Siempre que gobiernos, científicos o encuestadores intentan aprender algo sobre una población entera—como la renta media, el rendimiento de los cultivos o los niveles de contaminación—rara vez pueden medir a todo el mundo. En su lugar, extraen una muestra y extrapolan. Esto funciona bien solo si los datos se comportan de forma ordenada. En la vida real, sin embargo, las encuestas y las mediciones están plagadas de errores y valores extremos que pueden distorsionar gravemente los resultados. Este artículo presenta una nueva forma de calcular medias poblacionales que se mantiene fiable incluso cuando los datos están desordenados, haciendo que las decisiones basadas en encuestas sean más confiables.
Cuando los promedios simples fallan
Las herramientas estándar para estimar una media poblacional, como la media muestral simple o la regresión ordinaria, suponen que la mayor parte de los puntos de datos sigue patrones suaves, sin valores atípicos extremos ni casos inusuales. En encuestas sociales y económicas, vigilancia ambiental y estadísticas agrícolas, esa esperanza a menudo no se cumple. Algunas lecturas defectuosas, eventos raros pero extremos o respuestas mal declaradas pueden apartar las estimaciones de la verdad, aumentando tanto el sesgo como la incertidumbre. Trabajos anteriores intentaron mitigar el impacto de tales valores atípicos usando métodos llamados robustos, incluida una aproximación popular conocida como estimación M de Huber. Aunque útiles, estos métodos protegen principalmente contra valores extremos en la variable de respuesta y siguen siendo vulnerables a patrones inusuales en la información explicativa asociada.
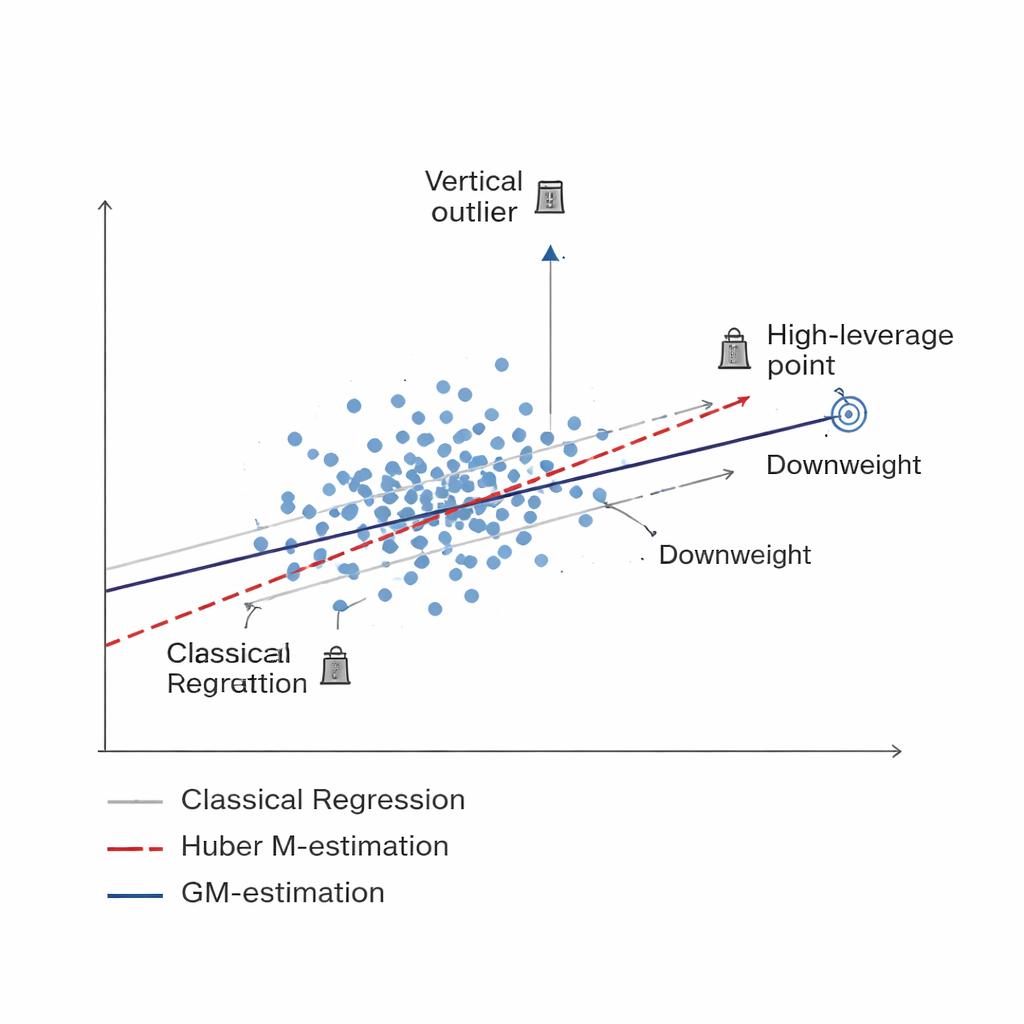
Una forma más inteligente de rebajar el peso de los datos malos Figura 1.
El estudio desarrolla una nueva familia de estimadores basados en la estimación M generalizada, o estimación GM. En lugar de tratar por igual cada unidad muestreada, los métodos GM asignan pesos adaptativos que dependen a la vez de dos factores: cuán extrema es la respuesta de una unidad (un atípico vertical) y cuán inusual es la información asociada (un punto de alto apalancamiento). Tres versiones específicas—denominadas Mallows-GM, Schweppes-GM y SIS-GM—están diseñadas para montajes de encuesta comunes, incluyendo muestreo aleatorio simple sin reemplazo y diseños estratificados más complejos donde la población se divide en grupos relativamente homogéneos. Al controlar conjuntamente ambos tipos de observaciones problemáticas, estos estimadores buscan mantener la estimación final de la media poblacional estable incluso cuando los datos contienen contaminación severa.
Poniendo a prueba los nuevos estimadores
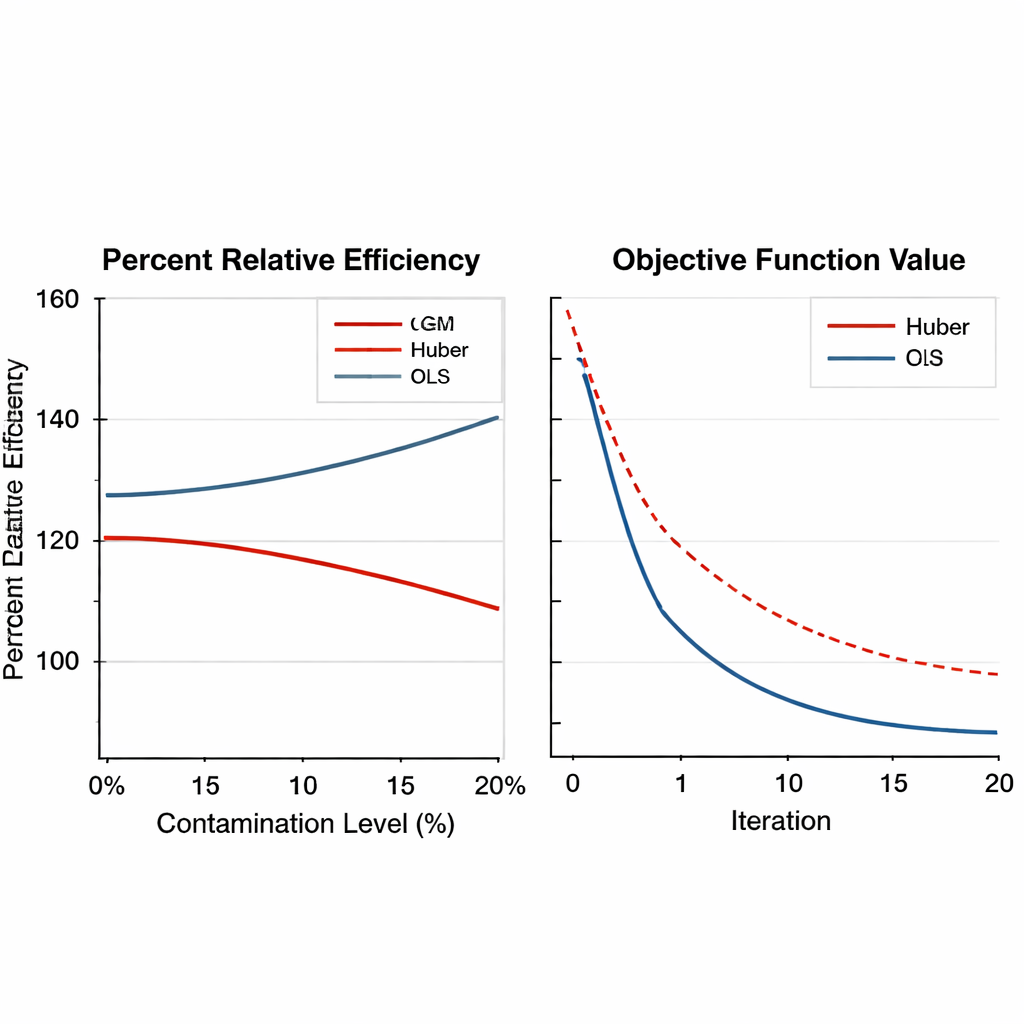
Para evaluar el rendimiento de los estimadores basados en GM, el autor realiza experimentos numéricos extensos. Primero se analizan datos reales de agricultura del tabaco en dos versiones: una limpia y otra deliberadamente contaminada donde se reemplaza una unidad por valores extremos. Los nuevos estimadores se comparan con la regresión tradicional y métodos robustos basados en Huber usando una medida llamada eficiencia relativa porcentual, que refleja cuánto menor es el error de estimación. A lo largo de una amplia gama de tamaños muestrales, los estimadores GM superan de forma consistente a los métodos antiguos, especialmente cuando los datos incluyen valores extremos. En algunos escenarios, el estimador GM de mejor rendimiento reduce el error en más del 50 por ciento en comparación con el enfoque de Huber.
Robustez a través de diseños, escenarios y elecciones de ajuste Figura 2.
El artículo amplía después las pruebas utilizando grandes simulaciones por ordenador. Se generan poblaciones artificiales bajo varias distribuciones—normal, sesgada y de colas pesadas—y se contaminan con fracciones variables de outliers, desde ninguna hasta el 20 por ciento. Se consideran planes de muestreo tanto simples como estratificados, y la fuerza de la relación entre la variable principal y sus auxiliares varía de débil a fuerte. Los estimadores GM no solo mantienen su ventaja bajo una contaminación severa, alcanzando a menudo ganancias de eficiencia superiores al 150 por ciento, sino que también muestran una convergencia numérica suave y fiable. Es importante que su rendimiento cambie poco cuando los parámetros de ajuste internos se modifican dentro de rangos razonables, lo que significa que los practicantes no necesitan afinar finamente esos parámetros para cada nueva encuesta.
Qué implica esto para las encuestas del mundo real
En términos sencillos, el artículo demuestra que los estimadores propuestos basados en GM ofrecen una forma más segura de convertir muestras imperfectas en estimaciones de medias poblacionales. En condiciones ideales y con datos limpios son aproximadamente igual de precisos que los métodos clásicos. Pero cuando los datos incluyen errores de medición, valores mal declarados o eventos extremos raros—como suele ocurrir en encuestas nacionales, vigilancia ambiental y estadísticas financieras—proporcionan respuestas sustancialmente más fiables. Dado que son computacionalmente factibles y funcionan bien en distintos diseños y escenarios, estos estimadores ofrecen a los profesionales de la encuesta una mejora práctica que puede hacer que las decisiones basadas en evidencia sean más resistentes al inevitable desorden de los datos del mundo real.
Cita: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Palabras clave: muestreo por encuesta, estimación robusta, valores atípicos, estimación M generalizada, media de población finita