Clear Sky Science · es
Métodos de kernel cuántico para análisis de marketing con teoría de convergencia y cotas de separación
Por qué importan mejores predicciones de clientes
Las empresas dependen cada vez más de los datos para decidir a qué clientes dirigir ofertas, soporte o campañas de retención. Pero a medida que los datos se vuelven más complejos, las herramientas tradicionales pueden tener dificultades para detectar patrones sutiles, sobre todo cuando cada cliente valioso perdido resulta costoso. Este artículo explora si los ordenadores cuánticos emergentes —máquinas que aprovechan las reglas de la física cuántica— podrían afinar estas predicciones para problemas de tipo marketing, y lo hace con una mirada clara hacia el hardware actual, imperfecto y "ruidoso".

De los registros de clientes a los circuitos cuánticos
Los autores se centran en una tarea práctica que denominan clasificación de consumidores: predecir qué usuarios interactuarán o adoptarán un servicio digital. Cada usuario se describe mediante un pequeño conjunto de características numéricas, como demografía y comportamiento en la plataforma. En lugar de introducir estos datos directamente en un algoritmo estándar, primero los codifican en los estados de unos pocos bits cuánticos (qubits) usando un circuito cuántico compacto. Este circuito actúa como una transformación de características, remodelando los datos en una forma que puede ser más fácil de separar en dos grupos —"probable que interactúe" y "poco probable que interactúe". Sobre esta transformación cuántica aplican un método de clasificación bien conocido, la máquina de vectores de soporte, en una versión con sabor cuántico llamada SVM de kernel cuántico (Q-SVM).
Probar ideas cuánticas en condiciones realistas
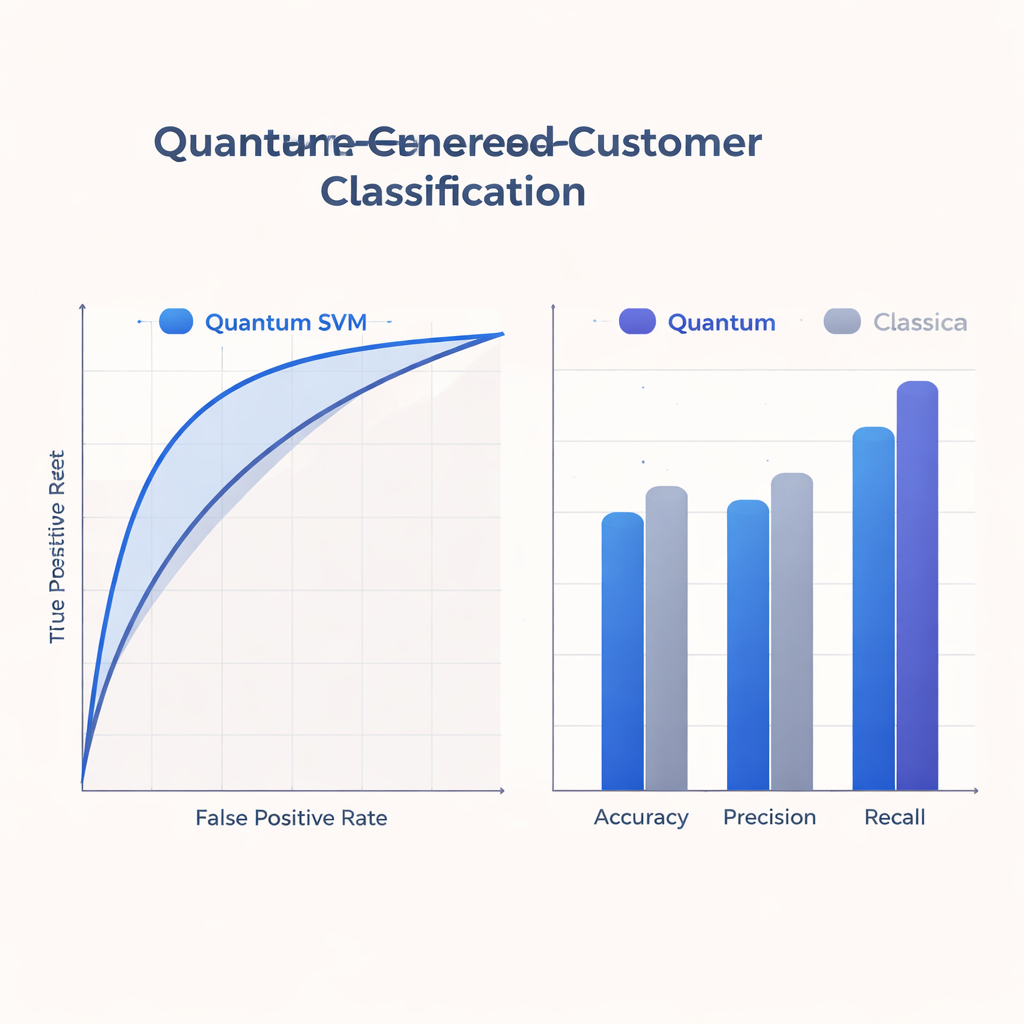
Dado que los dispositivos cuánticos actuales son pequeños y propensos a errores, el estudio se ciñe a circuitos superficiales que coinciden con lo que el hardware de corto plazo puede manejar. El equipo entrena y evalúa su Q-SVM con un conjunto de datos real anonimizado de alrededor de 500 casos de entrenamiento y 125 de prueba con ocho características por usuario, simulando tanto comportamiento cuántico ideal como ruidoso. Comparan el enfoque cuántico con potentes referencias clásicas que usan trucos de kernel populares en ordenadores convencionales. En métricas como precisión, exactitud (accuracy), recall y el área bajo la curva ROC (un resumen de los trade-offs entre detectar positivos y evitar falsas alarmas), la Q-SVM ofrece un rendimiento competitivo o superior, con un recall especialmente fuerte: identifica correctamente una mayor fracción de usuarios realmente interesados que los modelos clásicos.
Garantías teóricas entre bastidores
Más allá del rendimiento bruto, el artículo plantea una pregunta más profunda: ¿cuándo deberían esperarse mejoras con métodos cuánticos? Los autores desarrollan tres resultados teóricos principales. Primero, muestran que si el problema de aprendizaje cumple ciertas condiciones de suavidad y los circuitos cuánticos permanecen superficiales, el proceso de entrenamiento para kernels cuánticos debería converger de forma fiable en un número razonable de pasos. Segundo, proporcionan cotas de separación que sugieren que su extracción de características cuánticas puede, bajo supuestos específicos, aumentar la brecha entre las dos clases de clientes en comparación con transformaciones clásicas —esencialmente facilitando la resolución del problema. Tercero, analizan cómo métodos aproximados pueden reducir drásticamente el coste de trabajar con grandes espacios de características derivados cuánticamente, de modo que el enfoque siga siendo computacionalmente viable.
Qué podría significar esto para los responsables de marketing
Para los equipos de marketing y analítica de clientes, el beneficio más concreto reside en cómo el modelo cuántico equilibra oportunidades perdidas frente a esfuerzos de outreach mal dirigidos. El mayor recall de la Q-SVM implica que es menos probable que pase por alto usuarios que responderían positivamente a una oferta, una ventaja clave en campañas de retención o servicio proactivo. Al mismo tiempo, su precisión y exactitud global se mantienen en un rango comparable al de fuertes referencias clásicas, respaldadas por una curva ROC robusta. Como el método funciona bien a lo largo de distintos umbrales de decisión, los equipos podrían ajustar cuán agresivos o cautelosos ser—priorizando recall o precisión—sin necesidad de volver a entrenar el modelo cada vez.
Un inicio prometedor, no una revolución cuántica (todavía)
Los autores subrayan que sus hallazgos son pasos iniciales, no pruebas de una superioridad cuántica aplastante. Los resultados proceden de simulaciones sobre un único conjunto de datos, no de ejecuciones a gran escala en hardware ni de múltiples mercados distintos. Sus garantías matemáticas también dependen de supuestos idealizados que pueden no cumplirse completamente en dispositivos ruidosos. Aun así, el trabajo demuestra que kernels cuánticos diseñados con cuidado ya pueden igualar o superar ligeramente a buenos métodos clásicos en una tarea de consumo realista, ofreciendo además una vía clara hacia ventajas mayores a medida que el hardware cuántico escala. Para el lector, la conclusión es que el aprendizaje automático cuántico está pasando de una promesa abstracta a herramientas que podrían, algún día, hacer las predicciones de clientes más precisas y flexibles en entornos empresariales reales.
Cita: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Palabras clave: aprendizaje automático cuántico, analítica de marketing, clasificación de clientes, máquinas de vectores de soporte, kernels cuánticos