Clear Sky Science · es
Seguidor siamés de doble rama potenciado con transformadores con regresión consciente de la confianza y actualización adaptativa de la plantilla
Enseñar a las máquinas a seguir un objeto en una escena concurrida
Desde los coches autónomos hasta las cámaras de seguridad domésticas y los drones, muchos dispositivos modernos necesitan seguir un único objeto en movimiento dentro de un mundo concurrido y cambiante. Esta tarea, llamada seguimiento visual de objetos, parece sencilla para los humanos pero resulta sorprendentemente difícil para las máquinas: personas pasan delante de la cámara, cambia la iluminación, el objeto se aleja o queda oculto temporalmente. Este artículo presenta TSDTrack, un nuevo sistema de seguimiento que utiliza los avances recientes en aprendizaje profundo y transformadores para mantenerse más firmemente fijado en un objetivo en condiciones del mundo real.
Por qué es tan difícil seguir una sola cosa
Un seguidor normalmente ve el objeto con claridad solo en el primer fotograma de un vídeo y luego debe seguir encontrándolo a medida que la escena cambia. Los métodos tradicionales confiaban en características de imagen diseñadas a mano o en una red neuronal que comparaba el primer fotograma (la "plantilla") con cada nuevo fotograma. Estos sistemas antiguos presentaban tres grandes debilidades. Primero, normalmente mantenían la plantilla original fija, por lo que si el objeto giraba, quedaba parcialmente cubierto o cambiaba de tamaño, el seguidor tenía dificultades. Segundo, a menudo se centraban en un único nivel de detalle de la imagen, perdiendo la combinación de bordes finos y contexto amplio que ayuda a los humanos a reconocer los objetos. Tercero, no sabían cuándo dudar: producían un cuadro alrededor del supuesto objeto sin una idea clara de cuán fiable era esa estimación, lo que los hacía propensos a desviarse hacia el fondo.
Mezclando contexto global con detalles finos
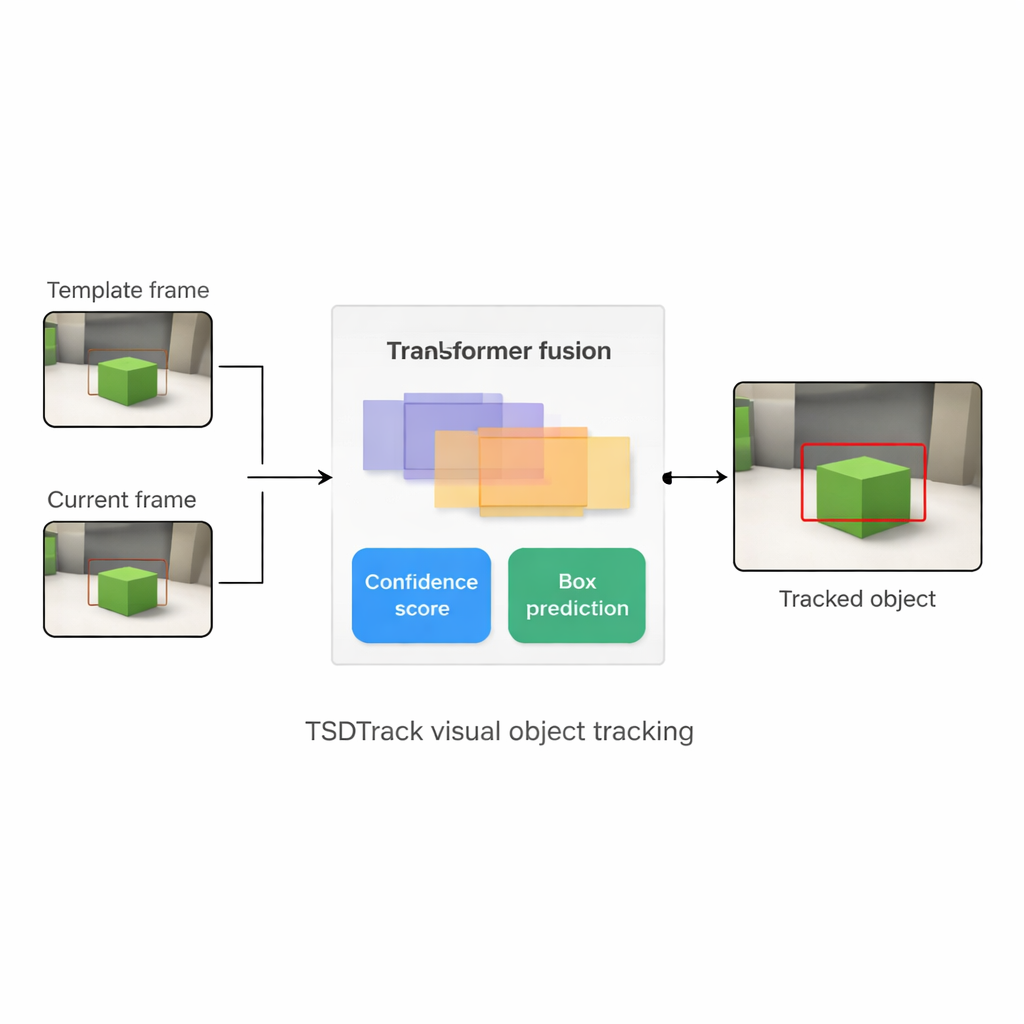
TSDTrack aborda estos problemas combinando una configuración clásica de seguimiento "siamés" con un transformador, el mismo tipo de modelo basado en atención que ha transformado las tareas de lenguaje y visión. El sistema usa una red profunda para extraer características de dos entradas: un parche pequeño que define el objetivo y un parche mayor que contiene el área de búsqueda actual. En lugar de confiar en una sola escala de características, extrae información de varias capas de la red, que representan bordes, formas y patrones a nivel de objeto. Un módulo de fusión basado en transformador aprende entonces a mezclar estas capas para que el seguidor entienda tanto dónde están las cosas en la imagen como cómo se relacionan con la escena en general. Esto le ayuda a distinguir el objetivo de objetos similares y del desorden, incluso cuando la vista es ruidosa o está parcialmente bloqueada.
Saber cuán seguro está realmente el seguidor
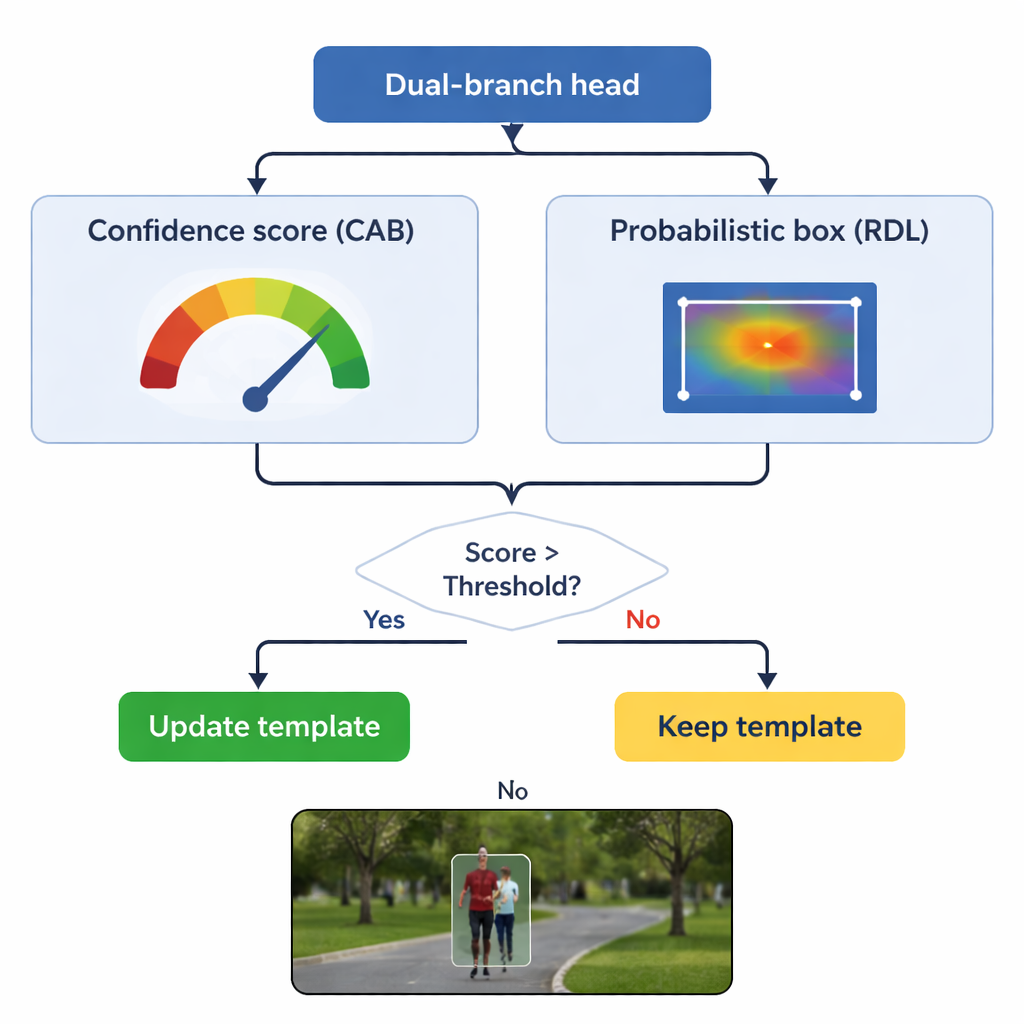
El corazón de TSDTrack es una cabeza de predicción de doble rama que divide la tarea en dos preguntas relacionadas: "¿Dónde está el objeto?" y "¿Cuánto debemos confiar en esta respuesta?" Una rama estima una puntuación de confianza que refleja no solo cuánto se parece el objetivo, sino también qué tan bien el cuadro predicho se solapa con las regiones probables del objeto. La otra rama trata las coordenadas del cuadro no como una única conjetura, sino como una distribución de probabilidad sobre muchas posiciones posibles, lo que permite al modelo representar la incertidumbre. Cuando la imagen está clara, la distribución se vuelve nítida y el cuadro es preciso; cuando el objeto está desenfocado o parcialmente oculto, la distribución se expande. Esta visión probabilística conduce a colocaciones de cuadro más suaves y estables en comparación con los seguidores antiguos que hacían una única predicción rígida.
Actualizar la memoria sin olvidar la original
Un peligro clave en el seguimiento es la "deriva de plantilla": si el modelo sigue actualizando su idea del objeto con fotogramas erróneos, puede aprender lentamente el fondo en su lugar. TSDTrack aborda esto dejando que su rama de confianza actúe como guardián. El sistema actualiza su plantilla interna solo cuando la puntuación de confianza está por encima de un umbral elegido y, aun así, mezcla la información nueva con la vista original de forma gradual en lugar de reemplazarla por completo. Esta actualización selectiva permite que el seguidor se adapte a cambios genuinos, como una persona que se gira o un coche que rota, sin dejarse engañar por oclusiones momentáneas o distracciones. La plantilla original también se mantiene en reserva como referencia estable en caso de que actualizaciones posteriores resulten engañosas.
Qué significan los resultados en la práctica
Los autores probaron TSDTrack en varios bancos de pruebas de seguimiento ampliamente usados, incluidos vídeos largos, movimiento rápido, tomas aéreas desde drones y escenas con mucho desorden. En todas estas pruebas, el nuevo método superó de forma consistente a muchos de los principales seguidores en precisión (qué tan cerca está el cuadro del objeto real) y robustez (con qué poca frecuencia pierde por completo el objeto), manteniéndose lo suficientemente rápido para su uso en tiempo real en hardware moderno. Para un lector no especialista, la conclusión es que TSDTrack puede mantener la atención en un objetivo elegido de forma más fiable en las condiciones desordenadas que presentan las cámaras del mundo real. Al combinar razonamiento multiescala con transformadores, una estimación de su propia confianza y una actualización cuidadosa de la plantilla, ofrece un bloque de construcción más fiable para aplicaciones como la conducción autónoma, la vigilancia inteligente y los robots inteligentes.
Cita: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Palabras clave: seguimiento visual de objetos, seguimiento basado en transformadores, redes siamesas, visión por computador, sistemas autónomos