Clear Sky Science · es
Un enfoque de aprendizaje automático basado en satélites para estimar la temperatura media diaria del aire a alta resolución en una megaciudad de Brasil
Por qué el calor de la ciudad no es igual en todas partes
En un día caluroso en una gran ciudad, la temperatura que se percibe en una calle arbolada puede ser muy distinta de la que experimenta alguien en una plaza de hormigón a pocas manzanas. Sin embargo, la mayoría de los estudios sobre salud y clima siguen tratando a una ciudad entera como si tuviera una única temperatura. Este artículo muestra cómo los científicos usaron satélites, modelos meteorológicos y aprendizaje automático para cartografiar las temperaturas diarias en São Paulo, Brasil, con gran detalle, ayudando a revelar quiénes están realmente expuestos a calor peligroso y dónde son más necesarias las medidas de enfriamiento.
Tomando la temperatura de la ciudad en alta definición
Los registros tradicionales de temperatura dependen de un número limitado de estaciones meteorológicas, a menudo concentradas cerca de aeropuertos o en distritos más acomodados. Eso dificulta ver cómo se distribuye el calor por los barrios reales, especialmente en ciudades grandes y en países de ingresos bajos y medios, donde las redes de monitoreo son escasas. Los investigadores se centraron en São Paulo, una megaciudad vasta y muy heterogénea de más de 22 millones de habitantes. Su objetivo fue estimar la temperatura media diaria del aire para cada cuadrado de 500 por 500 metros en la zona metropolitana durante cinco años, de 2015 a 2019, creando uno de los conjuntos de datos de temperatura más detallados disponibles en Sudamérica.
Combinando satélites, modelos meteorológicos y sensores en tierra
Para construir este panorama de alta resolución, el equipo combinó varios tipos de datos de acceso libre. Reunieron mediciones de 48 estaciones en tierra, que proporcionan las lecturas más directas de la temperatura del aire pero solo en puntos específicos. Luego incorporaron observaciones satelitales de la temperatura de la superficie terrestre, el ángulo del sol y la reflectividad del suelo, junto con información sobre humedad, viento y presión procedente de un producto global de “reanálisis” meteorológico que reconstruye el estado horario del tiempo en una rejilla gruesa. Estos componentes se remuestrearon para ajustarlos a la malla de 500 metros y se limpiaron para rellenar huecos debidos a nubes o a pases satelitales faltantes. En total, probaron 23 posibles variables predictoras que podrían ayudar a explicar cómo varía el calor en el espacio y el tiempo.
Entrenando una máquina que lea el calor
En lugar de usar una simple ecuación lineal, los científicos recurrieron a un Random Forest, un método de aprendizaje automático popular que construye muchos árboles de decisión y promedia sus resultados. Este enfoque es adecuado para descubrir relaciones complejas y no lineales, como la forma en que la temperatura responde de manera distinta al calor de la superficie, la humedad y el viento en diferentes partes de la ciudad o en distintas épocas del año. Para evitar sobreajustar a las particularidades de unas pocas estaciones, emplearon un proceso escalonado de selección de variables que conserva solo las que realmente mejoran las predicciones, y validaron el modelo de dos maneras: dejando fuera repetidamente grupos de estaciones durante el entrenamiento y reservando cinco estaciones enteras como prueba externa rigurosa de cómo funciona el modelo en ubicaciones nuevas.
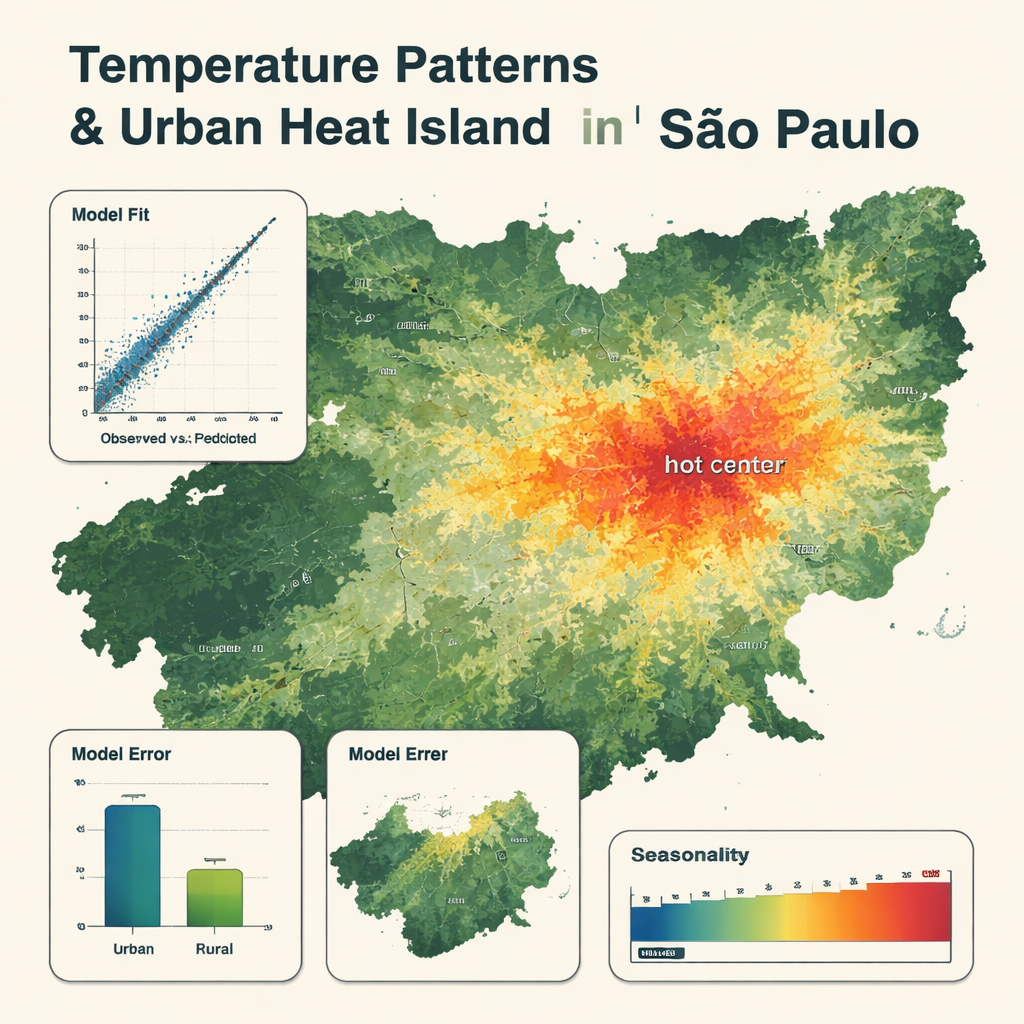
Qué revelan los mapas detallados
El modelo final utilizó solo ocho variables clave, encabezadas por la temperatura del aire del producto meteorológico global, con la temperatura de superficie satelital y la humedad también desempeñando papeles importantes. Reprodujo las lecturas de las estaciones con gran fidelidad, con un error medio de alrededor de 0,8 °C y una concordancia muy alta entre las temperaturas observadas y las predichas. Los mapas muestran patrones claros: zonas más frescas sobre bosques, montañas y grandes embalses, y zonas más calientes en el centro urbano densamente construido, donde las temperaturas pueden ser hasta 5 °C más altas que en las áreas rurales cercanas. El modelo captó las oscilaciones estacionales, con las condiciones más cálidas de diciembre a marzo y las más frías de mayo a agosto. Fue algo menos preciso en zonas rurales y tendió a suavizar los días más extremos de calor y frío, pero aun así superó a un modelo de regresión multilineal más tradicional usando las mismas entradas.
Por qué estos mapas importan para la salud de las personas
Al convertir mediciones dispersas y capturas satelitales en estimaciones diarias de temperatura a escala de calle, este trabajo ofrece una herramienta poderosa para la salud pública y la planificación urbana en São Paulo y más allá. Los investigadores pueden ahora estudiar cómo el calor afecta a distintos barrios, incluyendo asentamientos informales que a menudo faltan en los registros oficiales, e identificar dónde los residentes están en mayor riesgo durante las olas de calor. Como el método se basa completamente en datos abiertos y software estándar, puede adaptarse a otras ciudades que dispongan de algunas estaciones en tierra y cobertura satelital similar. En términos sencillos, el estudio muestra que ahora podemos “ver” el calor urbano con mucho más detalle, proporcionando una base esencial para una adaptación climática más equitativa y medidas de protección dirigidas a las comunidades vulnerables.
Cita: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Palabras clave: calor urbano, aprendizaje automático, datos satelitales, São Paulo, temperatura del aire