Clear Sky Science · es
Un marco general para la reducción dimensional no paramétrica adaptativa
Por qué importa reducir el volumen de los grandes conjuntos de datos
La vida moderna funciona con datos: exploraciones médicas, historiales de compras en línea, fotos, fuentes de noticias y más. Cada registro puede tener cientos o miles de medidas, lo que dificulta almacenarlos, analizarlos o incluso visualizarlos. Los científicos usan la “reducción dimensional” para comprimir esa complejidad en imágenes y modelos más sencillos, conservando los patrones importantes. Pero las herramientas populares actuales a menudo requieren muchas decisiones manuales y ajustes por ensayo y error. Este artículo presenta una manera de dejar que los propios datos decidan cómo reducirse mejor, con el objetivo de obtener imágenes más claras, un aprendizaje más preciso y menos conjeturas por parte del usuario.
De líneas simples a realidades curvadas
Una herramienta clásica para simplificar datos, el Análisis de Componentes Principales, funciona como iluminar un objeto y mirar su sombra: encuentra las mejores direcciones planas que explican la mayor parte de la variación. Esto es potente cuando la estructura de los datos es aproximadamente recta o plana. Pero los datos reales—como imágenes, textos o lecturas de sensores—a menudo yacen sobre superficies curvas ocultas en un espacio de alta dimensión. Durante las últimas dos décadas, se han diseñado nuevos métodos “no lineales” como Isomap, Locally Linear Embedding (LLE), incrustaciones espectrales y UMAP específicamente para descubrir esas formas sinuosas. Se basan en vecindarios locales: para cada punto, miran a sus vecinos más cercanos e intentan preservar esas relaciones a pequeña escala al dibujar una representación en menor dimensión. Sin embargo, estos métodos obligan al usuario a elegir dos perillas clave: cuántos vecinos usar y a cuántas dimensiones proyectar. Si se elige mal, el resultado puede ser engañoso o computacionalmente costoso.
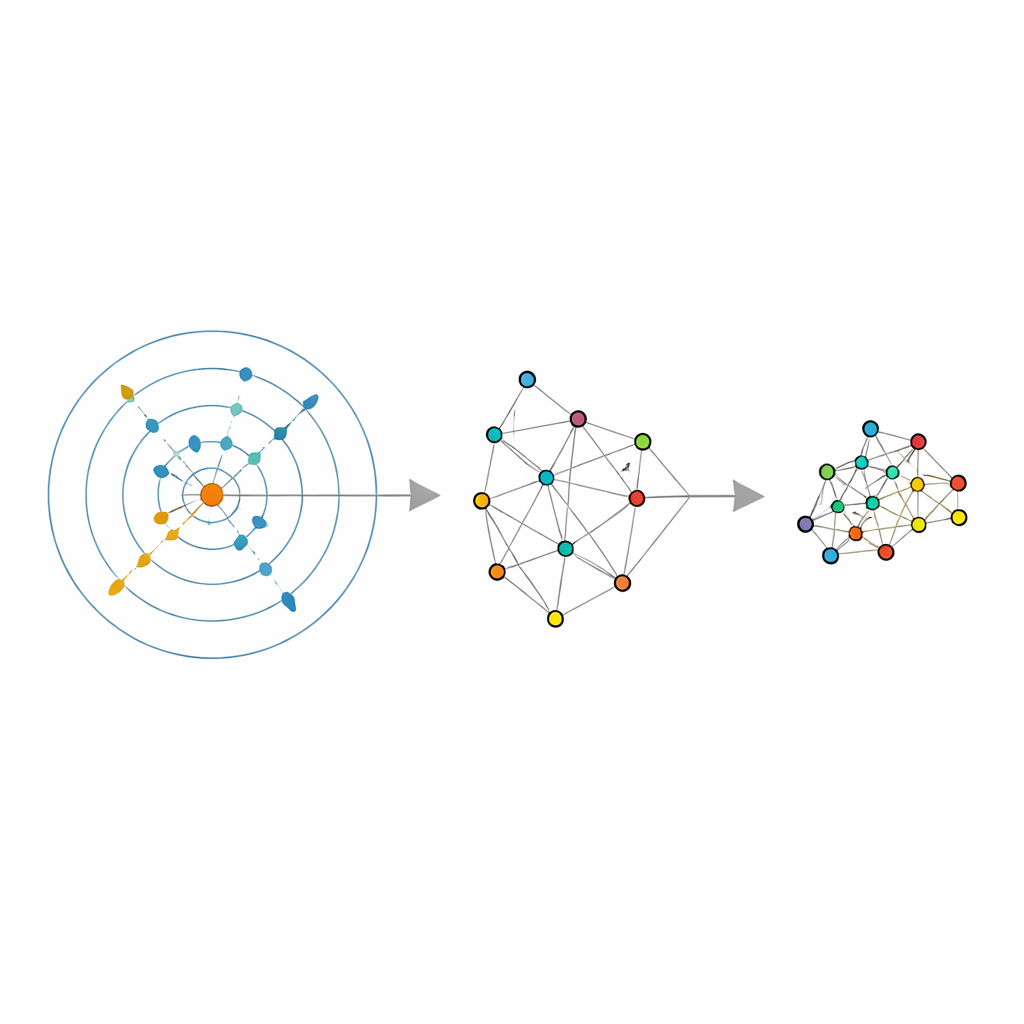
Permitir que los datos elijan su propio vecindario
Los autores se basan en una herramienta estadística reciente llamada estimador de dimensión intrínseca, que trata de responder una pregunta simple: ¿en cuántas direcciones independientes varían realmente los datos, una vez eliminada la ruido? Su estimador, llamado ABIDE, va más allá. Alrededor de cada punto, busca automáticamente un vecindario que parezca razonablemente uniforme—ni demasiado pequeño y ruidoso ni demasiado grande y distorsionado. Al hacerlo, devuelve dos piezas de información: una estimación global de la dimensión verdadera de los datos y un tamaño de vecindario a medida para cada punto. Esto transforma el habitual “número fijo de vecinos” en una cantidad adaptativa localmente que puede crecer en regiones dispersas y reducirse en las densas, ajustándose a la densidad real de los datos.
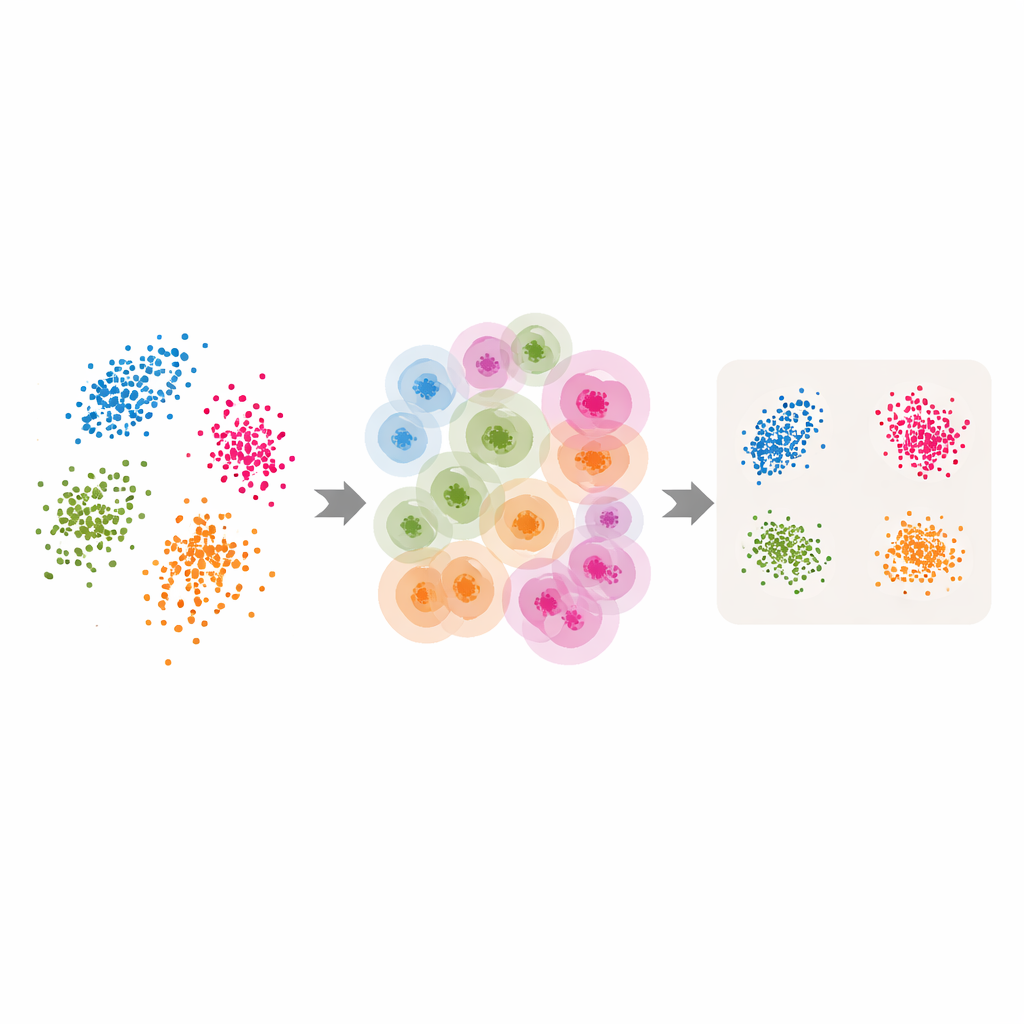
Convertir herramientas clásicas en versiones adaptativas
Armados con estos vecindarios adaptativos y la dimensión intrínseca estimada, los autores adaptan varios métodos populares de reducción dimensional y de agrupamiento. Para LLE, sustituyen el único conteo de vecinos elegido por el usuario por los valores por punto devueltos por ABIDE, y fijan la dimensión objetivo igual a la dimensión intrínseca estimada. El algoritmo aprende entonces a reconstruir cada punto a partir de un grupo local cuidadosamente elegido antes de encontrar una disposición global de baja dimensión que preserve mejor esas reconstrucciones locales. Ideas similares se aplican al clustering espectral—donde se usa un grafo de similitudes entre puntos para agrupar—y a UMAP, que construye un mapa difuso de cómo se conectan los puntos. En cada caso, el tamaño rígido del vecindario se sustituye por una estructura flexible guiada por los datos que sigue la geometría natural de éstos.
Pruebas con flores, dígitos, texto y formas sintéticas
Para comprobar si este enfoque adaptativo compensa, los autores realizan experimentos en varios benchmarks: las clásicas medidas de las flores Iris, imágenes de dígitos manuscritos (MNIST), artículos de noticias representados por incrustaciones de modelos de lenguaje y formas tridimensionales sintéticas con ruido añadido. Comparan las versiones adaptativas frente a configuraciones estándar de software y frente a rejillas cuidadosamente afinadas de hiperparámetros. En tareas no supervisadas como el agrupamiento y la visualización, los métodos adaptativos suelen producir clusters más claros, agrupaciones más compactas y mejores puntuaciones en medidas de calidad estándar. Por ejemplo, en variedades complejas con densidad de puntos desigual, los métodos adaptativos recuperan la estructura verdadera con mucha más fidelidad que las versiones con vecinos fijos. En pruebas supervisadas, donde los datos reducidos se introducen en un clasificador, el enfoque adaptativo de nuevo iguala o supera las mejores opciones de parámetros fijos, sin necesidad de una búsqueda exhaustiva.
Qué significa esto para el análisis de datos cotidiano
Para no expertos y practicantes por igual, el mensaje principal es que reducir datos no tiene por qué depender de conjeturas. Al usar la propia geometría de los datos para decidir “cuántos vecinos” y “cuántas dimensiones”, este marco convierte herramientas muy usadas como LLE, clustering espectral y UMAP en versiones más inteligentes y robustas de sí mismas. El resultado son vistas de baja dimensión más confiables—gráficos y características que reflejan mejor la verdadera forma de los datos—mientras que a menudo se reduce el tiempo dedicado a búsquedas manuales de hiperparámetros. En términos prácticos, esto significa que tareas como visualizar grandes colecciones de imágenes, agrupar documentos o preparar entradas para modelos predictivos pueden volverse más sencillas y más fiables, simplemente dejando que los datos guíen de forma adaptativa cómo se comprimen.
Cita: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Palabras clave: reducción dimensional, aprendizaje de variedades, vecinos más cercanos, dimensión intrínseca, visualización de datos