Clear Sky Science · es
Centinela acústico: clasificación jerárquica del sonido de pasos usando representaciones acústicas de grano fino y grueso para vigilancia táctica
Escuchando pasos ocultos
Imagínese detectar personas moviéndose por un bosque oscuro o a lo largo de una frontera remota sin una sola cámara a la vista—solo escuchando sus pasos. Este estudio explora cómo los sonidos sutiles producidos al caminar pueden convertirse en una potente herramienta de alerta temprana para soldados, policías e investigadores, especialmente en lugares donde las cámaras fallan o la energía es escasa.
Por qué las cámaras no son suficientes
La seguridad moderna a menudo depende de la vigilancia por vídeo, pero las cámaras tienen debilidades claras: necesitan línea de visión directa, consumen mucha energía y pueden ser difíciles de desplegar rápidamente en terrenos abruptos u hostiles. Los puestos de control móviles, la patrulla fronteriza y los equipos antiterroristas pueden operar de noche, bajo follaje denso o en regiones montañosas donde instalar y mantener redes de cámaras es poco práctico. En estas situaciones, el sonido se convierte en una alternativa atractiva. Los micrófonos son ligeros, consumen menos energía y pueden “oír alrededor de las esquinas”, detectando personas antes de que sean visibles. Aunque los pasos son relativamente silenciosos, destacan en muchos entornos tácticos donde el ruido de fondo es bajo, lo que los convierte en una señal prometedora para la alerta temprana y la reconstrucción forense de eventos.
Construyendo una biblioteca real de pasos
Para convertir esta idea en un sistema operativo, los investigadores primero tuvieron que resolver un problema básico: no existía una colección adecuada de grabaciones de pasos del mundo real. Las bases de datos de sonido existentes incluyen algunos pasos principalmente para reconocimiento genérico de sonidos o emparejamiento de identidad, a menudo grabados en condiciones de laboratorio controladas. Normalmente no indican si el sonido provino de un bosque, una carretera o un interior, ni si fue producido por una sola persona o por varias. Por ello, el equipo creó un nuevo recurso llamado conjunto de datos EWFootstep 1.0. Contiene 1.650 clips de audio de 176 voluntarios caminando de forma natural por bosques, carreteras y espacios interiores en tres regiones diferentes de India. Las grabaciones capturan una mezcla de suelas blandas y duras, distintos terrenos y condiciones de campo realistas, como colocación irregular del micrófono. Cada clip incluye al menos 15 pasos y está etiquetado tanto por tipo de entorno como por si presenta a una sola persona o a un grupo.
Enseñando a una máquina a oír como un explorador
Con este conjunto de datos en mano, los autores diseñaron un sistema de escucha que imita cómo podría razonar sobre el sonido un explorador experimentado. En lugar de tratar todas las tareas por igual, su modelo «jerárquico multitarea» primero decide dónde ocurre el sonido—bosque, carretera o interior—y luego, usando ese contexto, estima si se trata de una persona o de varias. El audio se convierte en espectrogramas coloridos que muestran cómo se distribuye la energía a través de las frecuencias a lo largo del tiempo. Un conjunto de capas convolucionales extrae detalles finos ligados a superficies y calzado, como el crujido de las hojas o el golpe de botas sobre el hormigón. Estas características pasan después a un módulo transformer, un motor moderno de procesamiento de secuencias que examina patrones a lo largo de muchos pasos—ritmo, espaciamiento e impactos repetidos—en lugar de sonidos aislados. La codificación posicional ayuda al modelo a mantener el orden temporal, lo cual es esencial para reconocer patrones de marcha.
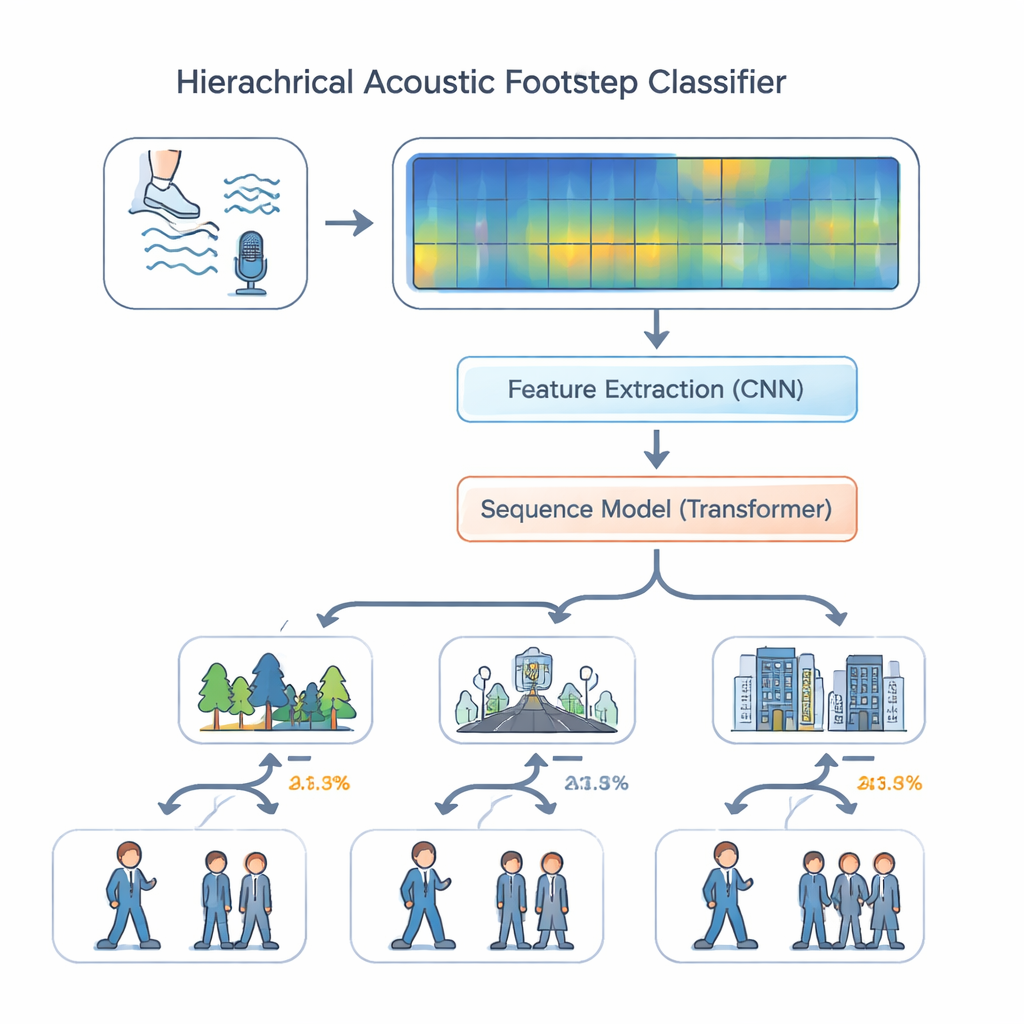
¿Qué tan bien funciona el centinela acústico?
Los investigadores compararon su modelo jerárquico con enfoques más simples, como un clasificador único todo en uno y un diseño multitarea estándar donde el entorno y el número de personas se predicen de forma independiente. También probaron variantes que eliminaban componentes clave como las capas convolucionales o el transformer. En todos los casos, el diseño completo con ambos módulos y codificación posicional fue el que mejor rendimiento dio. En el conjunto de datos EWFootstep 1.0, identificó correctamente el entorno en torno al 96 por ciento de las veces y el número de personas con una precisión similar—sensiblemente mejor que oyentes humanos entrenados, que se quedaron atrás entre 25 y 30 puntos porcentuales. Experimentos adicionales con un conjunto de datos de sonidos de tos mostraron que la misma arquitectura se generaliza bien más allá de los pasos, lo que sugiere que puede manejar tipos de audio cotidiano muy diferentes.
Del campo de batalla a la escena del crimen
Para el público general, la conclusión clave es que los sonidos tenues y cotidianos como los pasos contienen mucha más información de la que solemos percibir. Combinando grandes conjuntos de datos realistas con herramientas avanzadas de reconocimiento de patrones, los autores muestran que un sistema compacto puede decir con fiabilidad qué tipo de lugar está escuchando y cuántas personas hay, casi en tiempo real y sin cámaras. Este «centinela acústico» podría ayudar a proteger patrullas e instalaciones remotas, y su capacidad para diseccionar patrones sonoros sutiles también puede ser útil en la forense de audio, por ejemplo para reconstruir movimientos en una escena del crimen cuando el vídeo no está disponible o no es fiable.
Cita: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Palabras clave: vigilancia acústica, detección de pasos, sistemas de alerta temprana, <keyword>seguridad táctica