Clear Sky Science · es
Un marco híbrido de CNN y aprendizaje por refuerzo para la identificación de hablantes usando características de Mel-espectrograma y transformada wavelet continua
Por qué tu voz puede ser una llave digital
Imagina desbloquear tu cuenta bancaria, la puerta de casa o el teléfono usando solo tu voz. Para que eso sea seguro, los ordenadores deben distinguir de forma fiable a una persona de otra, incluso cuando hay ruido de fondo, emoción o un micrófono deficiente. Este artículo explora una nueva manera de enseñar a las máquinas a reconocer quién está hablando, no solo qué dicen, combinando trucos modernos de aprendizaje profundo con una forma de aprendizaje por prueba y error tomada de la robótica.
De las ondas sonoras a las huellas de voz
La voz de cada persona lleva pistas sutiles modeladas por el tamaño y la forma del tracto vocal, cómo vibran sus pliegues vocales y su estilo de habla. Los investigadores empezaron preguntando: ¿qué propiedades medibles del habla grabada difieren realmente entre personas? Usando 2.703 fragmentos de audio de 40 hablantes en inglés del conjunto LibriSpeech, analizaron 22 características acústicas simples, como la variación de sonoridad, la energía en distintas bandas de frecuencia, el ritmo y una medida llamada entropía que capta cuán complejo o impredecible es el sonido. Pruebas estadísticas mostraron que 21 de estas 22 características contenían información fuertemente específica del hablante, destacando especialmente la entropía y la energía en altas frecuencias como distintivos. En otras palabras, la “huella de voz” de una persona se extiende a muchos aspectos del sonido, no solo al tono o al volumen.
Dos formas de convertir el sonido en imágenes
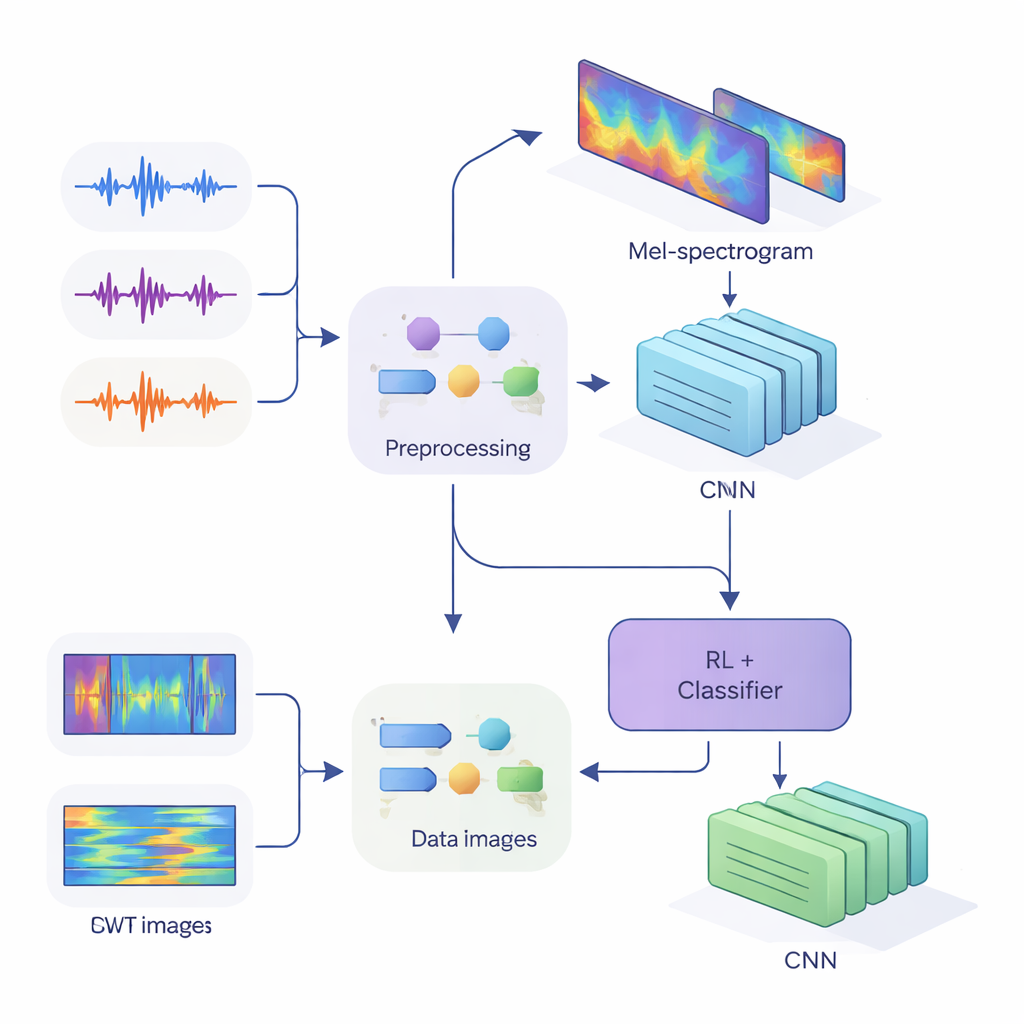
Para alimentar estas pistas a redes neuronales modernas, el equipo convirtió el audio unidimensional en imágenes bidimensionales que capturan cómo cambia la energía a lo largo del tiempo y la frecuencia. En el primer método, usaron Mel-espectrogramas, que imitan cómo el oído humano agrupa las frecuencias y son estándar en tecnología del habla. En el segundo, emplearon transformadas wavelet continuas, una forma más flexible de enfocar tanto sonidos cortos y agudos como vocales más largos. Tras limpiar cuidadosamente el audio—eliminando silencios, estandarizando el volumen y añadiendo pequeñas distorsiones como ruido y cambios de tono para hacer el sistema más robusto—produjeron “imágenes” Mel de tamaño 80 por 313 e “imágenes” wavelet de 128 por 128, listas para ser procesadas por redes neuronales convolucionales (CNN).
Enseñar a las redes a escuchar y dudar
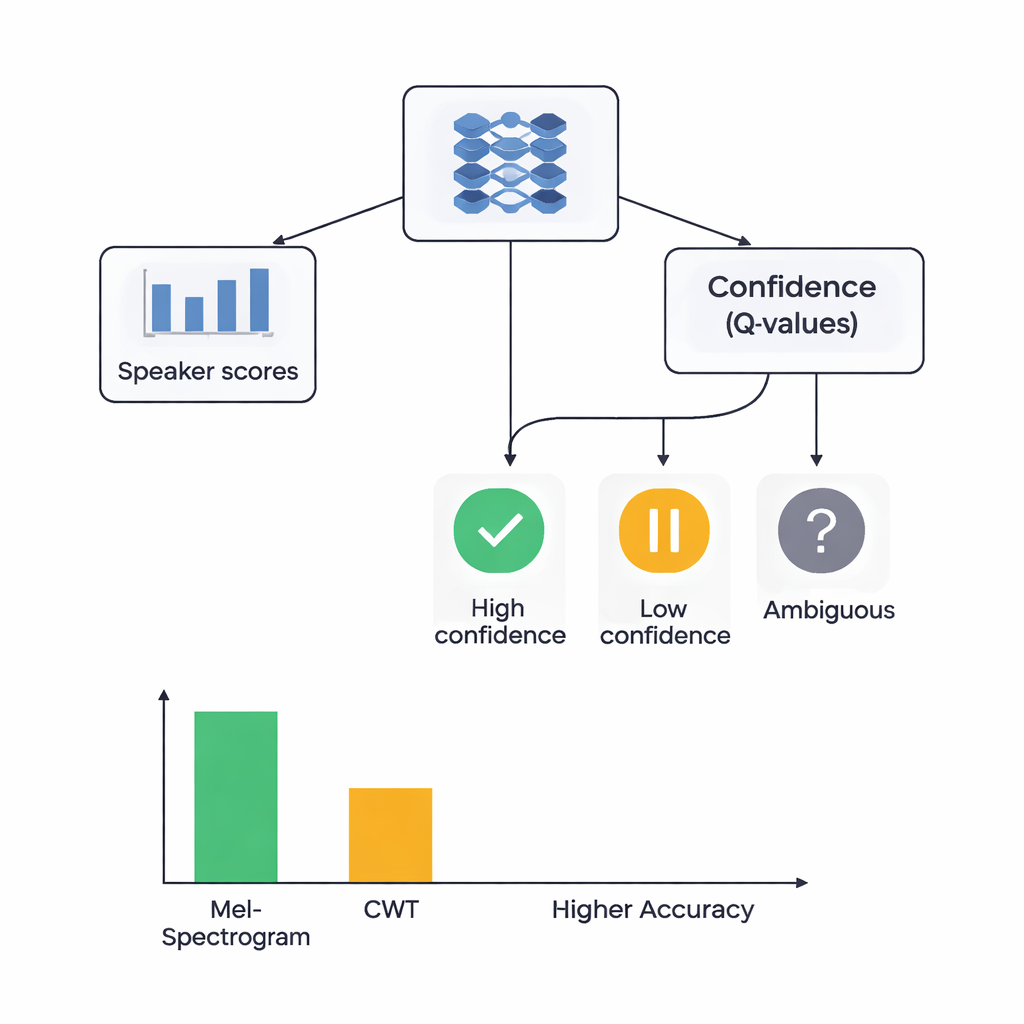
En el corazón del estudio hay una arquitectura híbrida que une dos estilos de aprendizaje. Primero, las CNN analizan las imágenes Mel o wavelet para extraer patrones que suelen pertenecer a determinados hablantes, similar a cómo las redes de reconocimiento de imágenes aprenden a detectar ojos o bordes. Para el sistema basado en Mel, los autores añaden un módulo de autoatención que permite a la red centrarse en los segmentos temporales más informativos. Encima de estos extractores de características colocan un componente de aprendizaje por refuerzo (RL) que aprende cuánta confianza debe tener el sistema en cada decisión. En vez de tomar siempre una decisión tajante, la parte de RL asigna valores a acciones como “aceptar esto como una conjetura de alta confianza”, “tratar esto como baja confianza” o “marcar como ambiguo”. A lo largo de muchas rondas de entrenamiento, se recompensa cuando las decisiones confiadas son correctas, lo que empuja a la red hacia juicios mejor calibrados.
¿Qué tan bien funciona el sistema híbrido?
Los investigadores compararon cuatro modelos: basado en Mel con RL, basado en Mel sin RL, basado en wavelet con RL y basado en wavelet sin RL. Todos se probaron usando una estricta validación cruzada de cinco particiones, lo que significa que cada fragmento de audio sirvió tanto para entrenamiento como para prueba en diferentes rondas. El sistema Mel con RL fue el que mejor funcionó, identificando correctamente al hablante en alrededor del 88% de los casos y mostrando una separación casi perfecta entre hablantes según una medida estándar de poder discriminativo. El sistema wavelet con RL alcanzó aproximadamente un 78% de precisión. De forma crucial, añadir el componente de RL mejoró el rendimiento para ambos tipos de características en torno a 3 puntos porcentuales y hizo que los resultados fuesen más consistentes entre distintas particiones de los datos. Más clases de hablantes lograron reconocimiento de alta calidad cuando se incluyó RL, lo que sugiere que las decisiones conscientes de confianza ayudaron especialmente con voces difíciles o fácilmente confundibles.
Qué significa esto para la seguridad de la voz en el día a día
Para los no especialistas, la conclusión clave es que las verificaciones de identidad basadas en la voz fiables requieren tanto representaciones ricas del sonido como un sano sentido de duda por parte de la máquina. Este trabajo muestra que los Mel-espectrogramas inspirados en el oído, combinados con atención y un aprendiz por refuerzo que puede decir “no estoy seguro”, superan a las imágenes wavelet más exóticas para la tarea de diferenciar hablantes. Aunque el estudio usa un conjunto de datos relativamente pequeño y limpio y aún no está afinado para condiciones ruidosas del mundo real, demuestra que añadir una capa consciente de la confianza sobre redes neuronales profundas puede hacer la autenticación por voz más precisa y más confiable—un paso importante si queremos que nuestras voces se conviertan en llaves digitales seguras.
Cita: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Palabras clave: identificación de hablantes, biometría de voz, aprendizaje profundo, aprendizaje por refuerzo, Mel-espectrogramas