Clear Sky Science · es
Predicción de la calidad del agua superficial mediante una red neuronal híbrida MLA-Mamba con optimización GRPO
Por qué importa predecir la salud de los ríos
Los ríos y lagos son nuestras fuentes de agua potable, abastecimientos para riego y hábitats para la vida silvestre. Sin embargo, su calidad puede cambiar rápidamente cuando la contaminación llega desde explotaciones agrícolas, fábricas o ciudades. Las autoridades a menudo se enteran sólo después de que el daño ya se ha producido. Este estudio explora cómo la inteligencia artificial moderna puede funcionar como un sistema de alerta temprana inteligente, pronosticando cambios en la calidad del agua con días de antelación para que los gestores dispongan de tiempo para reaccionar.
Herramientas antiguas, problemas nuevos
Durante décadas, los científicos han intentado predecir la calidad del agua usando fórmulas matemáticas y estadística tradicional. Estos métodos o bien simulan la química y el flujo con gran detalle o ajustan mediciones pasadas con curvas relativamente simples. Ambos enfoques sufren frente a la realidad compleja de los ríos, donde el tiempo atmosférico, las descargas aguas arriba y la actividad biológica interactúan de formas no lineales. A menudo no detectan picos de contaminación repentinos ni logran capturar cómo las condiciones en una estación de control se propagan río abajo hasta otra. Como resultado, las previsiones pueden ser demasiado toscas para tomar decisiones con confianza.
Enseñar a una red neuronal a leer un río
Los autores proponen un nuevo modelo de aprendizaje profundo, denominado MLA-Mamba, diseñado específicamente para ese enredo de espacio y tiempo. En lugar de observar un único sensor de forma aislada, el modelo ingiere una semana de datos horarios de múltiples estaciones de control, junto con información complementaria como temperatura del agua, caudal y acidez. Luego aprende a predecir cuatro indicadores clave que señalan contaminación orgánica y carga de nutrientes: un índice de demanda química de oxígeno (CODMn), amonio (NH3–N), fósforo total (TP) y nitrógeno total (TN). El modelo combina dos componentes especializados. Uno se centra en los patrones temporales, detectando ciclos, derivas lentas y efectos retardados. El otro examina el espacio, aprendiendo cómo las estaciones aguas arriba y vecinas se comportan de forma conjunta. Al fusionar estas perspectivas, la red construye una imagen más rica de cómo evoluciona la calidad del agua.
Capturar tanto las tendencias temporales como la influencia aguas arriba
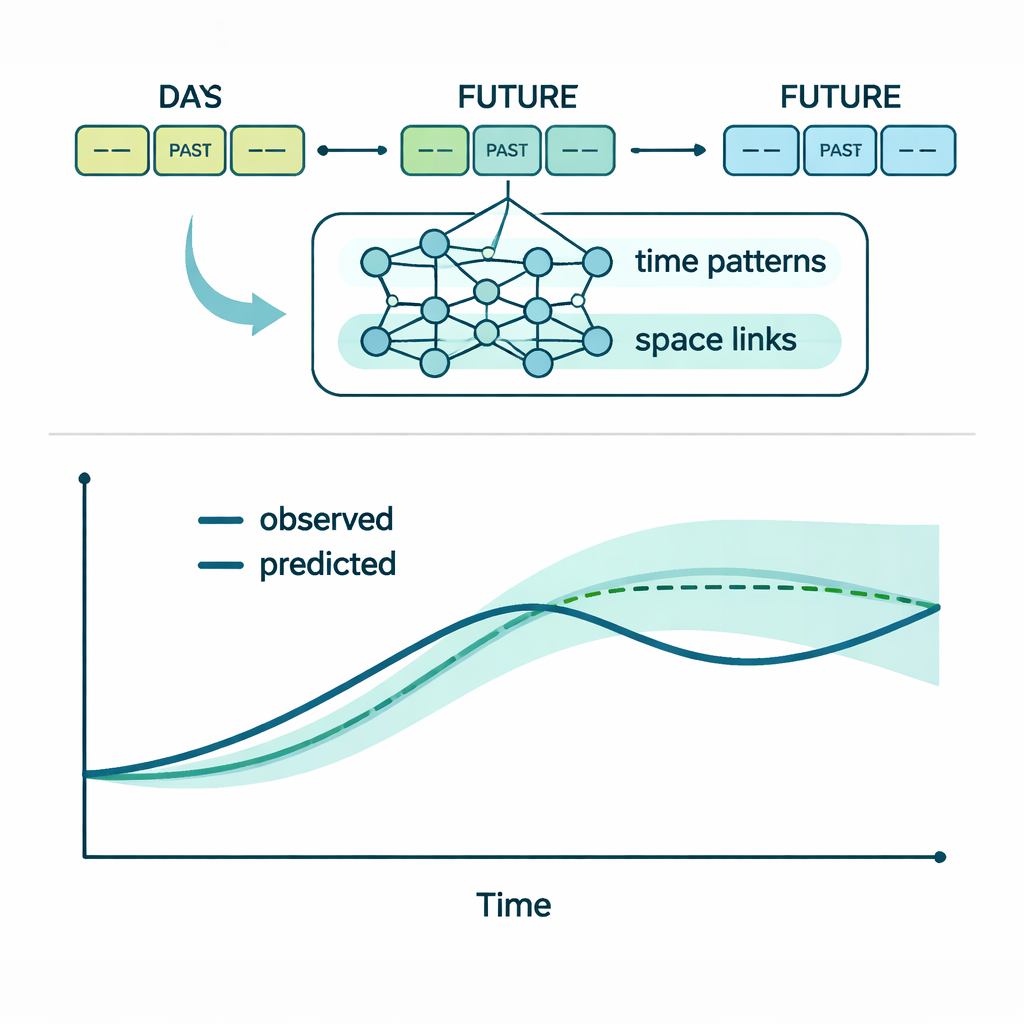
Dentro del marco MLA-Mamba, el módulo «Mamba» se concentra en la narrativa temporal. Escudriña largas secuencias de mediciones, empleando ideas de modelos de estado y de redes recurrentes modernas para conservar información de días anteriores sin saturarse. Esto le ayuda a reconocer patrones estacionales e impactos persistentes de perturbaciones pasadas. En paralelo, un módulo de «Atención Local Multicabeza» pondera cuán fuerte se relaciona cada estación con las demás en un momento dado, con un sesgo incorporado hacia sitios próximos en el mismo tramo del río. Si una estación aguas arriba registra de pronto un aumento de amonio, el mecanismo de atención puede cambiar rápidamente el foco a esa señal al predecir condiciones río abajo. Una configuración de aprendizaje multitarea permite al modelo aprender los cuatro indicadores juntos, de modo que los cambios en un contaminante pueden informar las expectativas sobre los otros.
Entrenamiento más inteligente para datos ambientales ruidosos
Entrenar una red así con registros de sensores del mundo real es complicado: los datos son ruidosos, hay huecos y los métodos de optimización estándar pueden atascarse. Para abordar esto, los investigadores introducen una estrategia de entrenamiento personalizada que llaman Optimización por Reparametrización del Gradiente (GRPO). GRPO ajusta la velocidad de aprendizaje de cada parámetro en la red según cómo se comporte su gradiente a lo largo del tiempo, acelerando en direcciones estables y ralentizando cuando las actualizaciones comienzan a oscilar. También aplica un tamaño de paso mínimo para que el aprendizaje no se detenga en zonas planas de la superficie de error. El equipo además usa dropout no sólo para evitar el sobreajuste sino también para estimar la incertidumbre, ejecutando el modelo varias veces y examinando cuánto varían sus predicciones. Esto produce bandas de confianza alrededor de cada pronóstico, dando a los gestores una idea de cuán fiables son las predicciones particulares.
Poner el modelo a prueba
Los autores evalúan MLA-Mamba con varios años de datos horarios de dos estaciones fluviales en China, una aguas arriba de la otra. El modelo toma los siete días previos de datos y predice los siguientes tres días. Se compara frente a ocho alternativas, que van desde métodos estadísticos clásicos hasta arquitecturas modernas de aprendizaje profundo como redes LSTM (long short-term memory), híbridos convolucional–recurrentes y modelos Transformer. En los cuatro indicadores y en ambas ubicaciones, MLA-Mamba ofrece sistemáticamente los errores de predicción más bajos. En muchos casos reduce los errores típicos entre un 10 y un 20 por ciento respecto a robustas líneas base de aprendizaje profundo. Cuando se desactivan partes del modelo en pruebas controladas —eliminando la atención espacial, sustituyendo un LSTM estándar por el módulo Mamba, apagando el optimizador GRPO o entrenando cada indicador por separado—, el rendimiento se deteriora de forma notable. Esto demuestra que cada ingrediente contribuye a las mejoras.
Qué supone esto para la protección de los recursos hídricos
En términos sencillos, el estudio demuestra que una red neuronal híbrida diseñada a medida puede ofrecer pronósticos a corto plazo de la contaminación fluvial más precisos y fiables que las herramientas habituales. Al seguir simultáneamente múltiples contaminantes en varias estaciones y al cuantificar la certeza de sus propias predicciones, el marco MLA-Mamba podría sostener sistemas de alerta temprana que activen inspecciones o controles temporales antes de que se superen umbrales críticos. Aunque el enfoque sigue dependiendo de datos de monitorización de buena calidad y debe probarse en más ríos y en eventos extremos, ofrece una vía prometedora hacia una gestión de aguas superficiales más inteligente y basada en datos.
Cita: Wei, R., Chen, H. & Wang, H. Surface water quality prediction via an MLA-Mamba hybrid neural network with GRPO optimization. Sci Rep 16, 5845 (2026). https://doi.org/10.1038/s41598-026-36229-3
Palabras clave: pronóstico de la calidad del agua, contaminación fluvial, aprendizaje profundo, modelado espacio-temporal, vigilancia ambiental