Clear Sky Science · es
Identificación en tiempo real de ataques de phishing mediante extensiones de navegador mejoradas con aprendizaje automático
Por qué los sitios web falsos son un problema de todos
Cada día, las personas reciben mensajes que parecen proceder de su banco, de un servicio de paquetería o del lugar de trabajo, pero algunos de ellos son trampas cuidadosamente preparadas. Las estafas de phishing emplean correos electrónicos y sitios web que imitan a los reales para robar contraseñas, números de tarjeta de crédito y otros datos personales. A medida que los delincuentes se vuelven más hábiles en reproducir sitios auténticos, las listas negras sencillas y el instinto ya no bastan. Este artículo describe un nuevo complemento para el navegador que supervisa sigilosamente las páginas que visitas y utiliza aprendizaje automático para señalar en tiempo real los sitios peligrosos, con el objetivo de ofrecer a los usuarios comunes una protección fuerte sin exigirles convertirse en expertos en seguridad.
Cómo los ataques modernos de phishing nos engañan
El phishing se ha convertido en uno de los delitos en línea más frecuentes a nivel mundial, responsable de una gran parte de los incidentes cibernéticos y pérdidas económicas reportadas. Los atacantes envían correos persuasivos que instan a actuar con rapidez —“verifica tu cuenta”, “actualiza tu pago”, “rastrea tu paquete”— y dirigen a las víctimas a sitios falsos que se parecen mucho a páginas reales de bancos, tiendas o servicios en la nube. Muchos de estos sitios ahora usan certificados HTTPS válidos y diseños cuidados, por lo que advertencias antiguas como “no hay icono de candado” o “página fea” ya no sirven. Encuestas e informes de delitos muestran que los adultos entre los 20 y los 40 años son objetivos frecuentes, y los equipos de seguridad siguen muy preocupados por las estafas por correo que consiguen pasar los filtros.
Una mirada más inteligente a las direcciones web y la apariencia de la página
Los investigadores sostienen que el lugar más seguro para detener el phishing es dentro del propio navegador, en el momento en que se carga una página. Su extensión para Google Chrome (y navegadores compatibles) examina dos pistas principales: la dirección web en sí y la apariencia de la página. De cada sitio extrae detalles “lexicales” de la URL, como longitud, símbolos inusuales o subdominios sospechosos; detalles “estructurales” y del dominio, como tráfico y datos de registro; y señales “visuales” como bloques de diseño, colores y logotipos. Un navegador sin interfaz renderiza cada página de forma controlada, la divide en regiones rectangulares y registra dónde aparecen formularios, logotipos y barras de navegación. A continuación compara esta huella visual con las de sitios de confianza, buscando copias casi idénticas que puedan ser fraudulentas.
Usar ‘lobos’ digitales para escoger las pistas más reveladoras
Dado que el sistema recopila docenas de medidas de cada sitio, debe decidir cuáles realmente ayudan a separar las estafas de las páginas seguras. Para ello, los autores recurren a un algoritmo inspirado en cómo cazan los lobos grises. En este “Optimizador Lobo Gris”, muchos conjuntos candidatos de características compiten y el algoritmo converge gradualmente en un subconjunto compacto que ofrece el mejor equilibrio entre detectar sitios de phishing y evitar falsas alarmas. Estas características seleccionadas se introducen luego en tres modelos de aprendizaje automático—Máquina de Vectores de Soporte, Árbol de Decisión y, especialmente, Bosque Aleatorio, que combina muchos árboles de decisión en un conjunto robusto. El entrenamiento utiliza 80.000 sitios web extraídos de colecciones públicas como PhishTank y archivos académicos, con técnicas adicionales para manejar el desequilibrio entre sitios legítimos y maliciosos.
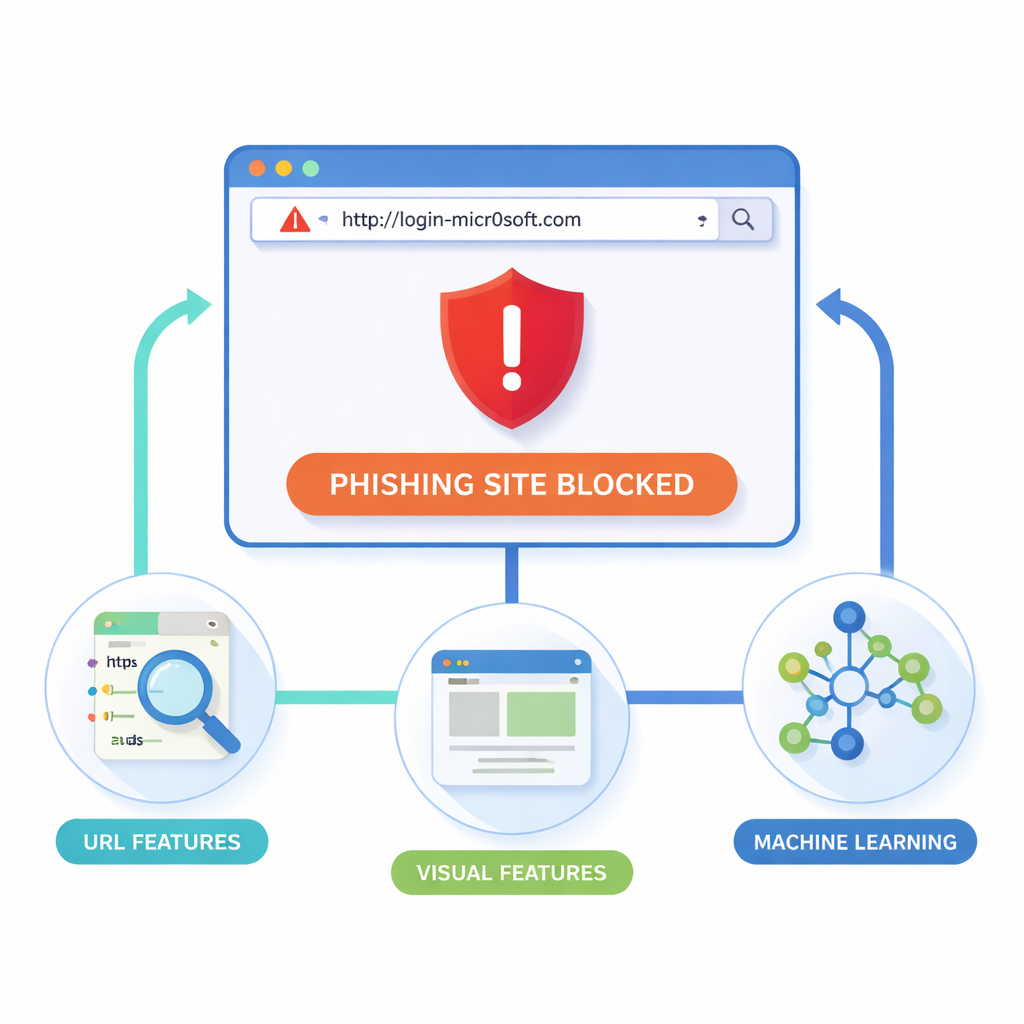
Convertir modelos de laboratorio en una herramienta útil para el navegador
El modelo optimizado de Bosque Aleatorio alcanzó alrededor de un 98–99 % de precisión y un Coeficiente de Correlación de Matthews cercano a 0,96, una medida estricta que tiene en cuenta tanto los ataques no detectados como las falsas alarmas. En pruebas en vivo con una extensión de Chrome, el sistema analizó cada URL en unos 200 milisegundos, lo suficientemente rápido como para que los usuarios no percibieran retrasos. Cuando se detectaba una página riesgosa, el complemento mostraba una advertencia clara y permitía al usuario volver atrás o continuar bajo su propia responsabilidad. En comparación con herramientas populares como Google Safe Browsing y extensiones anti‑phishing existentes, el nuevo sistema mostró tasas de detección superiores, menos advertencias erróneas y la capacidad de identificar direcciones engañosas—incluso cuando estaban acortadas, ligeramente ofuscadas o recién creadas.
Qué significa esto para la navegación cotidiana
Para los no especialistas, la conclusión clave es que la defensa contra el phishing ya no tiene que depender únicamente de conjeturas o listas negras manuales. Al combinar cómo está escrita una URL con cómo se ve una página, y al seleccionar automáticamente las señales más informativas, la extensión propuesta puede reconocer muchas estafas desde la primera vez que aparecen, no solo después de que alguien las reporte. Los autores reconocen que los atacantes seguirán evolucionando y que los modelos deben reentrenarse y ampliarse a teléfonos y otros navegadores. Aun así, su trabajo demuestra que un complemento inteligente y respetuoso con la privacidad que se ejecuta en tu propio dispositivo puede actuar como un par de ojos incansable—comprobando silenciosamente cada sitio que visitas e interviniendo cuando algo parece sospechoso, mucho antes de que un clic precipitado se convierta en un error costoso.
Cita: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Palabras clave: detección de phishing, extensión de navegador, aprendizaje automático, ciberseguridad, sitios web falsos