Clear Sky Science · es
Aprendizaje automático para la estimación rápida de la intensidad macrosísmica a partir de datos sismométricos en Italia
Por qué importan las evaluaciones rápidas tras un seísmo
Cuando la tierra empieza a temblar, los equipos de emergencias disponen de solo minutos para decidir dónde enviar rescatistas y recursos. Sin embargo, la forma habitual de describir con qué fuerza se percibe un terremoto en la superficie —la intensidad macrosísmica, como la escala de Mercalli usada en Italia— suele lleg ar horas, días o incluso meses después, cuando la gente rellena cuestionarios y los expertos inspeccionan los daños. Este artículo explora cómo el aprendizaje automático moderno puede convertir las primeras lecturas de los sismómetros en mapas rápidos y razonablemente precisos de cuánto se ha sentido un terremoto, ayudando a las autoridades a reaccionar con más rapidez y seguridad.
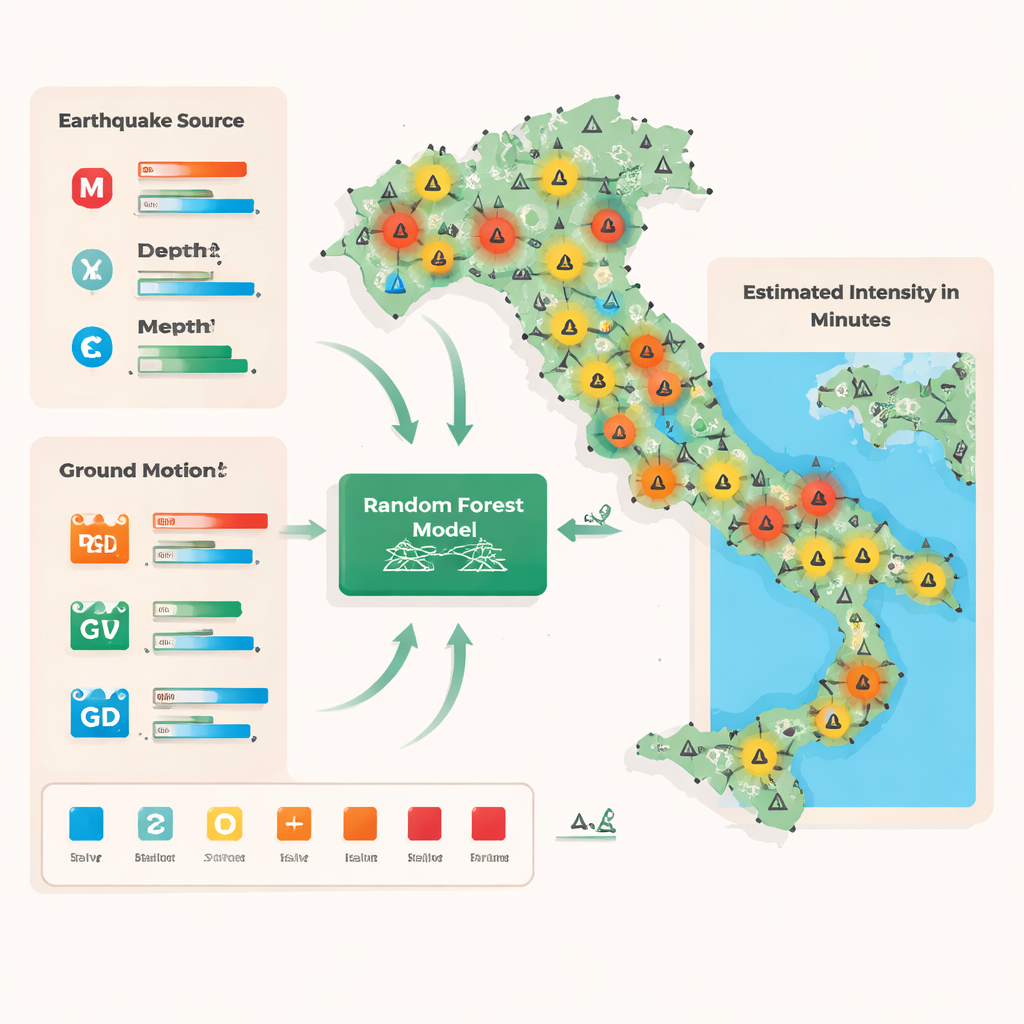
De los testimonios a las estimaciones rápidas
Las estimaciones tradicionales de intensidad en Italia se basan en dos fuentes principales de datos. Una consiste en encuestas de campo realizadas por expertos registradas en una base de datos oficial, que se centran en lugares dañados pero requieren tiempo para organizarse. La otra procede del sistema en línea “Hai Sentito Il Terremoto”, donde los ciudadanos informan lo que sintieron y vieron, aportando muchas observaciones de intensidad baja y moderada. Ambas fuentes miden la intensidad en la escala Mercalli-Cancani-Sieberg, que clasifica el movimiento desde muy débil hasta destructivo según las respuestas humanas y de las edificaciones. Para vincular estas medidas centradas en las personas con las lecturas instrumentales, los autores fusionaron los dos conjuntos de datos alrededor de cada estación sísmica, promediando todas las intensidades reportadas dentro de un radio de 5 km para obtener un valor representativo de esa zona y redondeándolo a una clase entera del 1 al 8.
Enseñar a un bosque de modelos a leer el temblor
Los investigadores plantearon la estimación de la intensidad como un problema de clasificación: dados los primeros valores medidos, predecir cuál de las ocho clases de intensidad corresponderá al entorno de cada estación. Usaron un Random Forest, un conjunto de muchos árboles de decisión que cada uno realiza una serie simple de divisiones «si–entonces» sobre los datos, como combinaciones de magnitud, profundidad, distancia a la fuente y medidas directas del movimiento del suelo como aceleración máxima, velocidad y desplazamiento. Entrenado con 5.466 observaciones procedentes de 523 terremotos en Italia (2008–2020), el modelo aprendió relaciones complejas y no lineales entre lo que registran los sismómetros y lo que reporta la población. Para manejar el hecho de que los temblores fuertes son menos frecuentes en los datos, los autores ajustaron el entrenamiento para que todos los niveles de intensidad contaran por igual, evitando que el modelo se centrara únicamente en los eventos más comunes y débiles.
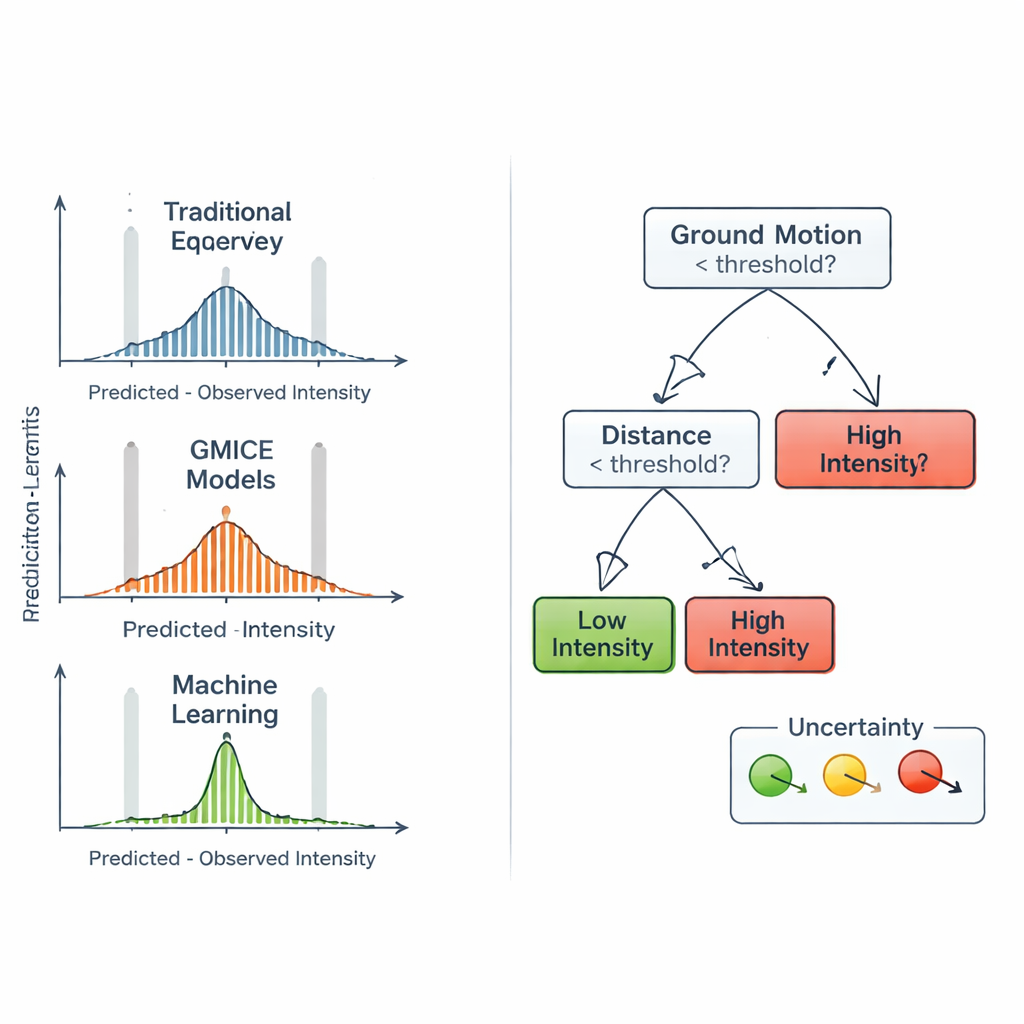
Comprobar frente a reglas ya establecidas
Para evaluar si el enfoque de aprendizaje automático aporta realmente valor, el equipo comparó sus predicciones con dos familias ampliamente utilizadas de relaciones empíricas. La primera, denominada Ecuaciones de Predicción de Intensidad, estima la intensidad principalmente a partir de la magnitud, la profundidad y la distancia del terremoto, asumiendo que el movimiento disminuye con la distancia de forma suave. La segunda, Ecuaciones de Conversión de Movimiento del Suelo a Intensidad, transforma las lecturas instrumentales de movimiento pico en clases de intensidad esperadas. Estas fórmulas son compactas y fáciles de aplicar, pero no pueden capturar completamente cómo la geología local, el parque edificatorio o la dirección de las ondas influyen en la sensación del temblor. Por el contrario, el Random Forest integra de forma natural tanto parámetros de la fuente como medidas del movimiento del suelo, y puede adaptarse a patrones sutiles en el conjunto de datos italiano sin prescribir una forma matemática rígida de antemano.
Ver dentro de la caja negra y sus límites
Como los gestores de emergencias necesitan entender la base de decisiones automatizadas, los autores construyeron árboles de decisión «sustitutos» más simples que imitan el comportamiento del Random Forest. Estos árboles más pequeños pueden representarse como diagramas, mostrando qué umbrales de movimiento del suelo separan baja de alta intensidad y dónde variables como la aceleración y la velocidad dominan. Este análisis reveló que las medidas directas del movimiento del suelo, en particular la aceleración y la velocidad pico, tienen más peso que la magnitud o la profundidad por sí solas. Los autores también introdujeron una manera simple de marcar la incertidumbre de cada predicción del árbol sustituto, usando medidas de cuán mezclados están los ejemplos de entrenamiento en cada rama final. Al mismo tiempo, hallaron que las intensidades muy fuertes siguen siendo difíciles de predecir, en parte porque son naturalmente raras en el registro histórico, lo que conduce a subestimaciones ocasionales de los niveles de sacudida más altos.
Prueba en el mundo real durante un reciente terremoto italiano
El equipo evaluó su marco en un evento real notable: un terremoto de magnitud 5,5 frente a la costa adriática cerca de Pesaro-Urbino en 2022. En unos 15 minutos, los sismólogos disponían de la información necesaria sobre la fuente y el movimiento del suelo, pero solo se habían recibido alrededor de 90 informes públicos de intensidad, ofreciendo una imagen muy fragmentaria. Usando solo los datos instrumentales, el Random Forest y su árbol sustituto generaron estimaciones detalladas de intensidad alrededor de cientos de estaciones en menos de dos segundos en un ordenador estándar. Al compararlas más tarde con el mapa mucho más denso construido a partir de más de 12.000 informes ciudadanos recogidos durante días, los mapas del aprendizaje automático capturaron tanto la extensión general del área afectada como la distribución del temblor moderado de forma notablemente buena, igualando o superando a las ecuaciones clásicas.
Qué significa esto para las personas que viven con terremotos
En conjunto, el estudio muestra que un sistema de aprendizaje automático cuidadosamente entrenado puede tomar los primeros minutos de datos de sismómetros y producir mapas rápidos y razonablemente transparentes del impacto de un terremoto. Estos mapas no sustituyen a las encuestas detalladas ni a los informes de la población, pero pueden salvar la peligrosa brecha temprana cuando las autoridades deben elegir dónde enviar ambulancias, bomberos e inspectores estructurales con información muy limitada. Combinando algoritmos avanzados con modelos simplificados interpretables y señales básicas de incertidumbre, el marco ofrece un paso práctico hacia una respuesta más rápida y mejor informada ante terremotos en Italia y podría adaptarse a otras regiones que enfrentan riesgos sísmicos similares.
Cita: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Palabras clave: intensidad del terremoto, aprendizaje automático, random forest, riesgo sísmico, Italia