Clear Sky Science · es
Algoritmo DDPG priorizado modificado para la optimización conjunta de beamforming y fases RIS en sistemas MISO de enlace descendente
Superficies inteligentes para la próxima ola inalámbrica
A medida que nuestros teléfonos, coches y sensores exigen conexiones cada vez más rápidas y fiables, las redes inalámbricas actuales se ven empujadas a sus límites. Este estudio explora una nueva forma de hacer que las futuras redes 6G sean a la vez más sostenibles y más fiables combinando superficies reflectantes "inteligentes" en edificios con una técnica de inteligencia artificial que aprende por sí sola a dirigir las señales de radio consumiendo menos energía.
Convertir paredes en espejos útiles para las señales
Los futuros sistemas 6G deben atender a un gran número de dispositivos con altas tasas de datos, fiabilidad sólida y latencias muy bajas. Satisfacer todas esas demandas solo con estaciones base tradicionales requeriría mucho hardware y energía adicionales. Las Superficies Inteligentes Reconfigurables (RIS) ofrecen un enfoque distinto: paneles revestidos con muchos elementos diminutos y de bajo consumo que pueden reflejar ondas de radio entrantes en direcciones controladas, como un espejo programable. Al elegir cuidadosamente las fases de esas reflexiones, un RIS puede redirigir señales alrededor de obstáculos, reforzar enlaces débiles y reducir la interferencia, todo ello sin transmitir activamente su propia potencia. Esto proporciona a los diseñadores de redes un nuevo control poderoso a la hora de ampliar la cobertura y mejorar la eficiencia.
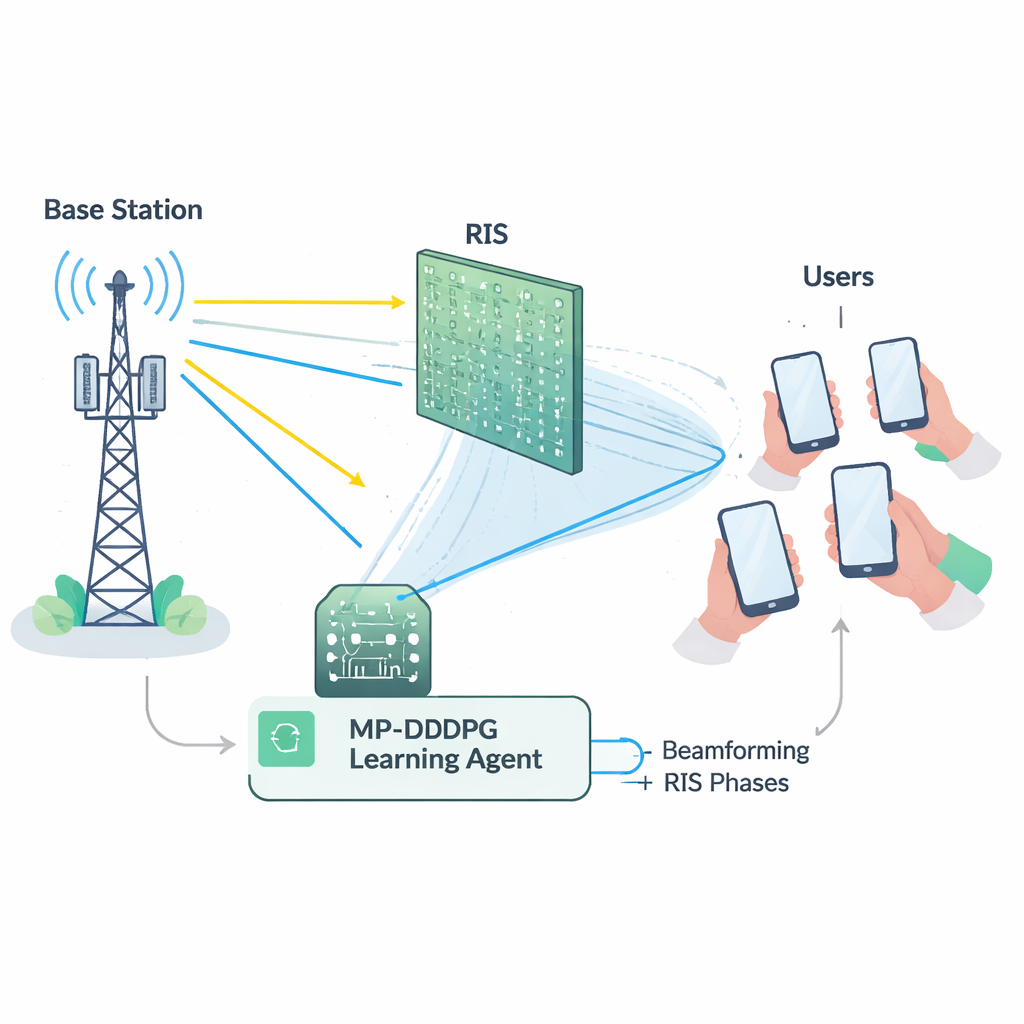
Un acto de equilibrio difícil para la red
Hacer buen uso de un RIS no es sencillo. La estación base debe decidir cómo orientar sus antenas (beamforming), mientras que el RIS tiene que ajustar la fase de cada uno de sus numerosos elementos reflectantes. Estas decisiones están estrechamente conectadas y deben cumplir varios límites a la vez: mantener la potencia de transmisión total por debajo de un máximo, garantizar a cada usuario una calidad mínima de señal y respetar los límites físicos del hardware RIS. Matemáticamente, este problema de ajuste conjunto es altamente no lineal y "no convexo", lo que significa que las herramientas de optimización convencionales tienden a ser lentas, frágiles o a quedarse en soluciones subóptimas, especialmente a medida que las redes crecen. Además, medir con precisión el estado detallado de cada enlace radio (la llamada información de estado de canal) es en sí costoso y propenso a errores en despliegues reales.
Dejar que un agente de IA aprenda a dirigir los haces
Para superar estos obstáculos, los autores construyen un agente de aprendizaje usando aprendizaje profundo por refuerzo, una rama de la IA donde un agente descubre buenas estrategias por ensayo y error con un entorno. Su método, llamado DDPG Determinista Profundo Prioritizado Modificado (MP‑DDPG), observa el estado actual de la red—direcciones de haz previas, configuraciones RIS, potencia recibida y calidad de la señal—y luego elige nuevos valores de beamforming y fases del RIS. Tras cada decisión, recibe una recompensa que fomenta tres cosas a la vez: reducir la potencia de transmisión, cumplir los objetivos de calidad de servicio para los usuarios y respetar el límite de potencia de la estación base. A lo largo de muchas interacciones simuladas, el agente aprende gradualmente una política de control que equilibra esos objetivos sin que se le indique explícitamente ninguna fórmula del canal radiofónico.
Aprender más rápido centrando la atención en lo importante
La innovación clave reside en cómo el algoritmo aprende de su experiencia pasada. Los enfoques estándar almacenan muchas situaciones anteriores y las toman de forma aleatoria durante el entrenamiento, lo que puede ser ineficiente y lento. MP‑DDPG, en cambio, asigna a cada experiencia almacenada una prioridad que depende tanto de su recompensa como de lo diferente que es su estado respecto a sus vecinos más cercanos. Las experiencias que son informativas y diversas se muestrean con más frecuencia, mientras que las redundantes se ignoran. Este "replay priorizado modificado" hace que cada paso de aprendizaje sea más útil, acelerando la convergencia y ayudando al agente a evitar soluciones locales pobres. Los autores también analizan el cómputo extra que esto añade y muestran que, aunque la contabilidad es más compleja que en el método básico, el aprendizaje más rápido compensa con creces ese coste en la práctica.
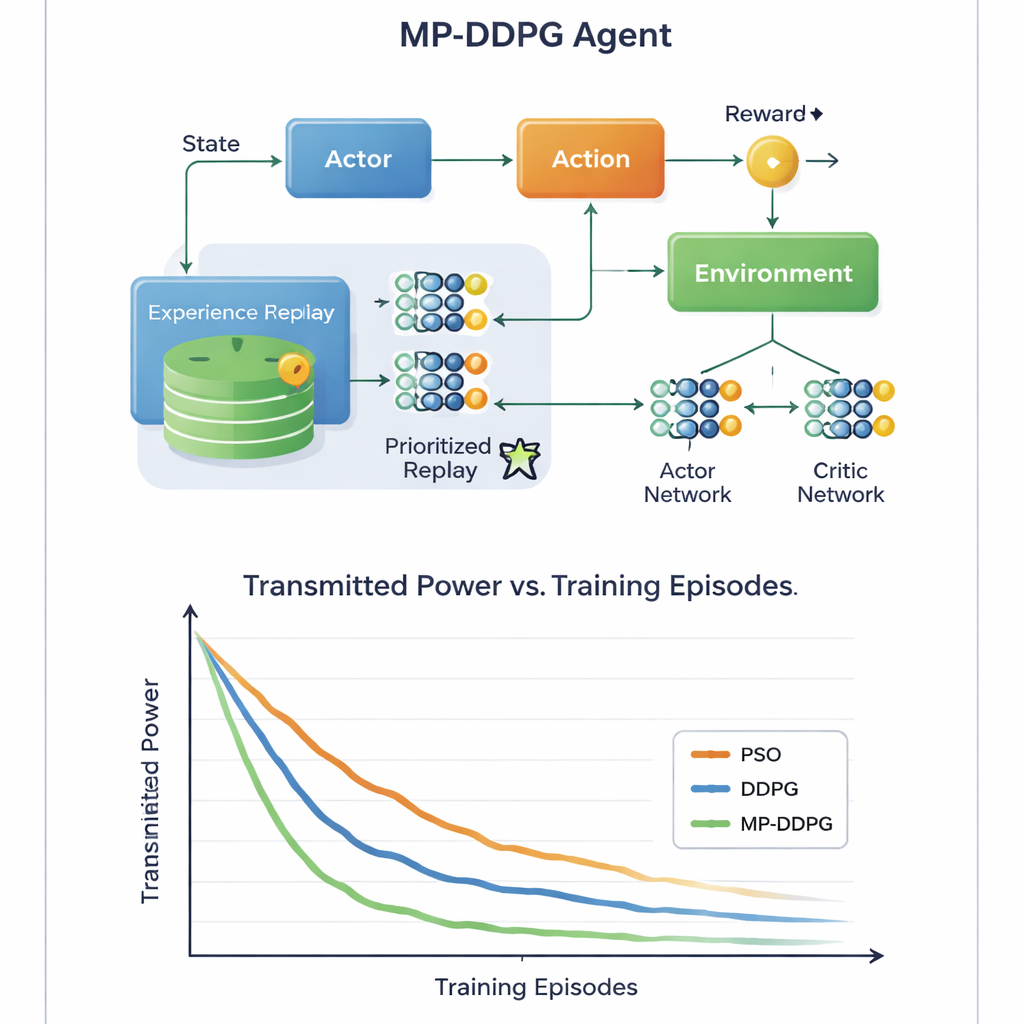
Señales más ecológicas con menos hardware
A través de simulaciones por ordenador detalladas de un escenario celular de enlace descendente, el estudio compara MP‑DDPG con dos alternativas: un método tradicional de optimización por enjambre de partículas y el algoritmo DDPG original. El nuevo método alcanza sistemáticamente menor potencia de transmisión en menos episodios de entrenamiento, y lo hace usando menos elementos RIS y menos antenas en la estación base para el mismo nivel de rendimiento. En términos sencillos, la red aprende a sacar más provecho de cada azulejo reflectante y de cada antena. Para un lector no especializado, el mensaje es que, al permitir que un controlador de IA ajuste con inteligencia tanto los haces de la estación base como las superficies inteligentes en las paredes cercanas, las futuras redes 6G podrían ofrecer señales fuertes y fiables usando menos energía y menos hardware, contribuyendo a que nuestro mundo cada vez más conectado sea más sostenible.
Cita: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Palabras clave: superficie inteligente reconfigurable, 6G inalámbrico, aprendizaje profundo por refuerzo, optimización de beamforming, redes energéticamente eficientes