Clear Sky Science · es
Red de fusión de mejora multi‑característica para la segmentación semántica de imágenes de teledetección
Mapas más nítidos desde el cielo
Cada día, satélites y drones capturan imágenes detalladas de nuestras ciudades y tierras agrícolas. Convertir esas imágenes en bruto en mapas claros, píxel a píxel, de carreteras, tejados, árboles y cultivos es esencial para tareas como vigilar la salud de las cosechas o planificar nuevos barrios. Este artículo presenta una nueva forma de hacer esos mapas más precisos, especialmente a lo largo de los límites difíciles donde edificios, campos y vegetación se mezclan.
Por qué las imágenes aéreas son difíciles de interpretar
Las imágenes de teledetección se ven distintas a las fotos cotidianas. Se toman desde gran altura, a menudo con ángulos pronunciados y bajo iluminación variable. Diferentes objetos pueden parecer muy similares desde el aire: un aparcamiento de hormigón y un tejado plano pueden compartir casi el mismo color; distintos tipos de cultivo pueden mostrar patrones confusos y parecidos. Al mismo tiempo, el mismo tipo de objeto puede verse muy distinto según las sombras, la humedad o los ajustes de la cámara. Los programas tradicionales, e incluso muchos sistemas modernos de aprendizaje profundo, tienen dificultades para mantener los contornos nítidos en estas condiciones. A menudo difuminan los bordes entre categorías o pasan por alto detalles pequeños como coches aparcados o canales de riego estrechos.
Ver el panorama general y las líneas finas
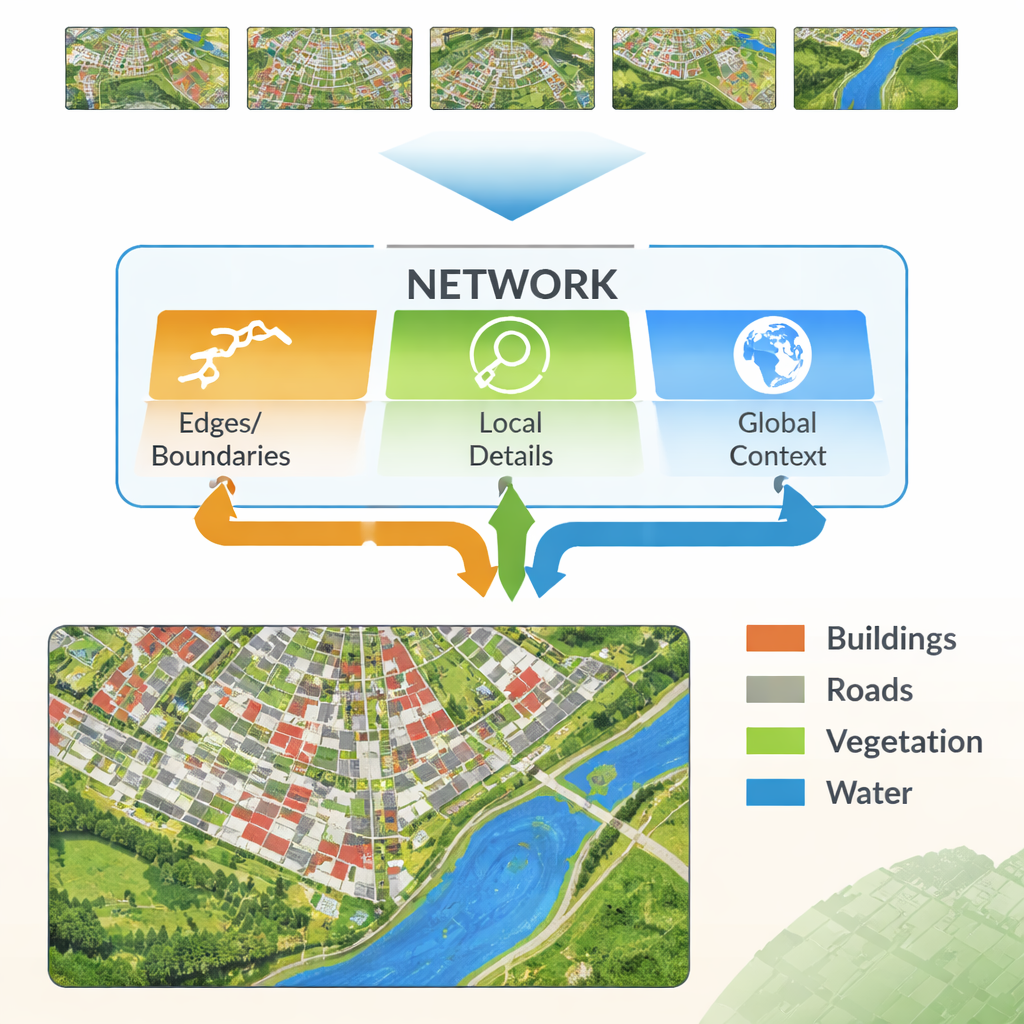
Las redes neuronales modernas aprenden pasando una imagen por muchas capas. Las capas iniciales captan detalles finos como líneas y texturas, mientras que las capas más profundas aprenden patrones amplios como “esta región probablemente son edificios”. El reto es que combinar estos dos tipos de información no es sencillo. Los detalles de bajo nivel pueden ser ruidosos y redundantes, y los patrones de alto nivel pueden diluir los bordes, produciendo contornos borrosos. Los autores proponen una nueva arquitectura, llamada Red de Fusión y Mejora Multi‑Característica (MFEF‑UNet), diseñada explícitamente para equilibrar el detalle local con la comprensión global. Lo hace tratando los bordes, los patrones locales y el contexto amplio como fuentes de información separadas pero cooperantes.
Resaltar bordes y fusionar características
Una idea clave del nuevo método es tomar herramientas simples y clásicas de detección de bordes e integrarlas en un flujo moderno de aprendizaje profundo. Un Módulo de Realce de Bordes toma las características más tempranas de la red y las procesa con operadores muy buenos para encontrar límites—similar a cómo un software básico de edición de imágenes detecta contornos. Estos mapas de bordes realzados se generan a varias escalas, de modo que la red vea tanto límites finos como gruesos. Un Módulo de Fusión Multi‑Característica reúne entonces tres corrientes: la información de alto nivel en evolución (“¿qué es esta región?”), la reconstrucción de detalles por parte del decodificador y los mapas de bordes. En lugar de simplemente apilarlos, el módulo usa un mecanismo parecido a la atención para que las características semánticas puedan “preguntar” a las corrientes de borde y detalle dónde están realmente los límites y las estructuras pequeñas, y ajustar la representación final en consecuencia.
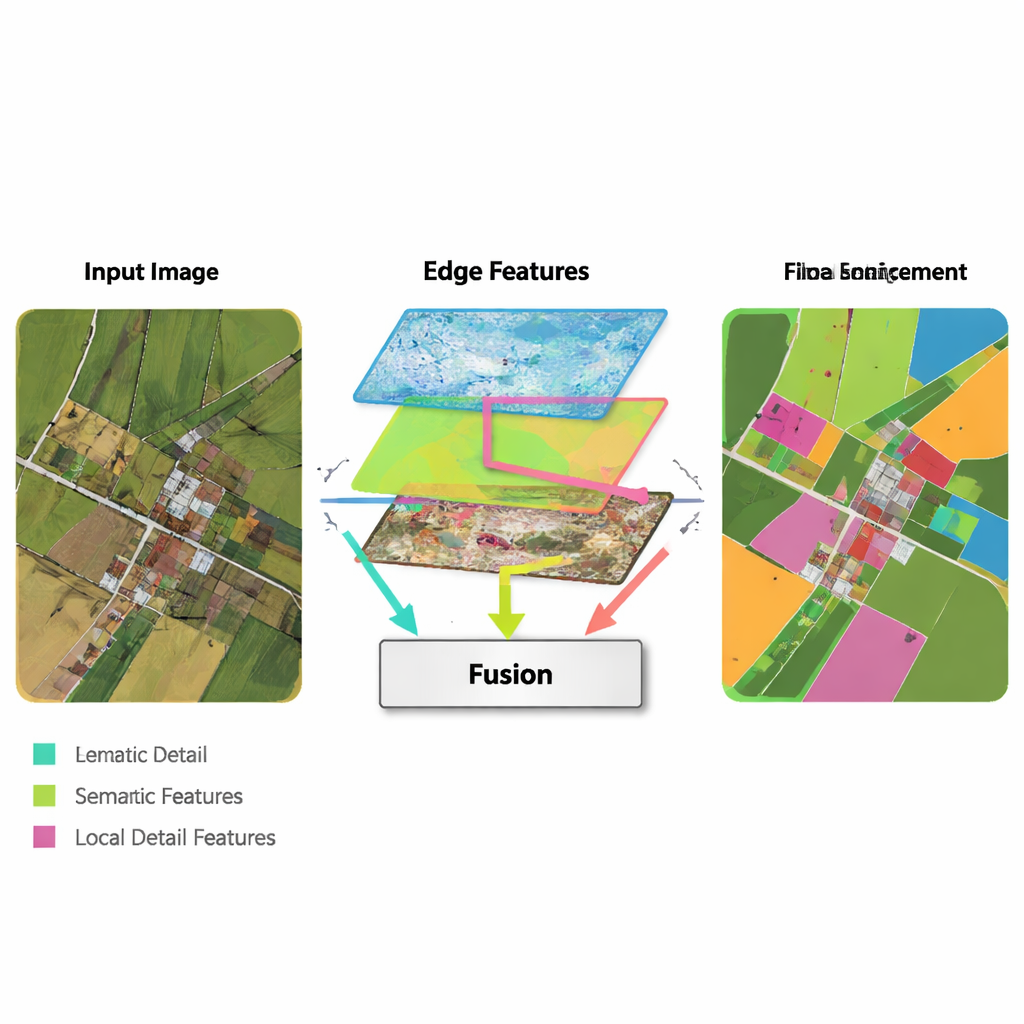
Equilibrar detalle local y contexto global
Otro componente de MFEF‑UNet es un Módulo de Mejora de Características Local‑Global. Para un profano, esto puede entenderse como la parte de la red que evita perder de vista el bosque mientras se enfocan los árboles—o la ciudad mientras se refinan los edificios. La imagen se divide en subventanas manejables para que los píxeles cercanos puedan modelarse juntos, preservando formas y texturas. Tras este modelado local, las ventanas se cosen de nuevo en una imagen completa y una segunda pasada permite que la información fluya entre regiones distantes. Este proceso en dos pasos ayuda al modelo a respetar tanto las estructuras pequeñas, como coches y límites estrechos de parcelas, como patrones a gran escala, como manzanas de viviendas o cuerpos de agua continuos.
Probar el método en ciudades y campos
Los investigadores evaluaron su enfoque en tres conjuntos de datos públicos: dos que cubren localidades y ciudades europeas, y una gran colección de imágenes agrícolas de Estados Unidos. Estos conjuntos contienen una mezcla de tejados, carreteras, vegetación, agua y patrones sutiles de cultivos. En los tres puntos de referencia, MFEF‑UNet produjo de manera consistente mapas más precisos que una variedad de métodos líderes, incluidos redes convolucionales clásicas, arquitecturas basadas en Transformers y modelos más recientes de “estado‑espacio”. Sus ventajas fueron más visibles en contornos complejos de edificios, agrupaciones de objetos pequeños como vehículos y estructuras largas y finas como canales de drenaje o filas de cultivo—lugares donde otros métodos tienden a fragmentar o difuminar la segmentación.
Qué implica esto en la práctica
En términos prácticos, la red propuesta convierte imágenes aéreas en mapas de cobertura del suelo más limpios y fiables. Los planificadores urbanos pueden medir con mayor confianza las áreas edificadas, los ingenieros pueden trazar mejor carreteras y tejados, y los agrónomos pueden delimitar con mayor precisión parcelas, cursos de agua y zonas de estrés de cultivos. Aunque los componentes adicionales de borde y fusión introducen algo de cálculo extra, el diseño general se mantiene razonablemente eficiente y ofrece mejoras claras en precisión y robustez. Para los no especialistas, la conclusión es que al enfatizar deliberadamente los bordes y fusionar cuidadosamente distintos tipos de señales visuales, los ordenadores pueden ahora interpretar imágenes satelitales y de drones con mayor nitidez—acercándonos a mapas del mundo más precisos y actualizados.
Cita: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Palabras clave: teledetección, segmentación semántica, imágenes satelitales, aprendizaje profundo, mapeo de cubiertas del suelo