Clear Sky Science · es
De los datos a las decisiones: el uso de la IA explicable para predecir el rendimiento de la soja en los principales países productores
Por qué importan pronósticos de cultivo más inteligentes
Desde los precios en el supermercado hasta el comercio global, la humilde soja juega un papel sorprendentemente grande en la vida cotidiana. Gobiernos, operadores comerciales y agricultores necesitan conocer el tamaño de la cosecha meses antes de que las cosechadoras entren en los campos. Hoy, potentes herramientas de inteligencia artificial (IA) pueden cribar montañas de datos meteorológicos y satelitales para realizar esos pronósticos, pero muchos de estos modelos actúan como “cajas negras”, ofreciendo poca información sobre por qué dan una respuesta concreta. Este estudio explora un nuevo tipo de IA explicable que no solo predice los rendimientos de soja en los principales países productores del mundo, sino que también muestra con claridad qué factores impulsan esas predicciones.
Tres países que alimentan al mundo
Los investigadores se centraron en los tres países que dominan el suministro mundial de soja: Estados Unidos, Brasil y Argentina, que juntos producen más del 80% de la soja mundial. Se acercaron a una escala fina: condados en EE. UU. y regiones equivalentes pequeñas en Brasil y Argentina, usando datos recientes de 2018 a 2022. Para cada región, reunieron un panorama detallado de las condiciones de cultivo: registros meteorológicos minuciosos, propiedades del suelo y varios tipos de datos satelitales que siguen el crecimiento de la planta, el estado hídrico e incluso un tenue brillo de la fotosíntesis conocido como fluorescencia clorofílica inducida por el sol (SIF). En total, se extrajeron 154 características numéricas diferentes para describir cada temporada de cultivo antes de introducirlas en los modelos.
De las canalizaciones de datos a las máquinas de aprendizaje
Para manejar este aluvión de información, el equipo construyó una canalización de procesamiento estandarizada. Alinearon todos los conjuntos de datos en espacio y tiempo usando calendarios de cultivo, suavizaron señales satelitales ruidosas y resumieron la temporada de crecimiento con estadísticas como promedios, extremos y variabilidad. Luego entrenaron tres tipos de modelos para predecir rendimientos: Random Forest (RF), un caballo de batalla ampliamente usado en aprendizaje automático; Perceptrón Multicapa (MLP), una red neuronal profunda clásica; y Kolmogorov–Arnold Networks (KAN), una arquitectura más reciente diseñada desde sus cimientos para ser más interpretable. Para evitar engañarse con puntuaciones excesivamente optimistas, los autores dividieron cuidadosamente los datos en bloques espaciales para que los modelos se evaluasen en regiones que no habían “visto” durante el entrenamiento.
Abrir la caja negra de la IA
Lo que distingue este trabajo no es solo la precisión de los pronósticos, sino cómo los modelos se explican a sí mismos. RF y MLP fueron sondeados con herramientas estándar que muestran cuánto importa cada característica de entrada para sus predicciones. KAN va un paso más allá: representa los vínculos entre entradas y salidas como curvas unidimensionales suaves que pueden trazarse e inspeccionarse. Esto permite a los investigadores ver literalmente cómo, por ejemplo, un cambio en la SIF o en la humedad del suelo empuja el rendimiento hacia arriba o hacia abajo. A lo largo de países y métodos, un patrón fue claro: la SIF, la señal satelital ligada directamente a la fotosíntesis, se colocó de manera consistente entre los predictores más importantes del rendimiento de la soja. Otros factores clave variaron por región: en Estados Unidos destacaron señales de vegetación relacionadas con el agua, mientras que en Brasil y Argentina la temperatura y la humedad del suelo jugaron papeles más fuertes.
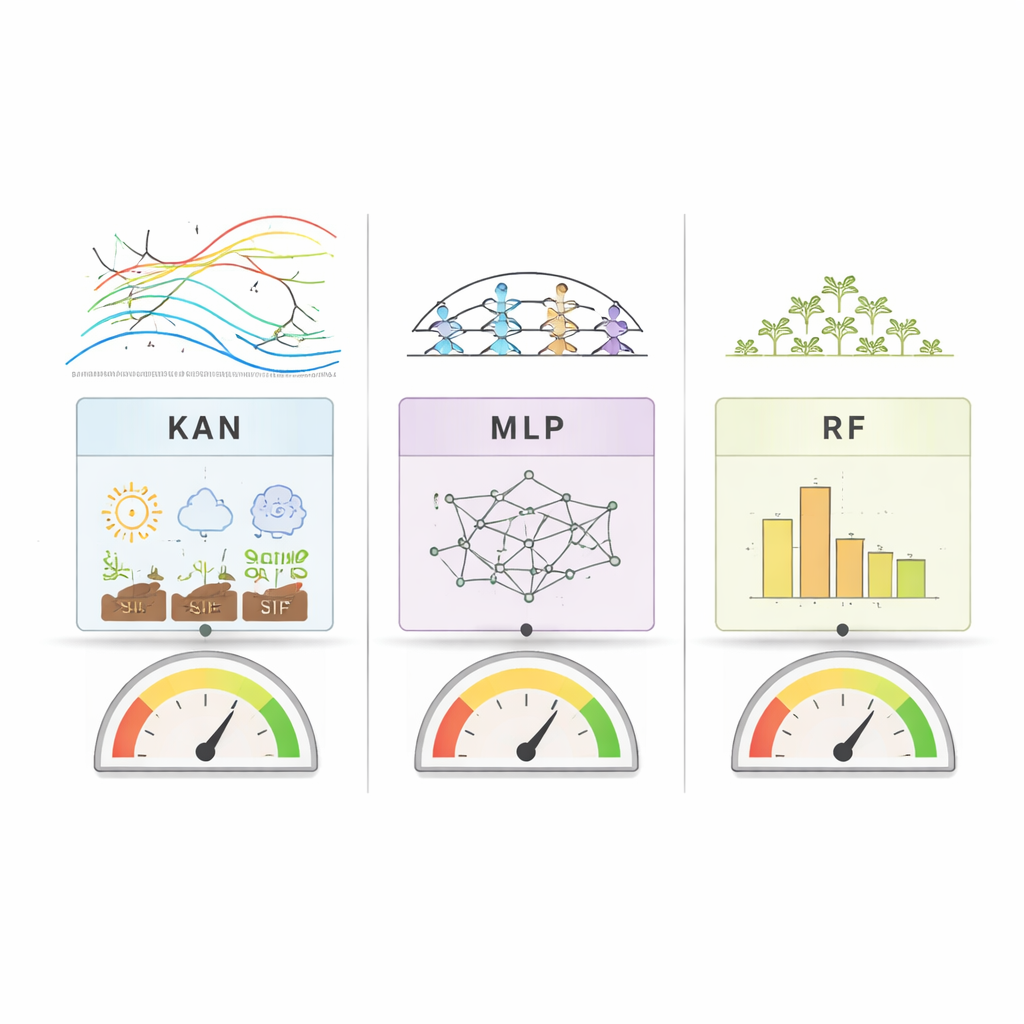
¿Qué tan bien funcionaron los modelos?
Cuando los investigadores compararon la precisión de los modelos, ningún método ganó rotundamente en todas las situaciones. En Estados Unidos, donde los rendimientos fueron relativamente estables año tras año, Random Forest rindió algo mejor en general, pero KAN y MLP quedaron cerca. En Brasil, con rendimientos más volátiles y un conjunto de datos mayor, los tres modelos alcanzaron alta precisión, aunque tuvieron cierta dificultad para predecir rendimientos muy altos. En Argentina, donde los datos eran más limitados, KAN generalmente superó a la línea base de aprendizaje profundo (MLP) y se acercó a Random Forest. Estos resultados sugieren que KAN puede igualar a los modelos tradicionales en conjuntos de datos agrícolas difíciles y pequeños, al tiempo que ofrece una transparencia mucho mayor sobre cómo llega a sus conclusiones.
Qué significa esto para los agricultores y la seguridad alimentaria
Para los responsables de la toma de decisiones en el mundo real, poder confiar en un modelo puede ser tan importante como la precisión bruta. Este estudio muestra que enfoques de IA explicable como KAN pueden ofrecer pronósticos competitivos del rendimiento de la soja mientras revelan claramente qué señales ambientales y del cultivo importan más. Esa visibilidad ayuda a los científicos a diagnosticar errores, incorporar conocimientos agronómicos expertos y adaptar los modelos a nuevas regiones o climas cambiantes. A largo plazo, estas herramientas transparentes podrían integrarse en sistemas nacionales de monitoreo de cultivos, brindando a agricultores, planificadores y mercados advertencias más tempranas y fiables sobre cosechas pobres o cosechas abundantes, y apoyando sistemas alimentarios más resilientes y sostenibles.
Cita: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Palabras clave: predicción del rendimiento de la soja, IA explicable, teledetección, modelado agrícola, seguridad alimentaria