Clear Sky Science · es
HEViTPose: hacia una estimación de pose humana 2D de alta precisión y eficiencia con atención en reducción espacial en cascada por grupos
Enseñar a los ordenadores a leer el lenguaje corporal
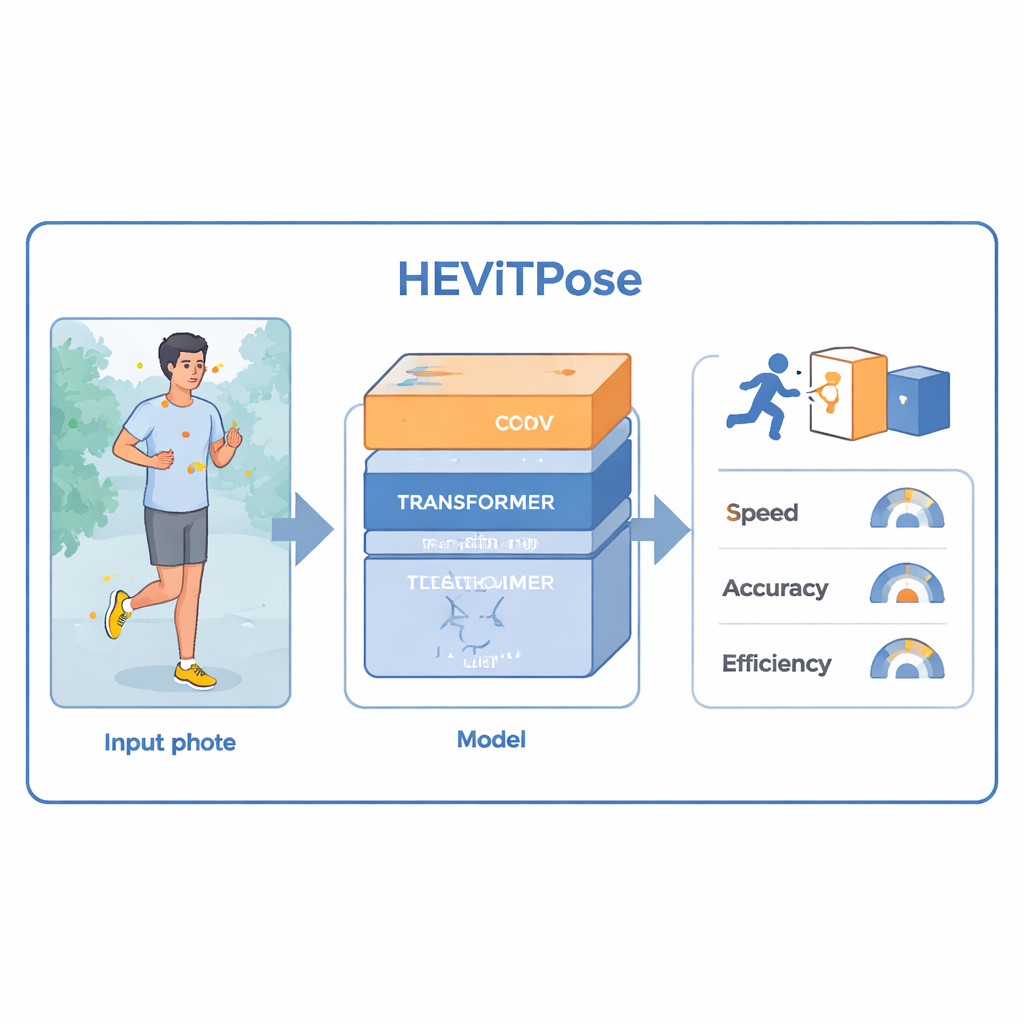
Desde aplicaciones de fitness hasta sistemas de asistencia al conductor, muchas tecnologías dependen hoy de la capacidad de un ordenador para comprender cómo se mueve la gente. Esta habilidad, llamada estimación de pose humana, consiste en hallar las posiciones de las articulaciones del cuerpo—como hombros, rodillas y tobillos—en una imagen o vídeo. El reto es hacerlo con suficiente precisión y con la rapidez necesaria para uso en tiempo real en hardware cotidiano. Este artículo presenta HEViTPose, un nuevo método que busca mantener alta precisión usando menos potencia de cálculo que muchos sistemas actuales.
Por qué es tan difícil encontrar articulaciones en imágenes
A primera vista, localizar las articulaciones podría parecer sencillo: basta con buscar brazos y piernas. En la práctica, las personas aparecen a distintos tamaños, en posturas inusuales, en escenas concurridas y a menudo ocultas detrás de objetos como muebles o coches. Los sistemas modernos suelen abordar esto creando un “mapa de calor” detallado para cada articulación, donde las zonas brillantes marcan las posiciones probables. Los mapas de calor son muy precisos pero costosos de calcular. Los sistemas tradicionales se basan principalmente en redes neuronales convolucionales, buenas para detectar patrones locales pero que deben hacerse más profundas y pesadas para capturar relaciones de largo alcance en todo el cuerpo. Los modelos recientes basados en transformers sobresalen capturando esos vínculos de largo alcance, pero a menudo requieren grandes conjuntos de datos y mucho cálculo, lo que dificulta su uso en tiempo real o en dispositivos pequeños.
Vistazos superpuestos para una visión más suave
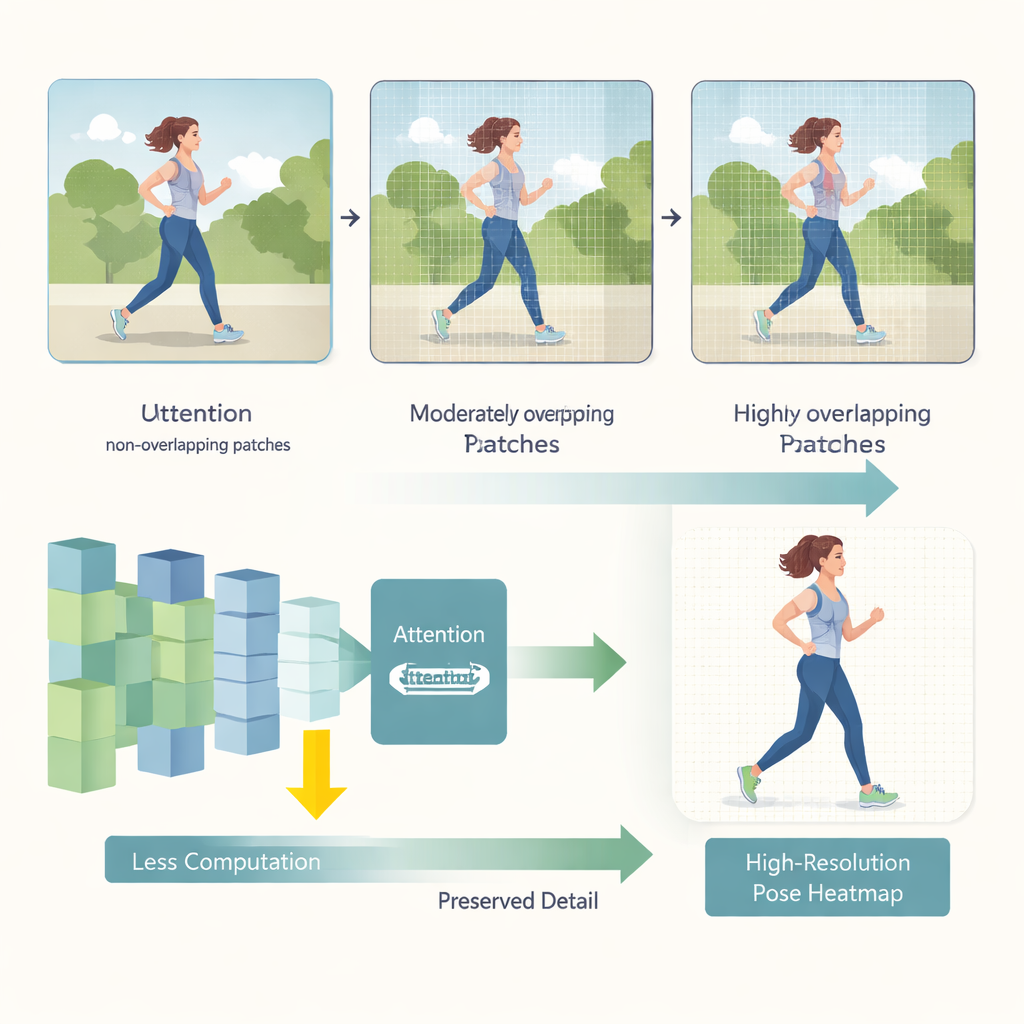
HEViTPose comienza replanteando cómo se divide una imagen en piezas para su análisis. Los transformers anteriores suelen cortar las imágenes en parches no superpuestos, lo que puede romper la continuidad visual entre regiones vecinas—como cortar el brazo de una persona en el borde de un parche. HEViTPose parte de la idea de embedding de parches superpuestos e introduce una medida clara y ajustable llamada Anchura de Solapamiento del Embebido de Parche (PEOW, por sus siglas en inglés). PEOW cuenta simplemente cuántos píxeles comparten los parches vecinos a lo largo de sus bordes. Variando sistemáticamente este solapamiento, los autores muestran que un solapamiento moderado permite a la red “percibir” mejor el cambio suave de color y forma entre parches adyacentes. Esa mayor continuidad local conduce a ubicaciones de articulaciones más precisas, sin incrementar drásticamente el tamaño del modelo ni el coste computacional.
Atención más inteligente con menos trabajo
La segunda innovación clave es un nuevo módulo de atención llamado Atención Multi‑cabeza de Reducción Espacial en Cascada por Grupos (CGSR‑MHA). Los mecanismos de atención indican a la red qué partes de la imagen deben influir en cada predicción, pero suelen escalar mal a medida que las imágenes crecen. CGSR‑MHA lo aborda de tres maneras. Primero, divide las características en grupos, de modo que cada grupo maneje solo una porción de la información en lugar de todo a la vez. Segundo, reduce la resolución espacial dentro de cada grupo antes de calcular la atención, disminuyendo drásticamente el número de operaciones. Tercero, usa varias pequeñas cabezas de atención en lugar de unas pocas grandes, preservando la diversidad de lo que el modelo puede “atender” mientras mantiene bajo el coste. Ajustes cuidadosamente escogidos sobre cuántos grupos usar, cuánto reducir y cuántas cabezas incluir equilibran velocidad y precisión.
Modelos ligeros que aún compiten entre los mejores
Para evaluar HEViTPose, los autores lo prueban en dos benchmarks ampliamente usados: el conjunto de datos MPII de actividades humanas cotidianas y el mayor COCO con personas en muchas escenas diferentes. A través de varios tamaños de modelo, HEViTPose iguala o se aproxima a la precisión de los sistemas líderes en estimación de pose mientras usa muchos menos parámetros y menos cálculo. Por ejemplo, una versión alcanza una precisión similar a una conocida red de alta resolución (HRNet) reduciendo más del 60% el número de parámetros aprendibles y disminuyendo la cantidad de cálculo en más del 40%. En comparación con otro modelo híbrido moderno que mezcla convoluciones y transformers, HEViTPose ofrece un rendimiento similar pero funciona aproximadamente 2,6 veces más rápido en una GPU. Estos ahorros se traducen directamente en un rendimiento en tiempo real más fluido y en menores requisitos de hardware.
Qué supone esto para las aplicaciones cotidianas
En términos sencillos, HEViTPose demuestra que no es necesario elegir entre precisión y eficiencia al enseñar a los ordenadores a leer el lenguaje corporal humano. Al superponer cuidadosamente las piezas de imagen que examina y rediseñar cómo se calcula la atención dentro de la red, el sistema puede localizar articulaciones con alta precisión manteniéndose compacto y rápido. Esto lo hace atractivo para usos reales como seguimiento deportivo, vigilancia por vídeo, interacción humano‑robot y monitorización en el vehículo, donde importan tanto la velocidad como el consumo energético. Las ideas detrás de HEViTPose—solapamiento más inteligente y atención eficiente—también podrían adaptarse a tareas relacionadas como el seguimiento de la pose en animales o la detección de puntos faciales, aportando ojos “digitales” más nítidos a muchos dispositivos sin necesitar hardware de nivel supercomputador.
Cita: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Palabras clave: estimación de pose humana, visión por computador, transformer de visión, aprendizaje profundo eficiente, mecanismo de atención