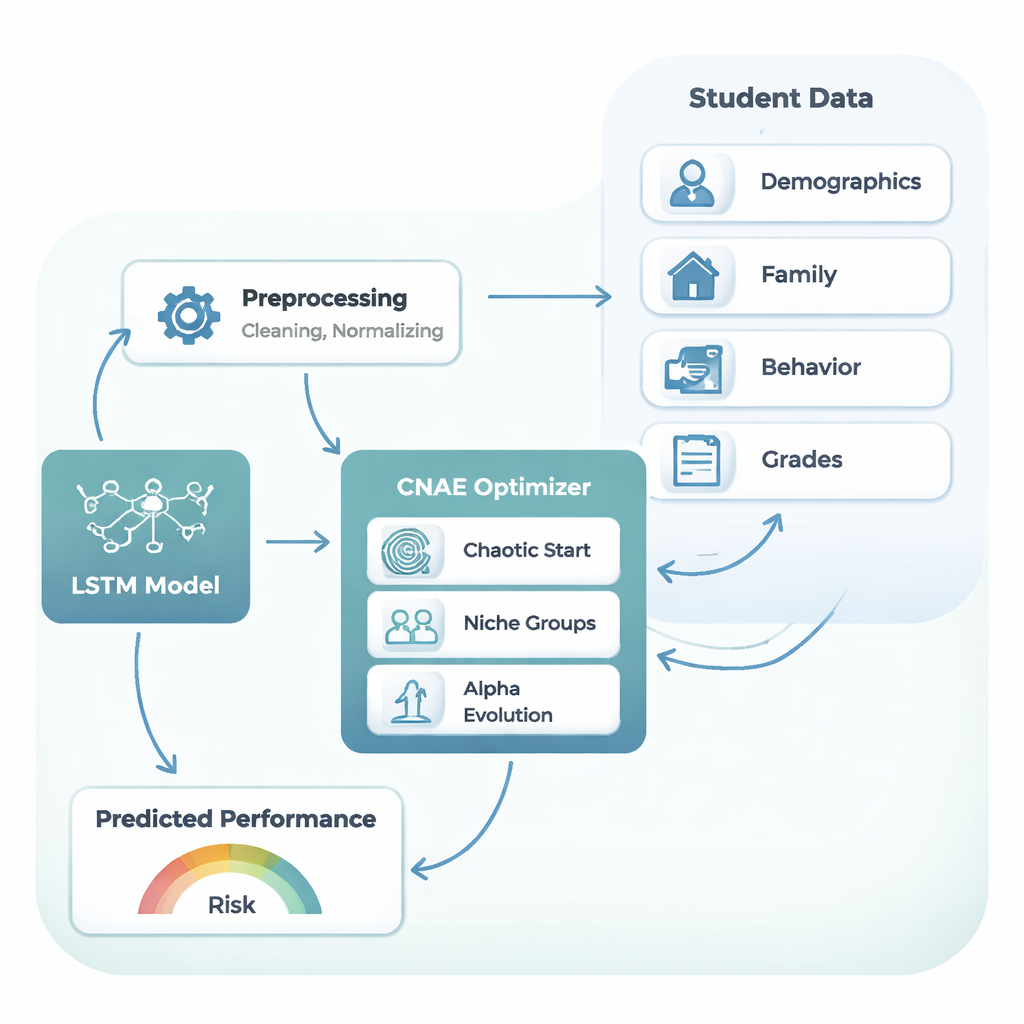
Las aulas modernas generan mucho más que un par de notas de examen. El conjunto de datos utilizado en este estudio incluye 480 estudiantes y 32 piezas distintas de información por cada uno: edad, antecedentes familiares, tiempo de desplazamiento, acceso a internet, tiempo dedicado al estudio, ausencias y tres calificaciones de curso a lo largo del año escolar. En conjunto, estos detalles trazan un recorrido de aprendizaje: cómo el esfuerzo, las circunstancias y los resultados previos se acumulan hasta una nota final. Sin embargo, esta riqueza también complica la predicción: los datos son ruidosos, desiguales y muy variables de un estudiante a otro.
Una forma más inteligente de leer el aprendizaje a lo largo del tiempo
Para seguir estos recorridos de aprendizaje, los autores recurren a un tipo de red neuronal llamada Long Short-Term Memory, o LSTM. En lugar de tratar cada dato como un hecho desconectado, un LSTM está diseñado para recordar señales útiles de etapas anteriores de una secuencia—de modo similar a un profesor que recuerda la mejora sostenida o el desinterés gradual de un alumno en lugar de fijarse solo en el último examen. En este estudio, el LSTM recibe la combinación de factores de contexto, comportamiento y calificaciones previas y produce una predicción de la nota del examen final en una escala de 0 a 20. No obstante, los LSTM son delicados: su rendimiento depende en gran medida de decisiones de diseño como cuántas capas tienen, cuántas unidades por capa, la velocidad de aprendizaje, la cantidad de regularización y cuántos registros de estudiantes ven a la vez durante el entrenamiento.
Dejar que la evolución busque el mejor modelo
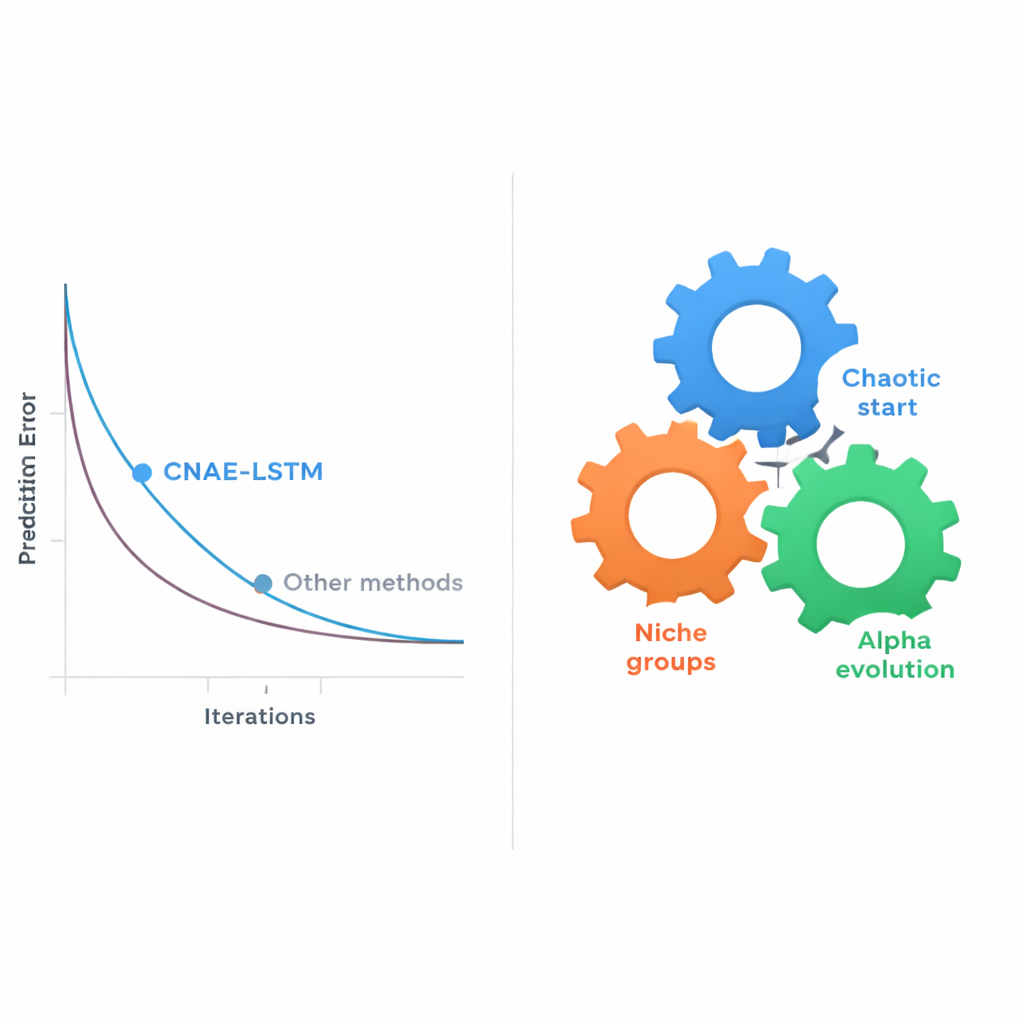
Elegir esos parámetros de diseño a mano—o incluso mediante simples búsquedas por ensayo y error—rápidamente se vuelve impracticable a medida que las combinaciones se disparan. El núcleo de este artículo es una nueva estrategia de búsqueda automática llamada Chaotic Niche Alpha Evolution (CNAE), que los autores combinan con el LSTM, formando el marco CNAE‑LSTM. CNAE comienza generando una amplia variedad de diseños candidatos de LSTM mediante un proceso matemático inspirado en el caos, asegurando que las opciones iniciales estén ampliamente repartidas por el espacio de búsqueda. Luego agrupa candidatos similares en “nichos”, conservando solo el ejemplar más fuerte de cada clúster mientras los muta ligeramente para explorar posibilidades cercanas. Finalmente, un paso de “evolución alfa” orienta la búsqueda hacia las regiones más prometedoras mientras pasa gradualmente de la exploración amplia al ajuste fino. Cada LSTM candidato se evalúa por lo bien que predice las calificaciones en un conjunto de validación reservado, y los mejores diseños sobreviven para moldear la siguiente generación.
Qué muestran los experimentos
Los investigadores probaron su enfoque con el conjunto real de datos de secundaria, comparando CNAE‑LSTM con una variedad de alternativas: una máquina de vectores soporte (un método clásico de aprendizaje automático), dos modelos de aprendizaje profundo (una red convolucional y un Transformer), un LSTM estándar ajustado a mano y varios LSTM cuyas configuraciones fueron elegidas por métodos evolutivos conocidos o por búsquedas en malla y aleatorias. El rendimiento se midió por lo cerca que quedaban las predicciones respecto a las notas reales y por cuánto de la variación en las calificaciones podía explicar el modelo. CNAE‑LSTM se impuso en todas las métricas: presentó el menor error medio de predicción y la mayor capacidad para explicar las diferencias entre estudiantes, mejorando el error en más de un 10 por ciento en comparación con la línea base evolutiva más fuerte. Repetir los experimentos 30 veces mostró que CNAE‑LSTM no solo era más preciso, sino también más estable—sus resultados variaron menos entre ejecuciones.
Por qué esto importa para estudiantes y centros educativos
Para un lector no especializado, la conclusión es sencilla: al permitir que un procedimiento de búsqueda evolutiva diseñe el modelo predictivo, las escuelas pueden obtener pronósticos más fiables de cómo concluirán los estudiantes un curso mucho antes del examen final. El marco CNAE‑LSTM convierte datos educativos reales y desordenados en una imagen más clara de quién va por buen camino y quién puede necesitar ayuda adicional, mientras emplea recursos informáticos con suficiente eficiencia para ser práctico. Aunque el estudio actual se centra en un único conjunto de datos de secundaria, el mismo enfoque podría adaptarse a otras materias y niveles escolares. Si se combina con intervenciones reflexivas y humanas, estas herramientas de pronóstico podrían ayudar a los educadores a pasar de reaccionar ante el fracaso a prevenirlo.
Cita: Chen, H., Zhou, Y. & Cao, Q. A hybrid learning framework integrating chaotic Niche alpha evolution for student academic performance prediction. Sci Rep 16, 5302 (2026). https://doi.org/10.1038/s41598-026-36263-1
Palabras clave: predicción del rendimiento estudiantil, minería de datos educativos, LSTM, optimización evolutiva, sistemas de alerta temprana