Clear Sky Science · es
Evaluación de factores que influyen en los efectos docentes de colegios y universidades mediante técnicas difusas y de aprendizaje profundo
Por qué importan mejores medidas de enseñanza
Cualquiera que haya asistido a clases excelentes y a otras no tan buenas sabe que la calidad docente puede marcar la diferencia en la experiencia universitaria. Sin embargo, la mayoría de las universidades siguen apoyándose en herramientas toscas como las calificaciones y las encuestas de fin de curso para juzgar qué funciona. Este artículo explora una forma más inteligente de medir qué tan bien enseñan las universidades combinando dos métodos informáticos: uno que maneja bien datos humanos imprecisos y otro que sobresale en detectar patrones ocultos. Juntos prometen una orientación más fiable para mejorar los cursos y apoyar a los estudiantes.
Repensar cómo juzgamos una “buena clase”
La enseñanza universitaria está moldeada por muchos factores cambiantes: cuántos estudiantes hay en el aula, la experiencia del docente, la dificultad del curso, el ambiente del aula y el uso de la tecnología, por nombrar algunos. Los sistemas de evaluación tradicionales a menudo reducen todo esto a una única nota de examen o a una calificación numérica del curso. Esa simplificación pasa por alto un contexto importante e ignora el lado desordenado y subjetivo del aprendizaje. Los autores sostienen que si queremos entender por qué algunas clases ayudan a los estudiantes a prosperar mientras que otras se quedan cortas, necesitamos herramientas que puedan manejar muchos factores a la vez y lidiar con información imperfecta basada en opiniones.
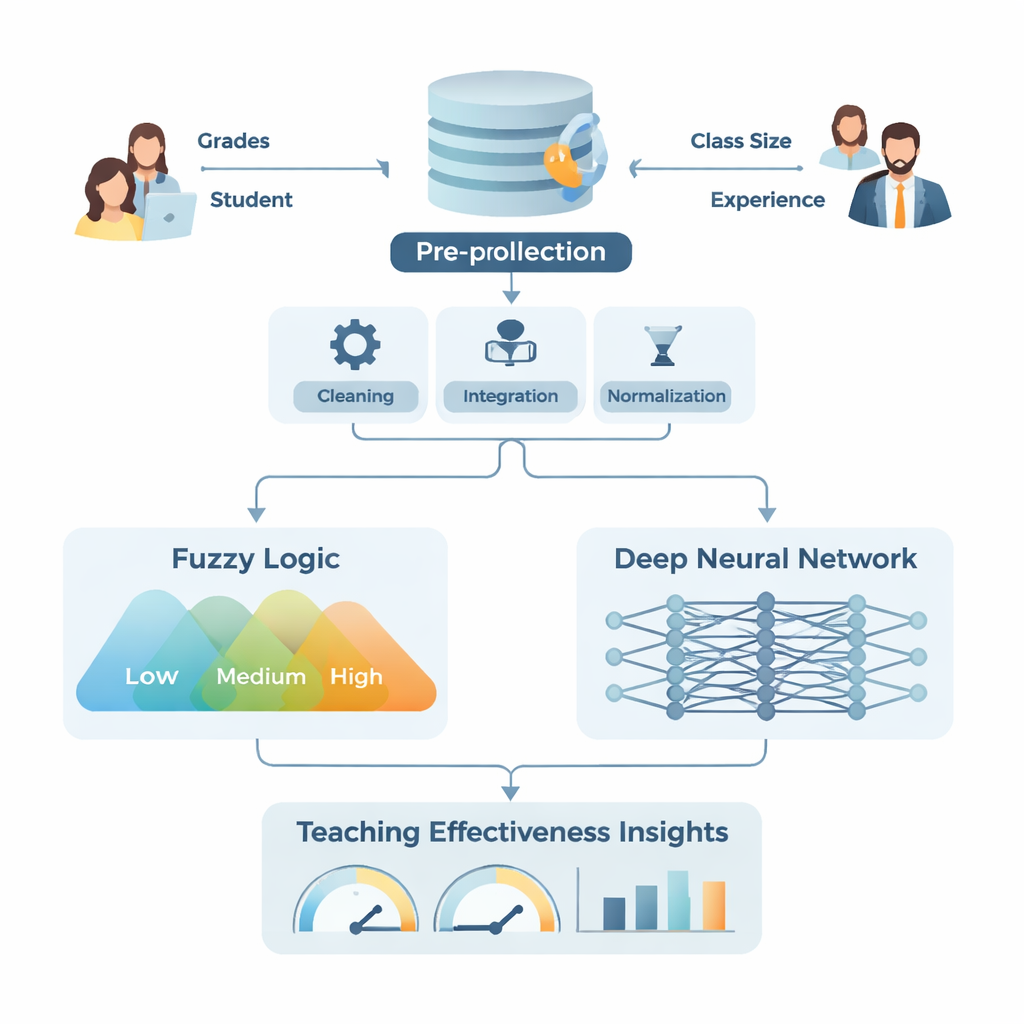
Un enfoque híbrido “humano” y de “detección de patrones”
El estudio presenta un modelo híbrido llamado Aprendizaje Difuso y Profundo (FDL). La parte «difusa» imita la forma en que las personas piensan en tonos de gris en lugar de categorías estrictas de sí o no; por ejemplo, decir que el rendimiento de un estudiante es «bajo», «medio» o «alto» con transiciones suaves en vez de umbrales rígidos. Convierte entradas vagas como la experiencia docente, la proporción estudiante–profesor y la dificultad del curso en categorías flexibles, y luego utiliza reglas sencillas como «si el rendimiento del estudiante es alto y la clase es pequeña, la efectividad docente es alta». Mientras tanto, la parte de aprendizaje profundo es una red por capas que procesa grandes cantidades de datos limpiados y estandarizados, descubriendo vínculos complejos que podrían no ser evidentes para los revisores humanos.
De encuestas crudas a señales significativas
Para probar su enfoque, los investigadores utilizaron datos de la National Survey of Student Engagement, un cuestionario amplio y muy utilizado que completan estudiantes de primer año y de últimos cursos en universidades y colegios de Norteamérica. Adaptaron varias preguntas para centrarlas con más precisión en cómo los docentes cumplen sus funciones y luego verificaron que la encuesta revisada fuera fiable. A continuación, llevaron a cabo una exhaustiva canalización de preparación de datos: corrección de errores, imputación de valores perdidos, fusión de información de estudiantes y docentes, y escalado de todo a un rango común. También crearon indicadores combinados, como una nota global ponderada basada en calificaciones de exámenes, entrega de tareas y asistencia, y redujeron la complejidad de los datos usando una técnica estándar llamada análisis de componentes principales. Este conjunto de datos preparado alimentó tanto el módulo de lógica difusa, que manejó categorías imprecisas, como la red de aprendizaje profundo, que manejó patrones numéricos de alta dimensión.
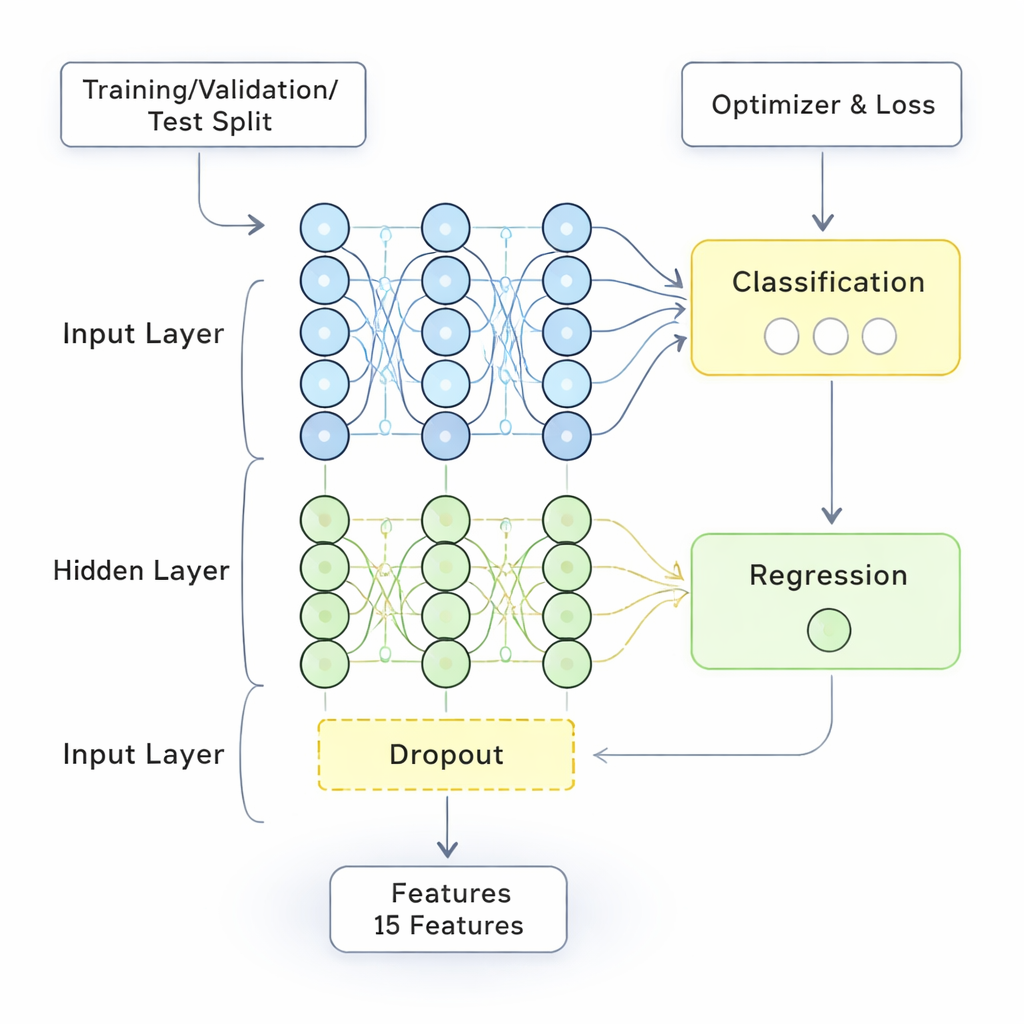
¿Qué tan bien funciona el nuevo modelo?
El modelo FDL se entrenó y probó con porciones separadas de los datos para evitar sobreajustar con ejemplos ya conocidos. Su rendimiento se comparó con varias alternativas potentes, incluidas redes neuronales estándar y modelos profundos más avanzados. En medidas clave—precisión global, precisión (precision), exhaustividad (recall) y puntuación F1—el método híbrido igualó o superó a los enfoques competidores, alcanzando alrededor del 98 % de exactitud y una tasa de error baja de poco más del 10 %. Igualmente importante, las reglas difusas hicieron que sus decisiones fueran más interpretables que las de los modelos de caja negra. El sistema pudo resaltar qué combinaciones de factores—como clases numerosas combinadas con baja experiencia docente, o cursos exigentes respaldados por retroalimentación sólida—estaban más fuertemente vinculadas a mejores o peores resultados docentes.
Qué significa esto para estudiantes y universidades
En términos prácticos, el estudio muestra que ahora es posible construir un “barómetro docente” automatizado que sea a la vez muy preciso y razonablemente comprensible. En lugar de confiar principalmente en promedios toscos y encuestas puntuales, las universidades podrían usar este tipo de sistema para detectar tempranamente entornos docentes débiles, identificar qué profesores o asignaturas necesitan apoyo específico y comprobar si nuevas políticas realmente ayudan a los estudiantes a aprender más. Los autores subrayan que el modelo no es perfecto: depende de la calidad de los datos, puede ser exigente en cómputo y necesariamente simplifica el rico lado humano de la educación. Aun así, usado con criterio, ofrece una nueva y potente lente para hacer que las aulas universitarias sean más efectivas, justas y sensibles a las necesidades de los estudiantes.
Cita: He, Z., Zhang, X., Zhang, Z. et al. Assessment of influencing factors of college and universities’ teaching effects using fuzzy and deep learning techniques. Sci Rep 16, 5168 (2026). https://doi.org/10.1038/s41598-026-35940-5
Palabras clave: efectividad docente, educación superior, rendimiento estudiantil, lógica difusa, aprendizaje profundo