Clear Sky Science · es
Integración de regresión kriging basada en random forest para analizar la variabilidad espacial de la precipitación en regiones áridas y semiáridas
Por qué importa mapear la lluvia en tierras secas
En países donde el agua escasea, saber con precisión dónde y cuándo llueve puede marcar la diferencia entre seguridad alimentaria y crisis. Pakistán abarca montañas, desiertos y llanuras fértiles, y su precipitación se ha vuelto más errática con el cambio climático. Sin embargo, las estaciones meteorológicas en tierra son pocas y están separadas por grandes distancias. Este estudio plantea una pregunta práctica: con datos limitados, ¿pueden los métodos modernos de aprendizaje automático combinados con técnicas clásicas de cartografía generar mapas de precipitación más nítidos y fiables que orienten la agricultura, la planificación ante inundaciones y la gestión del agua?
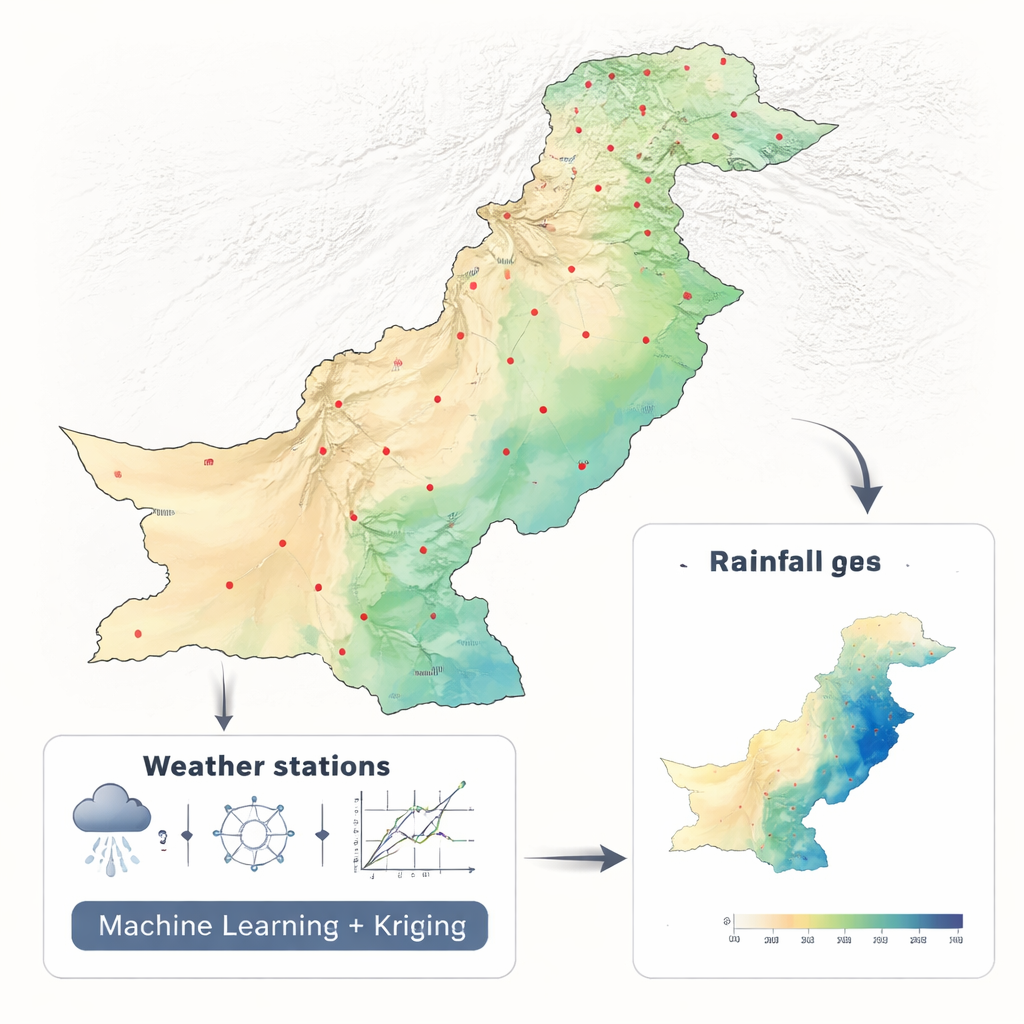
Convertir pluviómetros dispersos en mapas completos
Los investigadores trabajaron con dos décadas de datos mensuales de precipitación (2001–2010 y 2011–2021) de 42 estaciones en todo Pakistán, utilizando un conjunto de datos climáticos consistente de la NASA. En lugar de alimentar docenas de variables ambientales en un modelo complejo, usaron deliberadamente solo la latitud y la longitud. Este diseño simplificado les permitió centrarse en un asunto clave: qué enfoque matemático convierte mejor mediciones puntuales dispersas en un mapa continuo. Compararon seis métodos de aprendizaje automático—Random Forest, Support Vector Machine, K-Nearest Neighbors, Red Neuronal, Elastic Net y Regresión Polinómica—cada uno integrado en un marco llamado regresión kriging, ampliamente utilizado en las geociencias.
Combinar el aprendizaje estilo big data con la intuición espacial
La regresión kriging funciona en dos etapas. Primero, un modelo de regresión predice la precipitación en cualquier ubicación a partir de sus coordenadas, capturando patrones amplios como montañas más húmedas y desiertos más secos. Segundo, un método espacial llamado kriging rellena las diferencias residuales, con patrones locales, entre las observaciones y las predicciones. Para que ese segundo paso fuera fiable, el equipo estudió primero cómo de similares o diferentes eran las precipitaciones entre pares de estaciones a distintas distancias—una herramienta llamada variograma. Encontraron que formas matemáticas simples, “circular” y “lineal”, describían mejor cómo la similitud de la lluvia se atenúa con la distancia a lo largo de las estaciones y entre las dos décadas, lo que indica sistemas de lluvia suaves y regionales más que saltos abruptos.
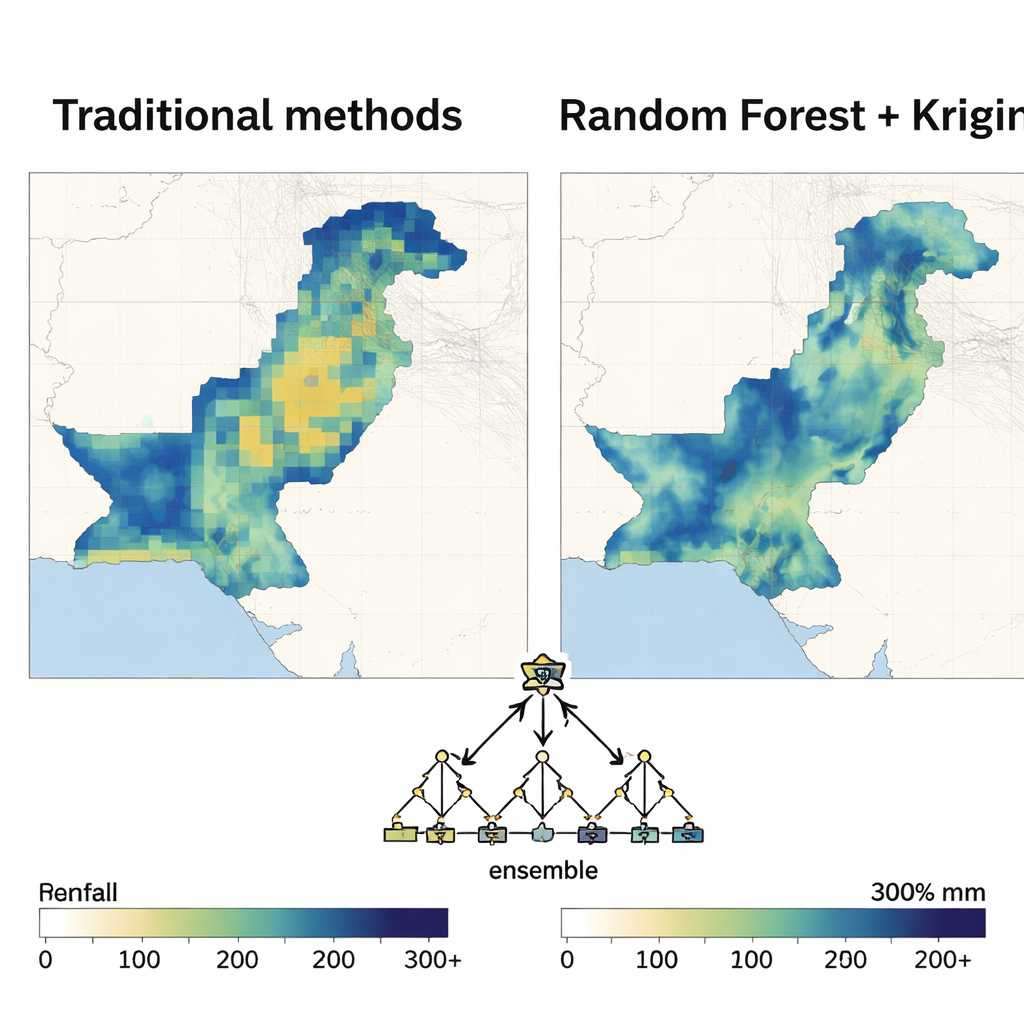
Random Forest emerge como el favorito
Una vez definida la estructura espacial, cada método de aprendizaje automático ejerció como motor de regresión dentro del modelo híbrido. Los autores evaluaron el rendimiento con indicadores habituales de error y con cuánto de la variación en la precipitación podía explicar el modelo. A lo largo de casi todos los meses y en ambas décadas, el enfoque basado en Random Forest produjo los mapas más precisos y estables. Redujo los errores de predicción mucho más que la regresión polinómica y superó de forma consistente a las máquinas de vectores de soporte, las redes neuronales y otros métodos, especialmente durante los meses del monzón, cuando la precipitación es más intensa y variable. Los mapas resultantes eran suaves donde debía serlo, pero aún captaban contrastes nítidos entre zonas secas y húmedas, con incertidumbre relativamente baja.
Lo que revelan los cambios en los patrones de lluvia
Al comparar las dos décadas, el estudio también observó indicios de un comportamiento de precipitación cambiante. De media, la década más reciente (2011–2021) fue más húmeda, con mayor variabilidad mes a mes y de un lugar a otro, sobre todo en primavera y durante el monzón. La estructura espacial de la precipitación se volvió más dispersa, lo que sugiere oscilaciones más amplias en dónde se entrega el agua. Importa que la combinación Random Forest–kriging manejó tanto el clima anterior, algo más moderado, como el periodo reciente más variable sin perder precisión, lo que insinúa que herramientas flexibles como estas son adecuadas para un mundo más cálido y menos predecible.
De los mapas a las decisiones sobre el terreno
En términos prácticos, el trabajo muestra que los algoritmos inteligentes pueden extraer más valor de registros de precipitación limitados, produciendo mapas de alta resolución útiles incluso en regiones con escasez de datos. Para Pakistán, estos mapas pueden respaldar una mejor planificación del riego, la gestión de embalses y las defensas contra inundaciones, y ayudar a identificar comunidades más expuestas a sequías o aguaceros intensos. Los autores subrayan que su trabajo es una prueba de concepto centrada en las técnicas de mapeo en sí, y no aún un sistema completo de alerta de inundaciones o sequías. Aun así, su conclusión es clara: combinar aprendizaje automático en ensamble, encabezado por Random Forest, con cartografía geoestadística ofrece una vía poderosa y práctica para seguir cómo cambia la lluvia en tierras áridas y semiáridas de todo el mundo.
Cita: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Palabras clave: mapeo de precipitaciones, random forest, regresión kriging, clima de Pakistán, recursos hídricos