Clear Sky Science · es
Predicción mediante aprendizaje automático de la adicción a la comida en estudiantes universitarios usando rasgos demográficos, antropométricos y de personalidad
Por qué nuestra relación con la comida puede sentirse fuera de control
Mucha gente bromea sobre estar “enganchada” al chocolate o a la comida rápida, pero para algunas personas los antojos y la pérdida de control con la comida son reales y angustiosos. Los estudiantes universitarios son especialmente vulnerables, ya que manejan el estrés, nuevas libertades y cuerpos que cambian. Este estudio plantea una pregunta oportuna: ¿pueden los programas informáticos aprender a identificar qué estudiantes tienen mayor riesgo de adicción a la comida utilizando información sencilla sobre su entorno, medidas corporales y personalidad? Si es así, podríamos llegar a detectar problemas antes y ofrecer apoyo personalizado antes de que los hábitos alimentarios desemboquen en problemas de salud a largo plazo.
Analizando a los estudiantes desde varios ángulos
Los investigadores trabajaron con 210 estudiantes universitarios en Ahvaz, Irán, de entre 18 y 35 años. Cada alumno facilitó datos básicos como edad y nivel educativo, informó su altura y peso para calcular el índice de masa corporal (IMC) y completó un cuestionario estándar de personalidad. También se les evaluó con una breve versión de la Yale Food Addiction Scale, que clasifica si alguien muestra patrones parecidos a la adicción hacia alimentos altamente apetecibles, como antojos intensos, intentos fallidos de reducir el consumo o comer pese a las consecuencias negativas. Sólo 30 estudiantes cumplían los criterios de adicción a la comida, mientras que 180 no, lo que refleja cómo este problema afecta a una porción menor de la población.
Equilibrando datos desiguales y entrenando máquinas inteligentes
Como un número mucho menor de estudiantes fue clasificado como adicto a la comida, el conjunto de datos estaba desequilibrado. Este desequilibrio puede engañar a los modelos informáticos para que predigan mayoritariamente el grupo dominante e ignoren la minoría de alto riesgo. Para contrarrestarlo, el equipo usó dos técnicas de manejo de datos. Primero aplicaron un método llamado Tomek Links para eliminar cuidadosamente casos confusos del grupo mayoritario que estaban demasiado cerca de los casos minoritarios. Luego usaron SMOTE, que crea ejemplos sintéticos realistas del grupo minoritario, para igualar las cifras. Solo los datos de entrenamiento se alteraron de este modo; se reservó un grupo de prueba sin tocar para comprobar cómo funcionaban los modelos con estudiantes nuevos y no vistos.
Poniendo a prueba muchos algoritmos
Los investigadores no se fiaron de una única receta matemática. En su lugar compararon diez modelos diferentes de aprendizaje automático, desde métodos simples como la regresión logística y k‑vecinos más cercanos hasta métodos “ensemble” más avanzados como Random Forest, Gradient Boosting, LightGBM y CatBoost. También probaron doce estrategias de selección de características para decidir qué preguntas y mediciones eran más informativas, y usaron validación cruzada y búsquedas automatizadas para ajustar los parámetros de cada modelo. El rendimiento global se juzgó mediante varias medidas, incluyendo la exactitud (qué tan a menudo el modelo acertaba), la puntuación F1 (un equilibrio entre detectar casos verdaderos sin demasiadas falsas alarmas) y el área bajo la curva ROC, que captura qué tan bien un modelo separa a los individuos de mayor riesgo de los de menor riesgo.
Qué impulsa las predicciones bajo el capó
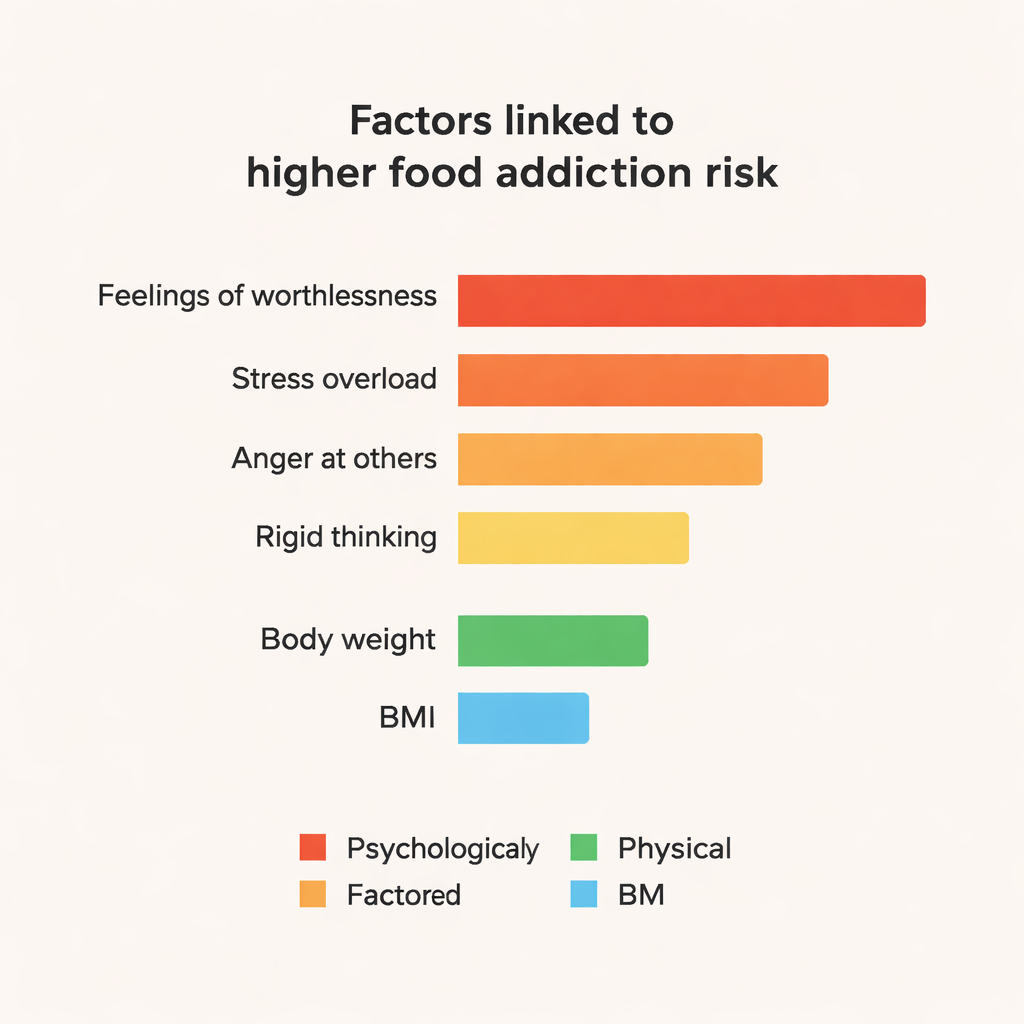
Los modelos ensemble, especialmente CatBoost y Random Forest, superaron de forma consistente a los enfoques más simples, alcanzando alrededor del 84% de precisión y puntuaciones F1 de aproximadamente 0,84 en este pequeño conjunto de datos. Para ir más allá de las predicciones en “caja negra”, el equipo utilizó una herramienta llamada SHAP para explorar qué características empujaban al modelo a etiquetar a alguien como adicto a la comida. Las influencias más destacadas fueron psicológicas: afirmaciones fuertes como “A veces me siento completamente inútil”, sensación de “desmoronarse” bajo estrés, enfado frecuente por cómo les tratan los demás, tensión emocional y pensamiento rígido e inflexible. El peso corporal y el IMC también importaron, pero fueron menos centrales que estas señales emocionales y de personalidad. Rasgos vinculados a un estado de ánimo positivo y una buena organización mostraron un leve efecto protector.
Qué significa esto para la vida cotidiana
Para el lector medio, el mensaje clave es que la adicción a la comida no se reduce simplemente a la fuerza de voluntad o a que a alguien le gusten los bocados sabrosos. En este grupo piloto de estudiantes, las luchas emocionales más profundas —baja autoestima, dificultad para manejar el estrés y relaciones tensionadas— estaban estrechamente entrelazadas con la alimentación problemática. Las versiones iniciales de las herramientas de aprendizaje automático, alimentadas con cuestionarios básicos y medidas corporales, pudieron captar estos patrones con una precisión alentadora. Sin embargo, los autores subrayan que su muestra fue pequeña, basada en autoinformes y procedente de una única universidad, por lo que los resultados son preliminares. Con estudios más grandes y diversos, modelos similares podrían eventualmente usarse junto con evaluaciones clínicas estándar para identificar a jóvenes que podrían beneficiarse de apoyo para manejar tanto sus emociones como sus hábitos alimentarios.
Cita: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Palabras clave: adicción a la comida, estudiantes universitarios, rasgos de personalidad, aprendizaje automático, alimentación emocional