Clear Sky Science · es
Integración de optimización y aprendizaje automático para estimar la resistividad del agua y la saturación en yacimientos de arenas limosas
Por qué esto importa para la energía y el medio ambiente
Las compañías de petróleo y gas dependen de mediciones en el pozo para decidir dónde se encuentran los hidrocarburos y si conviene desarrollar un yacimiento. En muchos reservorios, especialmente aquellos ricos en arcilla y limo, estas mediciones son notoriamente difíciles de interpretar, por lo que los ingenieros pueden subestimar la cantidad real de petróleo o gas. Este estudio presenta una nueva forma de extraer información más confiable de datos existentes combinando optimización basada en física con aprendizaje automático moderno, lo que puede mejorar la recuperación y reducir la necesidad de costosas muestras de testigo.
El problema de las rocas limosas
Muchos de los reservorios de hidrocarburos del mundo son “arenas limosas”: mezclas de granos de arena, fluidos de pore y minerales arcillosos conductores. Estas arcillas distorsionan las medidas eléctricas usadas para estimar cuánto del espacio poroso está lleno de agua frente a hidrocarburos. Las herramientas y gráficos clásicos, desarrollados para arenas más limpias, asumen estructuras rocosas sencillas y poca arcilla. En las arenas limosas esas suposiciones se rompen, con frecuencia haciendo que las rocas parezcan más húmedas de lo que son y llevando a los ingenieros a descartar intervalos que pueden contener cantidades significativas de petróleo o gas.
Convertir mediciones escasas en un ancla sólida
Los autores abordan una magnitud central llamada resistividad del agua de formación, que describe qué tan bien el agua en los poros conduce la electricidad. Si este valor está equivocado, todas las estimaciones de saturación de agua posteriores se sesgan. En lugar de depender de unas pocas mediciones de laboratorio o métodos gráficos subjetivos, plantean el problema como una tarea de optimización: encontrar un único valor de resistividad del agua que haga que un modelo físico de arena limosa coincida lo mejor posible con la resistividad medida a lo largo del pozo. Prueban varios algoritmos de búsqueda y muestran que métodos sencillos sin derivados, como Powell y Nelder–Mead, pueden recuperar la resistividad verdadera con un error extremadamente pequeño al compararla con datos de testigos y muestras de agua de 11 pozos en el Mar del Norte noruego y el Desierto Occidental de Egipto.
Crear un registro de “pseudo-testigo” para aprendizaje automático
Una vez obtenida esta resistividad del agua optimizada, el mismo modelo físico se usa para calcular un perfil continuo de saturación de agua a lo largo de cada pozo. Este perfil se trata como una etiqueta de alta calidad informada por la física —una especie de “pseudo-testigo”— que existe en todas las profundidades, no solo en unos pocos intervalos muestreados. Los investigadores alimentan entonces registros de pozo estándar, como gamma ray, porosidad por neutrones, densidad y resistividad profunda, a una amplia gama de modelos de aprendizaje automático. Estos incluyen ensamblados basados en árboles (Random Forest, XGBoost, CatBoost), máquinas de soporte vectorial y varias arquitecturas de redes neuronales, incluida una red recurrente especial llamada LSTM que puede reconocer patrones que evolucionan con la profundidad. Un preprocesado cuidadoso, la detección de valores atípicos y la normalización ayudan a garantizar que los modelos aprendan relaciones geológicas genuinas en lugar de ruido.
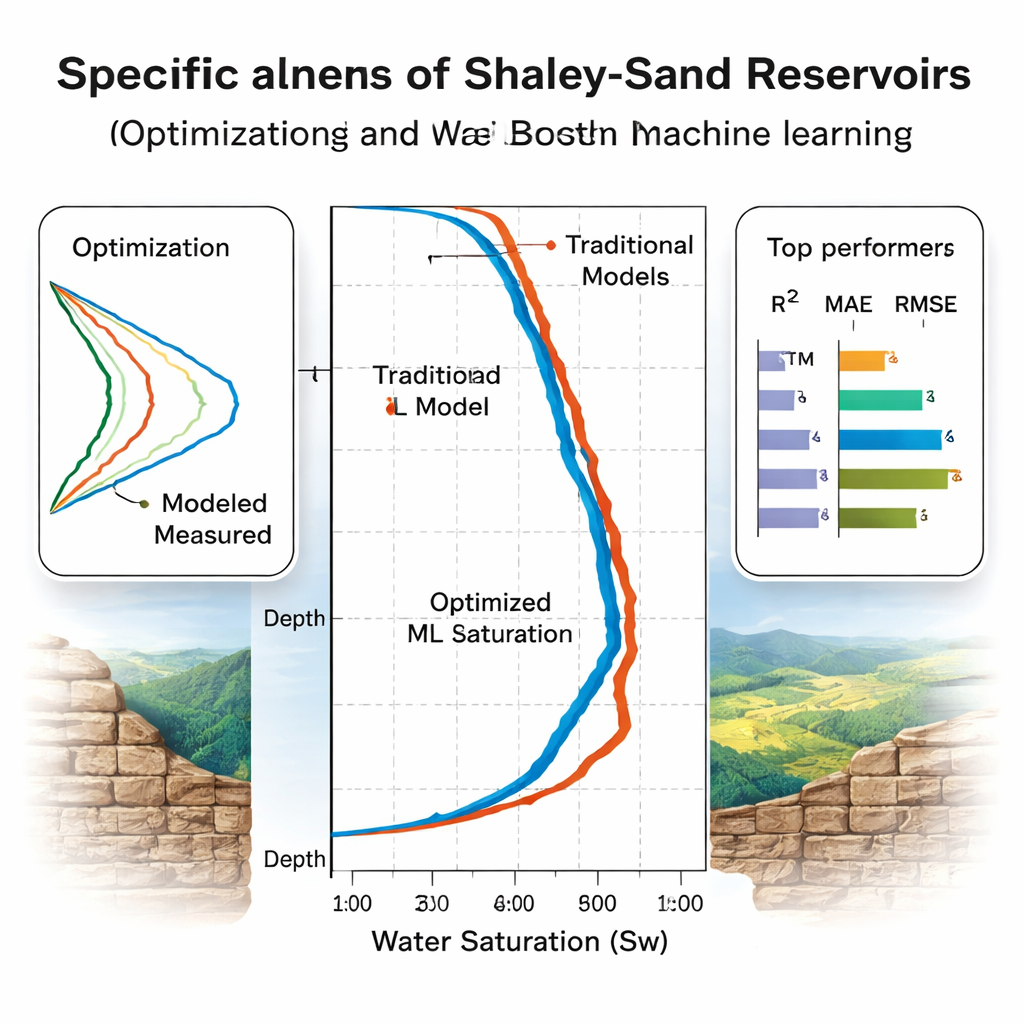
¿Qué modelos generalizan realmente?
El equipo evalúa los modelos en dos etapas. Primero, usan validación cruzada de cinco pliegues en ocho pozos del Mar del Norte para ajustarlos y clasificarlos, encontrando que Random Forest parece ganar en las puntuaciones de precisión estándar. Luego viene la prueba más reveladora: tres pozos “ciegos”, incluidos dos de una cuenca egipcia geológicamente distinta que nunca se usaron en el entrenamiento. Aquí, algunos modelos fallan. El rendimiento de Random Forest cae, indicando sobreajuste a la cuenca original. En contraste, los árboles con impulso por gradiente (CatBoost y XGBoost) y las redes LSTM y las redes neuronales regularizadas bayesianamente mantienen alta precisión, explicando más del 93–94% de la variación en la saturación de agua con errores modestos. Un análisis de importancia de características usando SHAP, una herramienta moderna de interpretabilidad, confirma que los modelos se basan principalmente en entradas físicamente sensatas como resistividad, porosidad y volumen de lutita.
Qué significa esto en términos sencillos
Para no especialistas, la idea clave es que los autores primero usan la física para limpiar y anclar el problema, y solo después aplican aprendizaje automático. Al dejar que una rutina de optimización encuentre la resistividad del agua que mejor ajusta y convertir eso en un conjunto de entrenamiento denso y respetuoso de la física, evitan el habitual cuello de botella de datos de testigo escasos y caros. Sus resultados muestran que este enfoque “optimización primero, ML después” puede ofrecer estimaciones confiables de cuánto de un yacimiento limoso está llenado por agua frente a hidrocarburos, incluso en cuencas nuevas no usadas en el entrenamiento. En términos prácticos, esto puede ayudar a los operadores a mapear zonas con hidrocarburos de forma más fiable, reducir sondeos de testigo innecesarios y mejorar las estimaciones de hidrocarburos in situ, todo aprovechando mejor los datos que ya recopilan.
Cita: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Palabras clave: yacimientos de arenas limosas, saturación de agua, resistividad del agua de formación, aprendizaje automático en petrofísica, caracterización de yacimientos