Clear Sky Science · es
Sustitución dialectal como enfoque adversarial para evaluar la robustez del PLN en árabe
Por qué el árabe cotidiano desconcierta a los ordenadores inteligentes
Hoy en día muchas aplicaciones leen texto en árabe para evaluar el sentimiento, clasificar noticias o responder preguntas. Sin embargo, estos sistemas aprenden en su mayoría del Árabe Estándar Moderno (AEM), mientras que las personas reales mezclan dialectos regionales a diario. Este artículo muestra cómo reemplazar una sola palabra por su equivalente en árabe egipcio o del Golfo puede engañar a modelos lingüísticos de vanguardia, lo que plantea preocupaciones para quienes dependen de la IA en árabe en atención al cliente, monitorización mediática o seguridad en línea.
Un idioma, muchas voces
El árabe no es una forma única y uniforme de hablar. El AEM se usa en la escuela, los informativos y la escritura oficial, pero las conversaciones cotidianas se basan en dialectos como el egipcio o el del Golfo. Estas variedades difieren en vocabulario, formas de las palabras e incluso en la estructura de la oración. Por ejemplo, una palabra simple como “ahora” adopta formas muy distintas según la región. Para los lectores humanos, esas variaciones son naturales y fáciles de entender. Para los modelos informáticos entrenados casi exclusivamente en AEM, sin embargo, las palabras dialectales pueden resultar extrañas, convirtiendo una frase clara en algo desconcertante.
Convertir los dialectos en una prueba de esfuerzo para la IA
Para sondear cuán frágiles son realmente los modelos de árabe, el autor diseña una prueba simple en dos pasos. Primero, se consulta repetidamente al modelo para localizar la única palabra de una oración que más influye en su decisión, a menudo un adjetivo contundente, un verbo clave o un sustantivo temático. Segundo, esa palabra se sustituye por su equivalente en árabe egipcio o del Golfo usando un gran modelo «dialectizador» finamente ajustado. El resto de la oración queda intacto y el significado sigue siendo el mismo para los lectores humanos. Esto convierte la frase modificada en un ejemplo adversarial realista: un ajuste mínimo y natural diseñado para engañar al sistema sin alterar el mensaje pretendido.
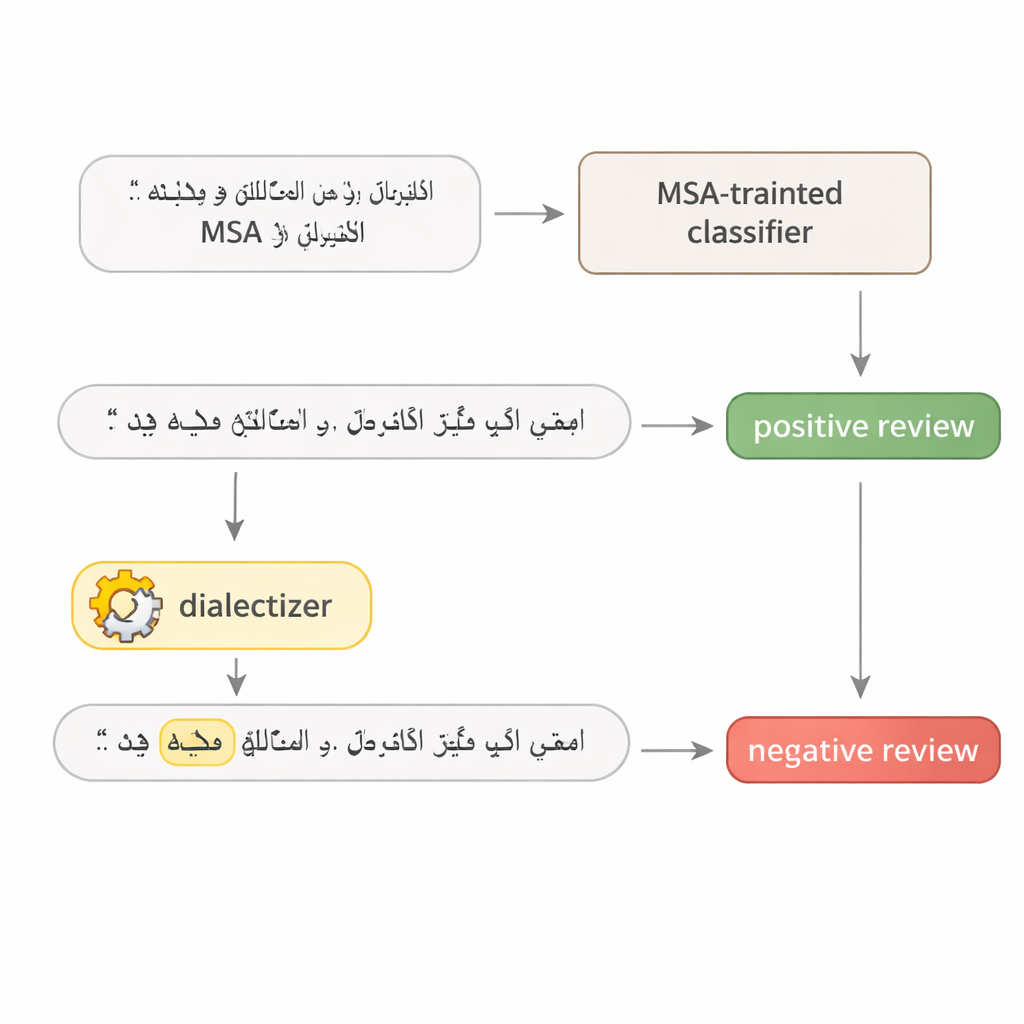
Evaluando reseñas de hoteles y artículos de prensa
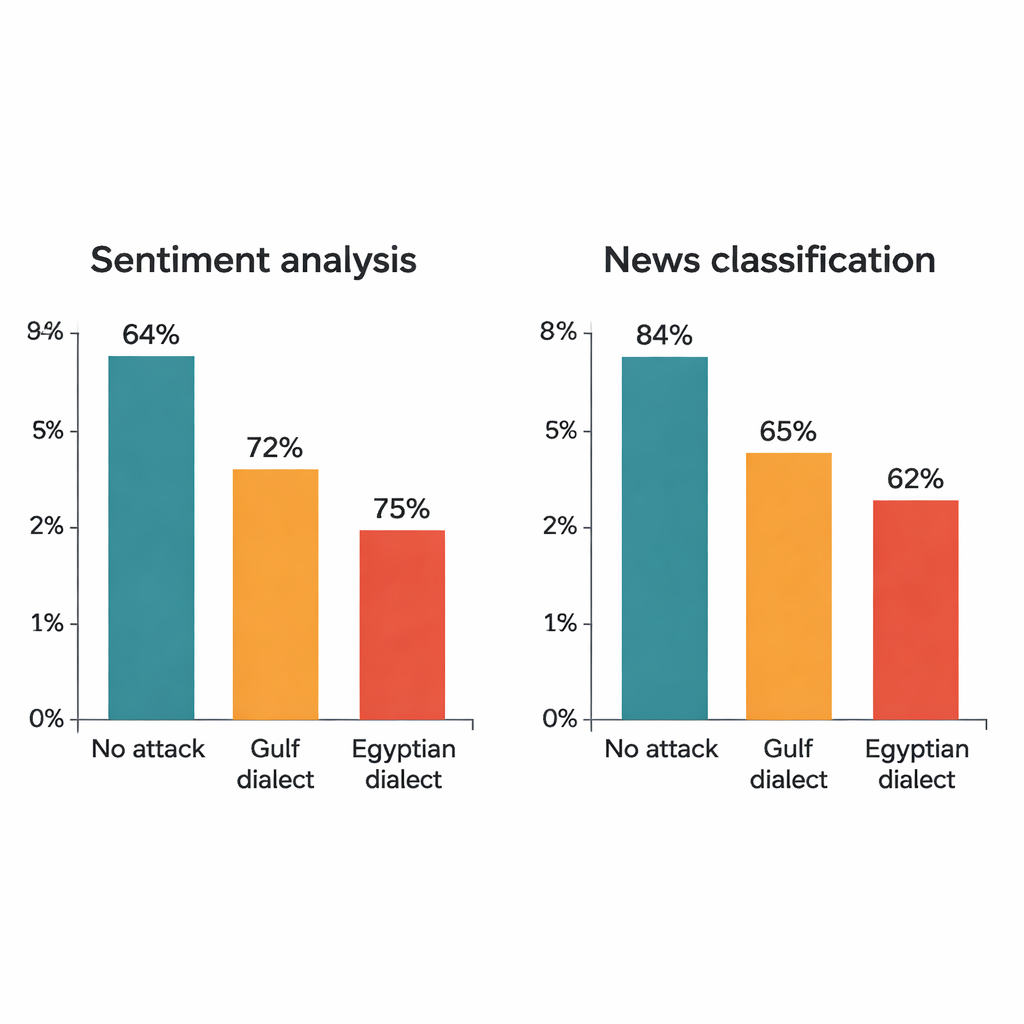
El estudio ataca cuatro modelos de aprendizaje profundo conocidos: dos grandes transformadores (AraBERT y CAMeLBERT) y dos redes más pequeñas (un modelo convolucional y una LSTM bidireccional). Se entrenan con dos grandes conjuntos MSA: reseñas de hoteles para análisis de sentimiento y artículos de noticias para clasificación temática. De cada conjunto de prueba, el autor toma 1.280 ejemplos y aplica el procedimiento de sustitución dialectal. Aunque sólo se cambia una palabra por oración, el impacto es notable. En las reseñas de hoteles, la precisión de AraBERT cae del 94 por ciento en texto limpio a alrededor del 72 por ciento con sustituciones del Golfo y al 65 por ciento con las egipcias. CAMeLBERT baja aún más, hasta aproximadamente 63 y 55 por ciento. Los clasificadores de noticias también se resienten: el modelo convolucional pierde entre 18 y 22 puntos porcentuales, y la LSTM muestra descensos similares.
Qué falla dentro de los modelos
Un análisis más detallado revela que las palabras más vulnerables coinciden con cómo las personas realmente leen el texto. En las reseñas de hoteles, casi la mitad de las palabras objetivo son adjetivos como «bueno» o «terrible», que cargan un claro peso emocional. En los artículos de prensa, la mayoría de las palabras seleccionadas son sustantivos y nombres que señalan temas como política, deportes o finanzas. Cuando esas palabras desencadenantes se cambian por formas dialectales, los modelos entrenados sólo en AEM a menudo dejan de reconocerlas. Los transformadores resultan especialmente frágiles: su dependencia de fragmentos de subpalabras y la atención concentrada en unos pocos tokens muy ponderados hace que una sola palabra dialectal baste para hacer caer una predicción. Los modelos más pequeños, que distribuyen la atención de forma más uniforme a lo largo de la oración, también son engañados, pero muestran una robustez ligeramente mayor.
Egipcio frente al Golfo: no todos los dialectos son iguales
Los ataques también revelan que el árabe egipcio tiende a desestabilizar más a los modelos que el árabe del Golfo. Estudios lingüísticos respaldan esto: las variantes del Golfo suelen mantenerse más cercanas al AEM en vocabulario y estructura, mientras que el egipcio ha absorbido formas más distintas por su historia y contacto con otras lenguas. Como resultado, las sustituciones del Golfo a veces se parecen lo suficiente al original en AEM como para que el modelo pueda seguir funcionando, mientras que las egipcias tienen más probabilidades de quedar fuera de lo que el modelo ha visto antes. Pruebas estadísticas confirman que las caídas de rendimiento observadas no son aleatorias: reflejan puntos ciegos sistemáticos en cómo los sistemas actuales manejan la diglosia árabe.
Qué significa esto para la IA en árabe
Para los usuarios cotidianos, la conclusión es simple: la IA en árabe de hoy puede confundirse fácilmente con palabras dialectales ordinarias, incluso cuando los humanos encuentran el texto perfectamente claro. Un único término dialectal en una reseña de hotel puede hacer que el juicio de un modelo pase de positivo a negativo, o que se etiquete erróneamente el tema de una noticia. Para investigadores y desarrolladores, el mensaje es un llamado a construir sistemas «conscientes de la diglosia» que se entrenen tanto en AEM como en dialectos regionales, y a usar pruebas de esfuerzo realistas como la sustitución dialectal al evaluar la robustez. Hasta entonces, cualquier aplicación que asuma «el árabe es solo AEM» corre el riesgo de malentendidos graves en el entorno real.
Cita: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Palabras clave: PLN en árabe, variación dialectal, ejemplos adversariales, análisis de sentimiento, clasificación de texto