Clear Sky Science · es
Estrategia de optimización dinámica impulsada por aprendizaje por refuerzo para el diseño paramétrico de modelos 3D
Diseños 3D más inteligentes con menos conjeturas
Desde edificios llamativos hasta pequeñas piezas mecánicas dentro de tu teléfono, muchos objetos modernos comienzan su vida como modelos 3D por ordenador. Los diseñadores suelen usar modelos “paramétricos”, donde controles deslizantes y fórmulas regulan formas, tamaños y patrones. Esto facilita explorar muchas opciones, pero también crea un laberinto de posibilidades imposible de recorrer a mano. Este artículo presenta un nuevo enfoque de inteligencia artificial llamado HRL‑DOS que ayuda a los ordenadores a navegar ese laberinto, mejorando automáticamente los diseños 3D en cuanto a resistencia, uso de material y facilidad de fabricación.
El reto de tener demasiadas opciones
En el diseño paramétrico, un único objeto puede depender de docenas o cientos de parámetros vinculados: grosores de pared, tamaños de orificios, curvas y reglas de alineación. A medida que los modelos crecen en complejidad, estos parámetros interactúan de formas poco evidentes. Las herramientas tradicionales de optimización o bien dependen de funciones matemáticas suaves, que fallan cuando los diseños son irregulares o ruidosos, o bien usan métodos de búsqueda por prueba y error, que pueden ser terriblemente lentos en problemas grandes. Incluso el aprendizaje por refuerzo estándar —donde un agente de IA aprende mediante repeticiones y retroalimentación— tiene problemas cuando debe considerar todas las combinaciones posibles de decisiones de diseño a la vez.
Una IA de dos niveles que piensa como un diseñador
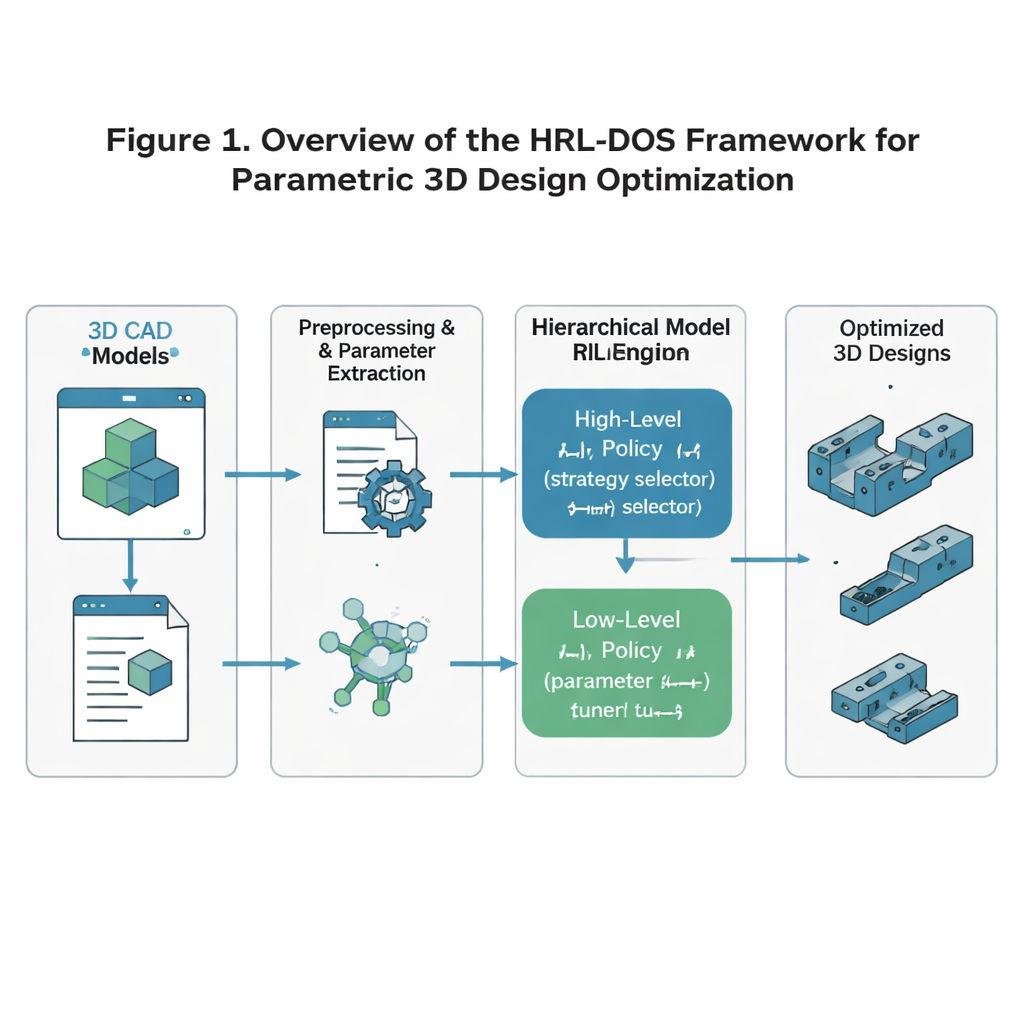
Los autores proponen la Estrategia de Optimización Dinámica basada en Aprendizaje por Refuerzo Jerárquico, o HRL‑DOS, para afrontar esta complejidad. En lugar de tratar el diseño como una única decisión gigantesca, HRL‑DOS divide la tarea en dos capas. Una política de alto nivel elige una dirección general para el diseño —por ejemplo favorecer menor peso, más simetría o margen de seguridad adicional—. Una política de bajo nivel ajusta entonces parámetros individuales, como dimensiones específicas o ubicaciones de rasgos, dentro de ese plan más amplio. Ambas capas reciben retroalimentación basada en el rendimiento del modelo actual en tres objetivos clave: estabilidad estructural, eficiencia geométrica y fabricabilidad. Esta estructura en capas refleja cómo trabajan los diseñadores humanos: primero decidir un concepto y luego refinar los detalles.
Convertir modelos 3D crudos en datos aprendibles
Para entrenar este sistema, los investigadores parten del ABC Dataset, una gran colección abierta de modelos 3D industriales detallados como soportes, engranajes, palancas y placas de montaje. Preprocesan cada modelo para que la IA vea una representación limpia y consistente: la geometría se normaliza a una escala y orientación estándar; se extraen dimensiones y rasgos clave como parámetros; y las reglas de fabricación —como el espesor mínimo de pared o los ángulos permitidos de voladizo— se codifican como restricciones. Estos parámetros se transforman después en una descripción “latente” compacta que desalienta de forma natural formas imposibles o inestables. El resultado es un estado numérico que la IA puede modificar con seguridad respetando, a la vez, reglas básicas de ingeniería.
Aprender a mejorar piezas realistas
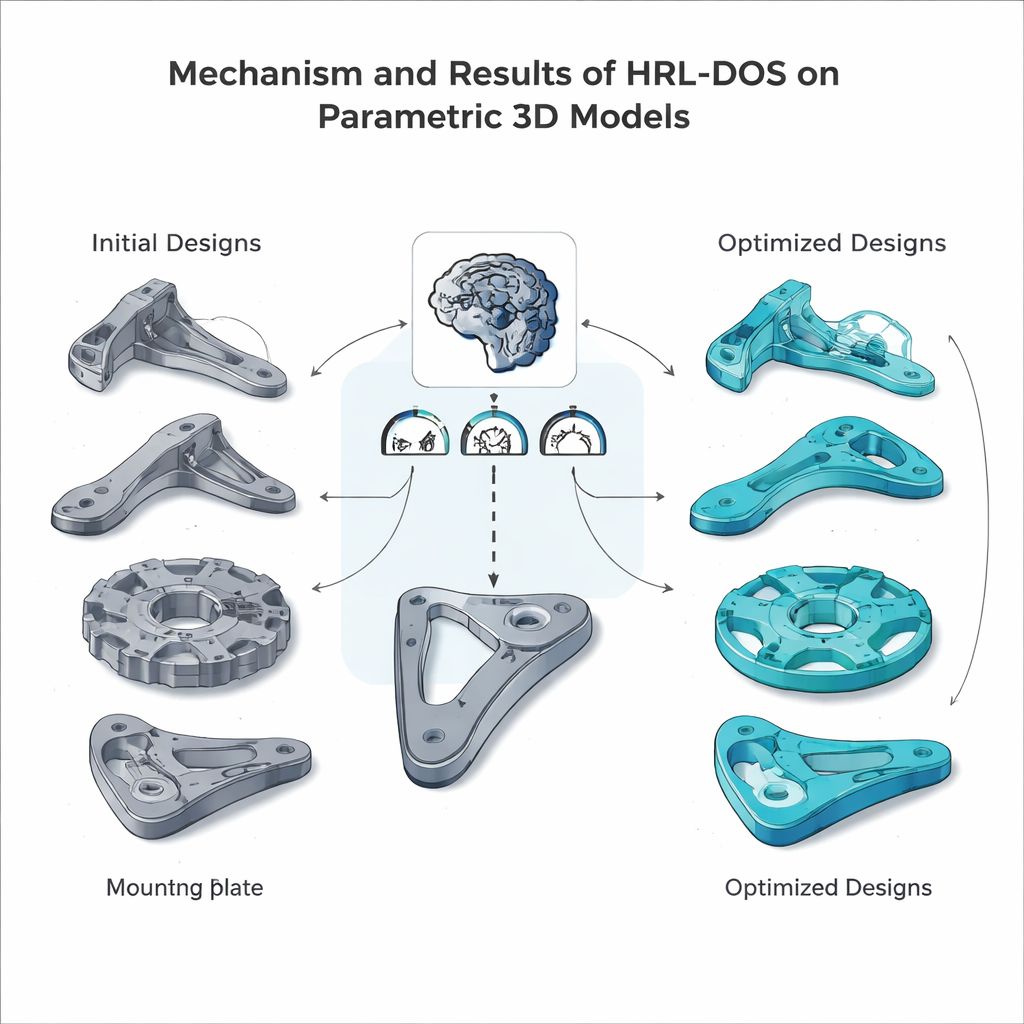
Dentro de este entorno preparado, los agentes jerárquicos proponen repetidamente nuevos diseños, ejecutan simulaciones para estimar peso y esfuerzo, comprueban la fabricabilidad y reciben una puntuación de recompensa combinada. A lo largo de muchos episodios de entrenamiento, el agente de alto nivel aprende qué objetivos estratégicos suelen dar mejores resultados, mientras que el agente de bajo nivel descubre qué ajustes de parámetros realmente alcanzan esos objetivos. El equipo probó HRL‑DOS en varias piezas representativas del conjunto de datos —un soporte con nervaduras, un disco dentado, una palanca de agarre y una placa de montaje— y comparó su rendimiento con varias alternativas avanzadas, incluyendo aprendizaje por refuerzo plano, híbridos con algoritmos genéticos y otras herramientas de diseño asistido por IA. HRL‑DOS alcanzó buenas soluciones aproximadamente un 27 % más rápido y produjo modelos con alrededor de un 18 % más de puntuación de calidad global.
Diseños fuertes, fabricables y flexibles
Más allá del rendimiento bruto, HRL‑DOS demostró ser mejor en mantenerse dentro de límites estrictos de ingeniería. Generó muchas menos piezas que violaran restricciones de seguridad o fabricación y alcanzó puntuaciones de fabricabilidad más altas en comprobaciones como ángulos de voladizo, cavidades internas y tolerancias. El método también generalizó bien a nuevos tipos de piezas no vistos y se mantuvo robusto cuando los datos de entrada eran ruidosos o estaban parcialmente ausentes —una cualidad importante para flujos de trabajo de diseño del mundo real. En conjunto, estos resultados sugieren que el aprendizaje por refuerzo jerárquico puede servir como un motor práctico para el diseño inteligente asistido por ordenador, ayudando a arquitectos e ingenieros a explorar más opciones en menos tiempo, manteniendo sus modelos seguros, eficientes y listos para la fabricación.
Cita: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
Palabras clave: diseño 3D paramétrico, aprendizaje por refuerzo, optimización de diseño, diseño asistido por ordenador, ingeniería generativa