Clear Sky Science · es
La base de reglas de creencias optimizada por múltiples parámetros para predecir el rendimiento estudiantil con interpretabilidad
Por qué predecir las notas es asunto de todos
Los boletines pueden parecer sencillos, pero las fuerzas que conforman las calificaciones de un estudiante distan mucho de serlo. Las escuelas recurren cada vez más a modelos informáticos para detectar a tiempo a quienes tienen dificultades y orientar el apoyo. Sin embargo, muchos de estos modelos son “cajas negras”: pueden ser precisos, pero ni profesores ni familias pueden ver por qué se produjo una predicción. Este artículo presenta un enfoque nuevo que busca ser a la vez muy preciso y fácil de entender, de modo que el personal educativo pueda confiar en sus resultados y actuar en consecuencia.
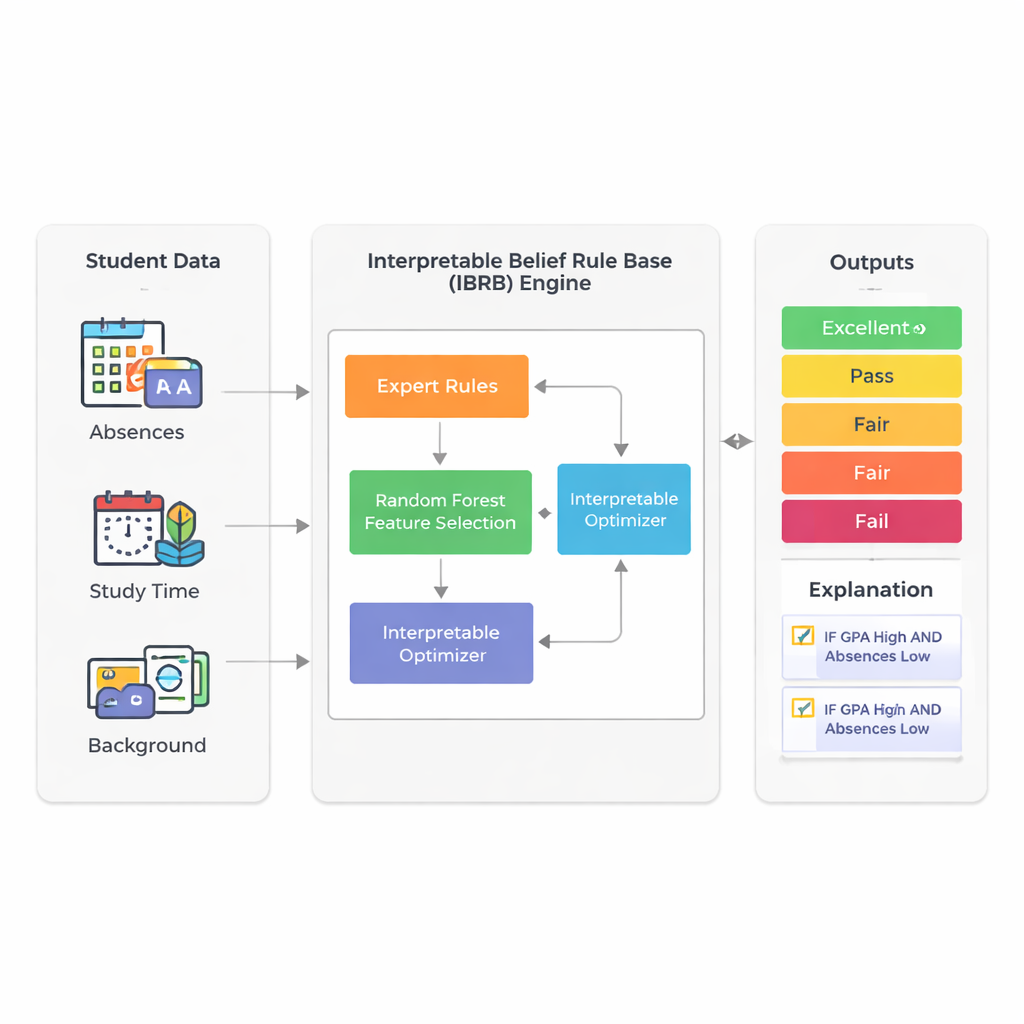
Una forma más inteligente de leer las señales
El estudio se centra en predecir cómo rendirán finalmente los estudiantes usando la información que las escuelas ya recopilan: promedio de calificaciones (GPA), ausencias, tiempo de estudio, antecedentes y factores familiares y de actividades. En lugar de depender de sistemas opacos de aprendizaje profundo, los autores se basan en una técnica llamada base de reglas de creencias. En este marco, los expertos redactan reglas que se parecen mucho a lo que diría un profesor: “Si el GPA es alto y las ausencias son pocas, entonces es probable que el estudiante tenga buen rendimiento”. Cada regla tiene un grado de creencia sobre posibles resultados como Excelente, Bueno, Aprobado, Regular o Suspenso. Esto hace que el proceso de razonamiento sea visible y, en principio, explicable a quienes no son especialistas.
Domar la complejidad sin perder el sentido
Un reto importante de los sistemas basados en reglas es que pueden descontrolarse cuando se incluyen muchos atributos del estudiante: cada factor adicional multiplica el número de reglas posibles. Para evitar esta “explosión de reglas”, los investigadores usan primero un random forest —un conjunto de árboles de decisión ampliamente utilizado— para medir qué características importan más para predecir el rendimiento. En su conjunto de datos real de 2.392 estudiantes procedente de una fuente pública, el GPA y el número de ausencias explican aproximadamente el 73% del poder predictivo del modelo. Al conservar deliberadamente solo estas dos entradas, el modelo final se mantiene compacto y más fácil de interpretar, sin dejar de reflejar la mayor parte de la variación en los resultados estudiantiles.
Construir reglas que la gente pueda seguir
El núcleo del nuevo modelo, llamado IBRB-m, es un conjunto cuidadosamente estructurado de 25 reglas que combinan niveles de GPA y ausencias con grados de creencia para las cinco categorías de rendimiento. Los autores formalizan qué significa que tal modelo sea “interpretable”. Entre sus requisitos: cada nivel de referencia (como “GPA bajo”) debe cubrir un intervalo claro y distinto; la base de reglas debe cubrir todas las combinaciones realistas de entradas; parámetros como los pesos de las reglas y los pesos de los atributos deben tener significados comprensibles; y los cálculos internos del sistema deben transformar la información de forma transparente y matemáticamente coherente. Además de estas condiciones tradicionales, añaden pautas específicas del ámbito educativo que obligan a que las predicciones sigan formas de sentido común —por ejemplo, evitando casos extraños en los que a un estudiante se le considere simultáneamente muy probable que sobresalga y que suspenda.
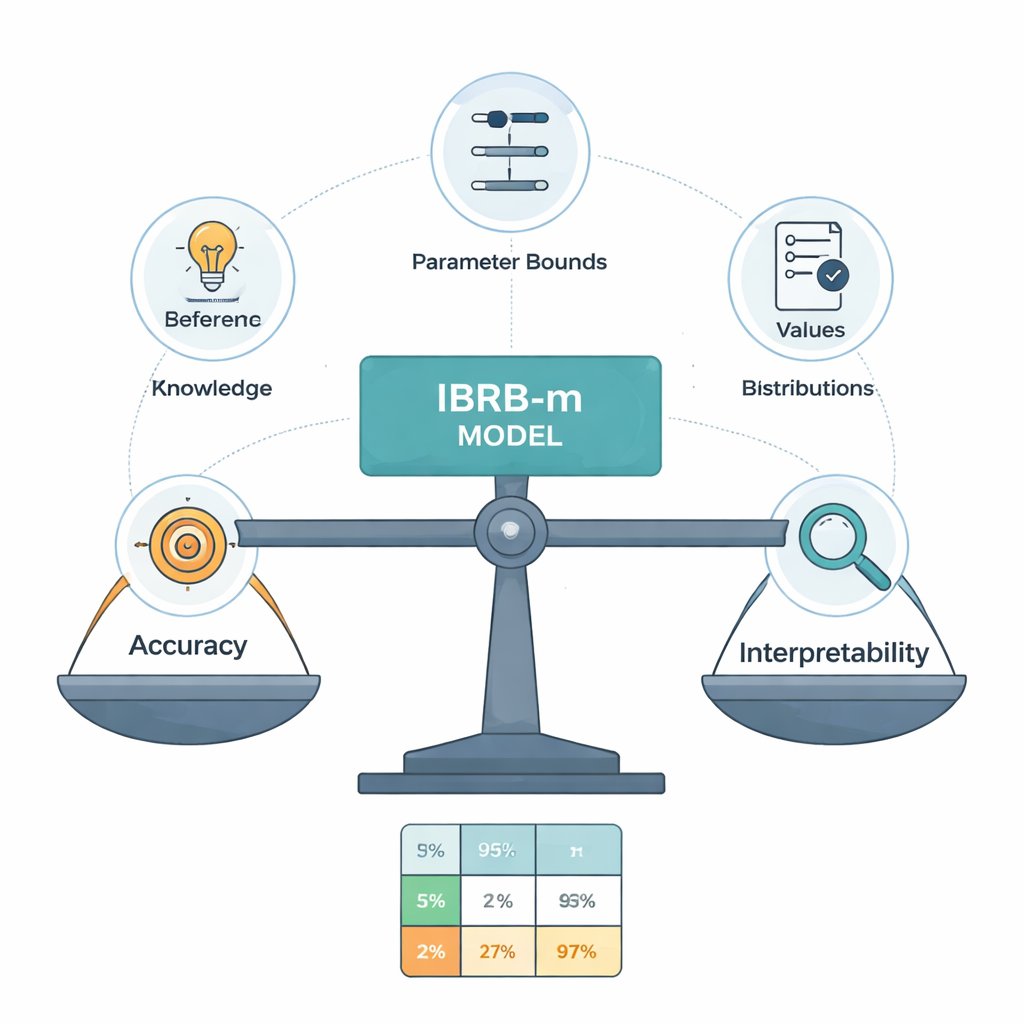
Permitir que los datos ajusten lo que dicen los expertos
Los expertos humanos no always concuerdan, y sus reglas iniciales pueden ser imprecisas. Para refinar esas reglas sin convertir el modelo en una caja negra, los autores diseñan un algoritmo de optimización mejorado que busca mejores valores de parámetros respetando estrictas restricciones de interpretabilidad. Este algoritmo ajusta no solo los pesos de las reglas y los grados de creencia, sino también los puntos de corte que definen categorías como Excelente o Aprobado. Mantiene todos los cambios dentro de los límites aprobados por expertos y aplica patrones de creencia razonables y suaves a lo largo de las calificaciones. En efecto, el ordenador “empuja” el sistema de expertos hacia una mayor precisión, pero no se le permite inventar reglas que desconcertarían a un profesor con experiencia.
¿Qué tan bien funciona en la práctica?
Probado con el conjunto de datos de rendimiento estudiantil de Kaggle, el modelo IBRB-m predice correctamente los niveles de rendimiento final en más del 99% de los casos, superando tanto a sistemas de reglas de creencias anteriores como a herramientas habituales de aprendizaje automático como redes neuronales, random forests y k-vecinos más cercanos. Igualmente importante, las reglas optimizadas permanecen cercanas a las evaluaciones expertas originales según una métrica de distancia simple, lo que significa que el razonamiento detrás de cada predicción aún puede trazarse y justificarse. La validación cruzada en múltiples particiones de los datos muestra que el rendimiento del modelo es estable y no un golpe de suerte por una partición afortunada.
Qué supone esto para las aulas
Para el lector no especializado, la conclusión principal es que es posible contar con herramientas de predicción estudiantil que sean a la vez potentes y comprensibles. En lugar de emitir puntuaciones de riesgo misteriosas, el modelo puede destacar patrones concretos como “GPA moderado pero ausencias frecuentes” y mostrar cómo estos se traducen en una predicción de Regular o Suspenso. Profesores y orientadores pueden entonces responder con acciones específicas —como apoyo a la asistencia o entrenamientos en técnicas de estudio— mientras explican con confianza a estudiantes y familias por qué el modelo llegó a esa conclusión. Los autores sostienen que esta combinación de precisión y transparencia es esencial si los sistemas basados en datos han de desempeñar un papel confiable en la promoción de una educación justa y eficaz.
Cita: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Palabras clave: predicción del rendimiento estudiantil, IA interpretable, base de reglas de creencias, minería de datos educativos, aprendizaje automático explicable