Clear Sky Science · es
Modelado de contexto a largo alcance para la detección de vulnerabilidades de software usando un enfoque basado en XLNet
Por qué importan los fallos ocultos en el software
La vida moderna depende del software, desde la banca en línea y los sistemas hospitalarios hasta los reproductores de vídeo y las aplicaciones de mensajería. Sin embargo, incluso errores mínimos en el código pueden abrir la puerta a atacantes, con el riesgo de robo de datos o interrupciones del servicio. Los expertos en seguridad recurren cada vez más a la inteligencia artificial para escanear millones de líneas de código en busca de esas debilidades. Este artículo explora un nuevo método basado en IA, llamado XLNetVD, diseñado para detectar vulnerabilidades sutiles del software leyendo tramos de código mucho más largos que los que pueden manejar muchas herramientas existentes.
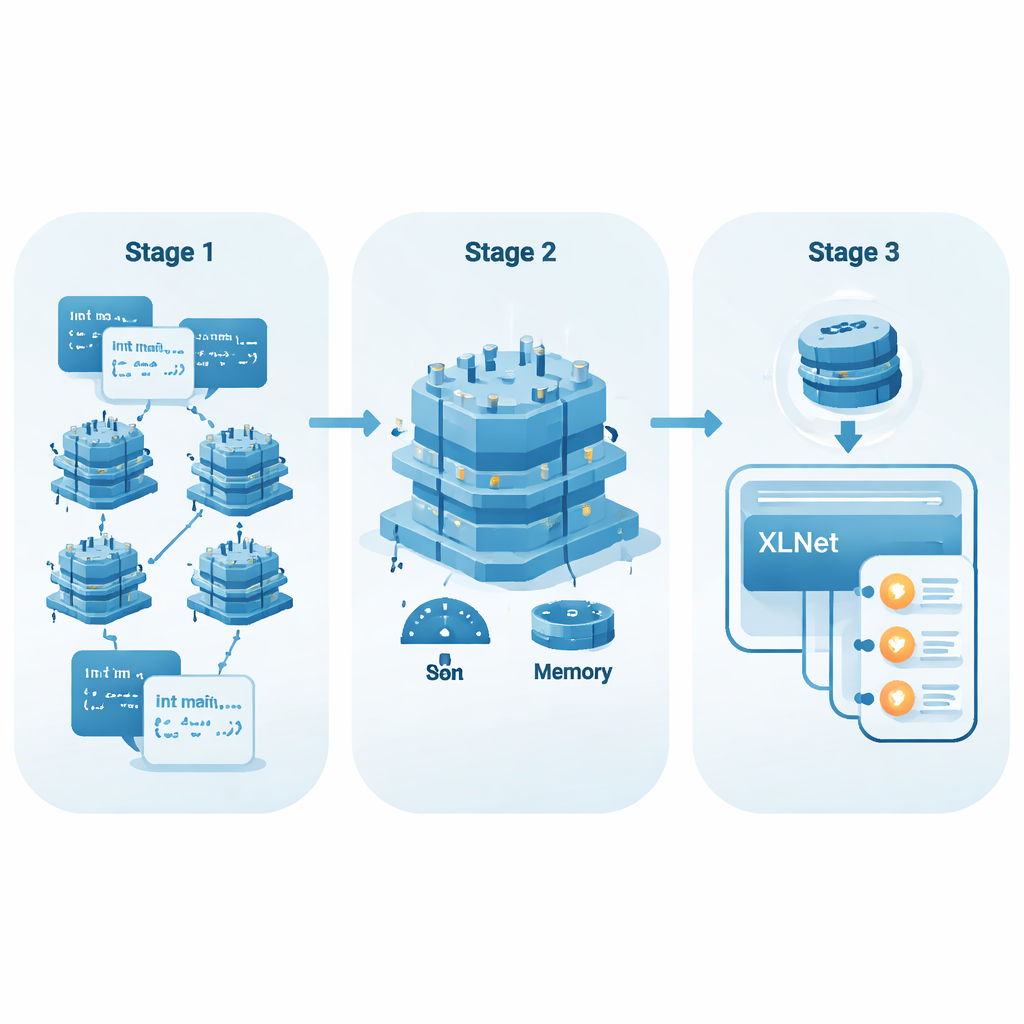
De listas de palabras simples a código que entiende el contexto
Los primeros métodos de IA para analizar código trataban cada token —como un nombre de variable o un símbolo— casi como una palabra de diccionario con un significado fijo. Técnicas como Word2Vec o GloVe aprendían un vector por token, independientemente de dónde apareciera. Eso funciona razonablemente bien para el lenguaje natural, pero se queda corto para los programas, donde el mismo nombre de variable puede comportarse de forma muy distinta según dónde y cómo se use. Los modelos más recientes, conocidos como modelos de incrustación contextual, en cambio analizan la función completa a la vez y ajustan la representación de cada token según su entorno. Esto les permite captar patrones relacionados con el flujo de datos, el flujo de control y las dependencias entre variables, patrones que a menudo marcan la diferencia entre código seguro e inseguro.
Permitir que la IA lea más del archivo
Modelos de código populares como CodeBERT y GraphCodeBERT ya usan este enfoque consciente del contexto, pero suelen limitar su “visión” a unos 512 tokens. Para funciones largas, o para vulnerabilidades que se manifiestan en partes del código separadas entre sí, esa ventana puede quedarse corta. Comprobaciones importantes cerca del inicio de una función pueden quedar desconectadas de operaciones riesgosas hacia el final. Los autores, en cambio, se apoyan en XLNet, un modelo basado en Transformer-XL, que puede recordar información a través de segmentos y procesar cómodamente secuencias más largas (hasta 768 tokens en sus experimentos). Esto lo hace más adecuado para enlazar eventos distantes en el código —por ejemplo, entender que un valor fue validado antes o darse cuenta de que nunca lo fue.
Hacer modelos potentes más ligeros y rápidos
Los grandes modelos de IA a menudo exigen hardware potente, lo que limita su uso en entornos de desarrollo cotidianos. Para abordarlo, los autores aplican un método de ajuste fino llamado Low-Rank Adaptation (LoRA). En lugar de cambiar todos los numerosos parámetros de XLNet, LoRA añade pequeñas capas adaptadoras que son mucho más baratas de entrenar y almacenar. El equipo presenta una métrica simple, EffScore, que pondera cuánto se ahorra en memoria y tiempo frente a cualquier caída en la calidad de detección. Entre varios modelos líderes, XLNet con LoRA se revela como el más eficiente en conjunto, ofreciendo una buena precisión mientras usa recursos significativamente menores.
Pruebas en proyectos reales y sintéticos
Los investigadores evalúan XLNetVD en dos conjuntos de datos muy diferentes. Uno consiste en código C real de 12 proyectos de código abierto —como bibliotecas multimedia y servidores web— con una proporción extremadamente sesgada de aproximadamente 1 función vulnerable frente a 65 no vulnerables, reflejando la realidad de grandes bases de código. El otro es una colección sintética equilibrada del proyecto SARD, donde cada función está diseñada para representar un tipo de debilidad conocido. XLNetVD no solo iguala o supera a sistemas previos de aprendizaje profundo y a herramientas clásicas de análisis estático en estas pruebas, sino que también rinde bien en escenarios interproyecto, donde debe encontrar fallos en un proyecto que no ha visto antes. Su ventaja es especialmente notable en funciones largas, donde el contexto extendido es crucial, y a lo largo de diversas categorías de vulnerabilidades, incluyendo desbordamientos enteros, mala gestión de recursos y manejo inadecuado de entradas.
Qué significa esto para la seguridad del software cotidiana
Para un público no especializado, el mensaje central es que una IA más inteligente y consciente del contexto puede leer y razonar sobre el código de forma más parecida a un revisor humano experimentado, pero a escala de máquina. Al permitir que el modelo vea más de cada función y afinándolo de manera eficiente, XLNetVD ofrece un modo práctico de priorizar qué partes de una enorme base de código merecen una inspección humana más detallada. No sustituye a las auditorías de seguridad manuales ni a los métodos formales, y no puede garantizar que el software esté libre de errores. Sin embargo, mejora significativamente las probabilidades de detectar errores peligrosos tempranamente, incluso en proyectos desconocidos, lo que lo convierte en un componente prometedor para una infraestructura digital más fiable y segura.
Cita: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Palabras clave: vulnerabilidades de software, seguridad del código, aprendizaje profundo, XLNet, ajuste fino LoRA