Clear Sky Science · es
Optimizador mejorado de la distribución normal generalizada con método de reparación por distribución gaussiana y aprendizaje inverso de Cauchy para selección de características
Por qué importa elegir bien los datos
La vida moderna depende de los datos, desde exploraciones médicas y registros bancarios hasta flujos de redes sociales. Pero más datos no siempre es mejor. Cuando se pide a los ordenadores que aprendan a partir de miles de medidas en bruto a la vez, pueden volverse más lentos, más caros de ejecutar y, sorprendentemente, menos precisos. Este artículo presenta una forma más inteligente de cribar todas esas medidas y conservar solo las que realmente importan, usando un nuevo algoritmo llamado Optimizador Binario Adaptativo de la Distribución Normal Generalizada, o BAGNDO.
El problema de tener demasiadas pistas
Imagínese diagnosticar una enfermedad con cientos de pruebas de laboratorio, exploraciones y respuestas a cuestionarios. Muchas de estas “características” pueden ser ruidosas, redundantes o simplemente irrelevantes, y alimentarlas todas a un clasificador puede confundir en lugar de ayudar. La selección de características busca elegir un subconjunto más pequeño y más informativo de entradas para que los modelos de aprendizaje automático sean más rápidos, económicos y fiables. Los filtros estadísticos simples pueden eliminar características claramente poco útiles, pero no adaptan sus elecciones al modelo específico que se emplea y a menudo pasan por alto combinaciones sutiles de variables. Los métodos más avanzados de tipo “wrapper” evalúan conjuntos de características probando directamente el rendimiento de un clasificador, pero esto crea un problema de búsqueda enorme: el número de subconjuntos posibles se dispara conforme crece el número de características.
Buscar con inteligencia en lugar de a ciegas
Para manejar esta explosión, los investigadores recurren a algoritmos metaheurísticos: estrategias de búsqueda inspiradas en procesos naturales o físicos que equilibran la exploración amplia con el refinamiento focalizado. Un método de este tipo, el Optimizador de la Distribución Normal Generalizada (GNDO), trata las soluciones candidatas como si se extrajeran de una curva en forma de campana flexible y desplaza gradualmente esa curva hacia respuestas mejores. GNDO ha funcionado bien en aplicaciones de ingeniería y energía, pero tiende a estabilizarse prematuramente en soluciones solo aceptables y le cuesta equilibrar su vagabundeo global con el ajuste local cuando se aplica a la selección de características. Los autores identifican esto como una brecha crítica: las elegantes fórmulas de GNDO no se traducen automáticamente en un rendimiento fuerte sobre decisiones de alto dimensión y tipo sí/no acerca de qué características conservar.
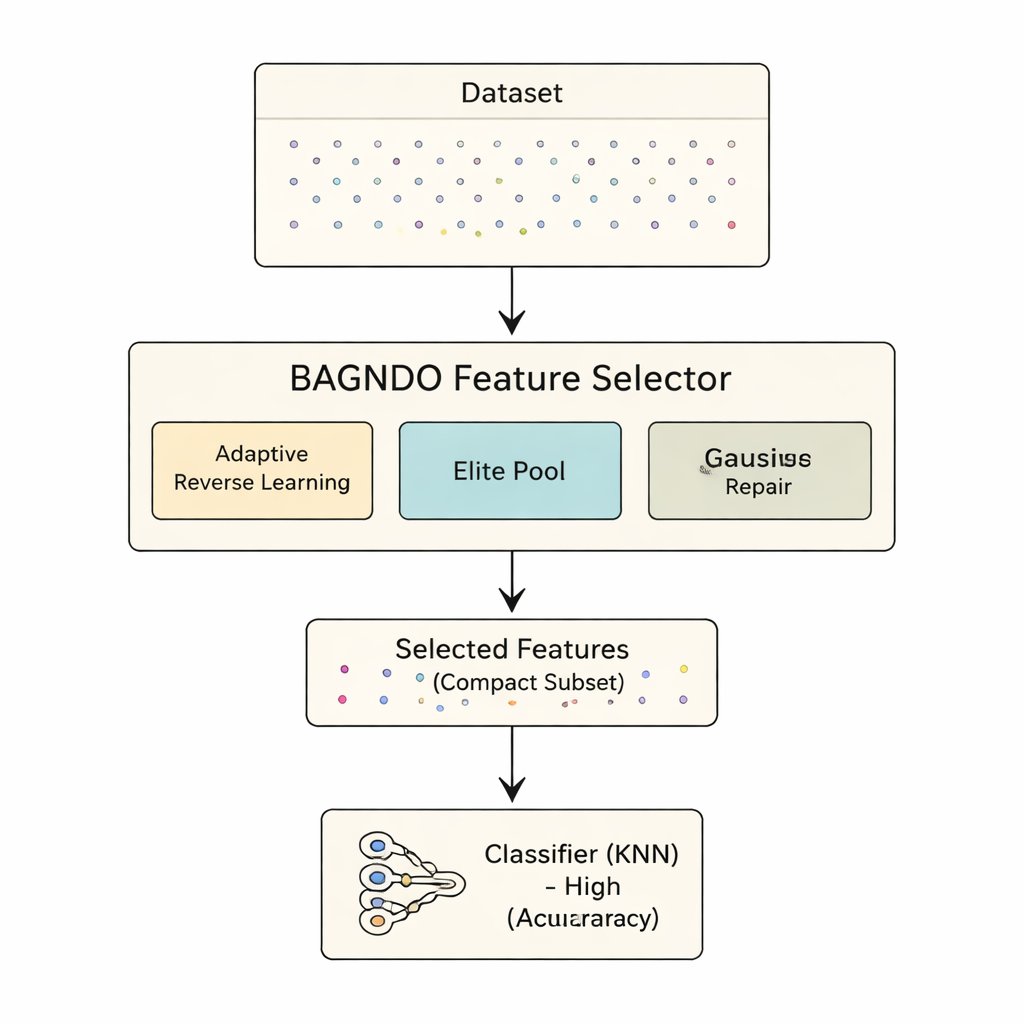
Una mejora en tres partes para un motor clásico
El marco propuesto BAGNDO mejora GNDO con tres ideas coordinadas. Primero, una estrategia Adaptativa de Aprendizaje Inverso de Cauchy genera regularmente versiones “espejo” de las soluciones actuales usando una distribución de probabilidad de colas pesadas. Esto fomenta saltos audaces hacia regiones inexploradas del espacio de búsqueda, evitando que el algoritmo quede atrapado en valles locales. Segundo, una Estrategia de Grupo Élite mantiene no solo una mejor solución única, sino un pequeño grupo de los mejores junto con un candidato “guía” mezclado. Este grupo de liderazgo más rico ayuda a mantener la diversidad mientras orienta la búsqueda hacia regiones prometedoras. Tercero, un método de Reparación de la Peor Solución basado en Distribución Gaussiana examina a los candidatos más débiles y los empuja hacia patrones aprendidos del grupo élite, reciclando efectivamente soluciones malas en mejores en lugar de descartarlas por completo.
Poniendo el método a prueba
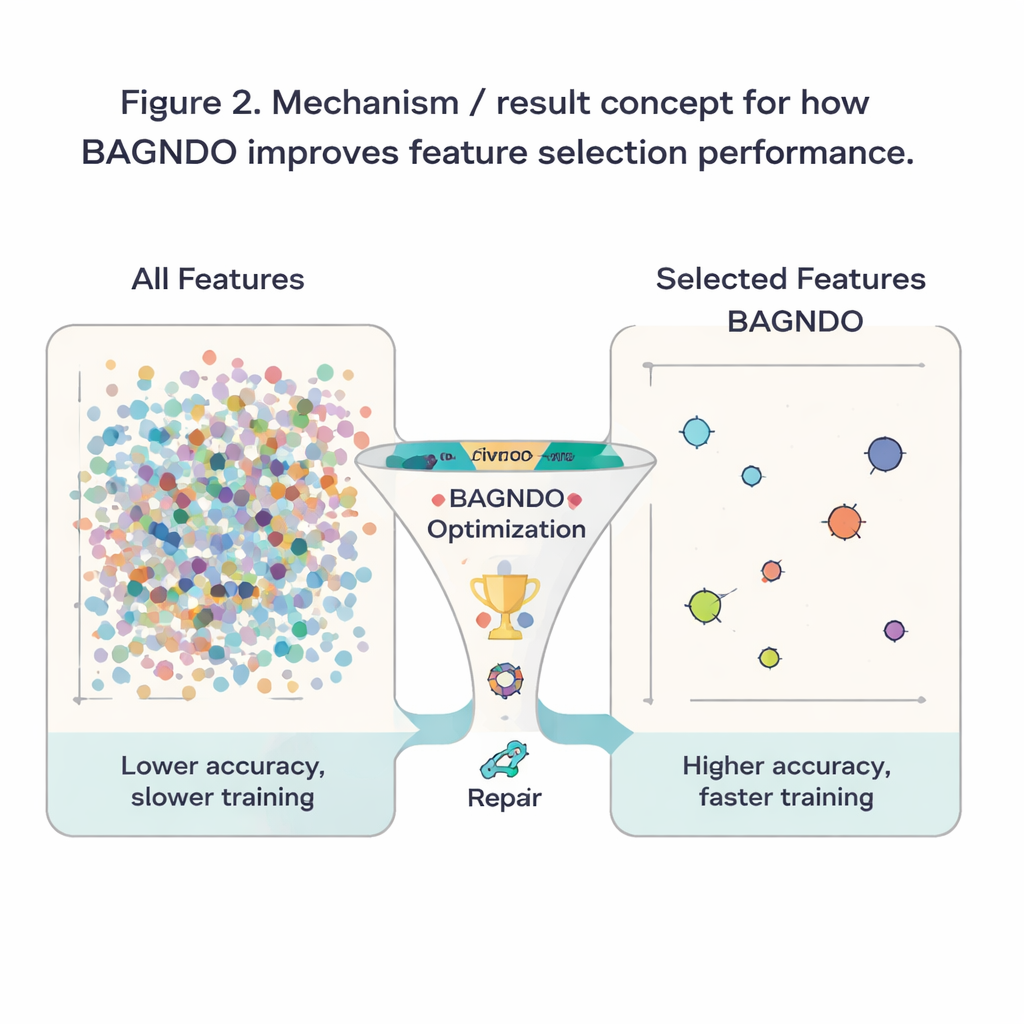
Para comprobar si estas ideas ayudan en la práctica, los autores aplicaron BAGNDO a 18 conjuntos de datos de referencia bien conocidos del repositorio UCI, que abarcan diagnóstico médico, juegos, señales y más. En cada caso, el algoritmo buscó un subconjunto de características que permitiera a un clasificador k-vecinos más cercanos estándar hacer predicciones precisas. BAGNDO se enfrentó a nueve competidores fuertes, incluidos optimización por enjambre de partículas, métodos de estilo genético y varios algoritmos modernos inspirados en enjambres. A lo largo de estas pruebas, BAGNDO encontró consistentemente conjuntos de características más pequeños manteniendo, y a menudo mejorando, la precisión de predicción. Logró la mejor precisión con los subconjuntos de características más compactos en 14 de los 18 conjuntos de datos, y las pruebas estadísticas confirmaron que estas ganancias no se debieron al azar.
Qué significa esto para el aprendizaje automático cotidiano
Para un público general, el resultado puede resumirse así: los autores han construido un “selector de características” más disciplinado que ayuda a los algoritmos de aprendizaje a centrarse en lo que realmente importa en un conjunto de datos. Al equilibrar mejor la exploración amplia, la guía de élite y la reparación de candidatos pobres, BAGNDO elimina entradas innecesarias mientras mantiene o aumenta la precisión. Esto se traduce en modelos más rápidos, menores costes de almacenamiento y cómputo y, a menudo, en una comprensión más clara de qué mediciones o preguntas son más informativas. Aunque el método exige más cómputo que algunas alternativas más simples, ofrece una herramienta potente para problemas donde la precisión y la interpretabilidad son primordiales, desde apoyo a decisiones médicas hasta monitorización industrial y más allá.
Cita: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Palabras clave: selección de características, optimización metaheurística, aprendizaje automático, reducción de dimensionalidad, precisión de clasificación