Clear Sky Science · es
Reconocimiento ciego de códigos de canal basado en redes neuronales convolucionales de fusión de características de doble rama
Radios más inteligentes para un espectro saturado
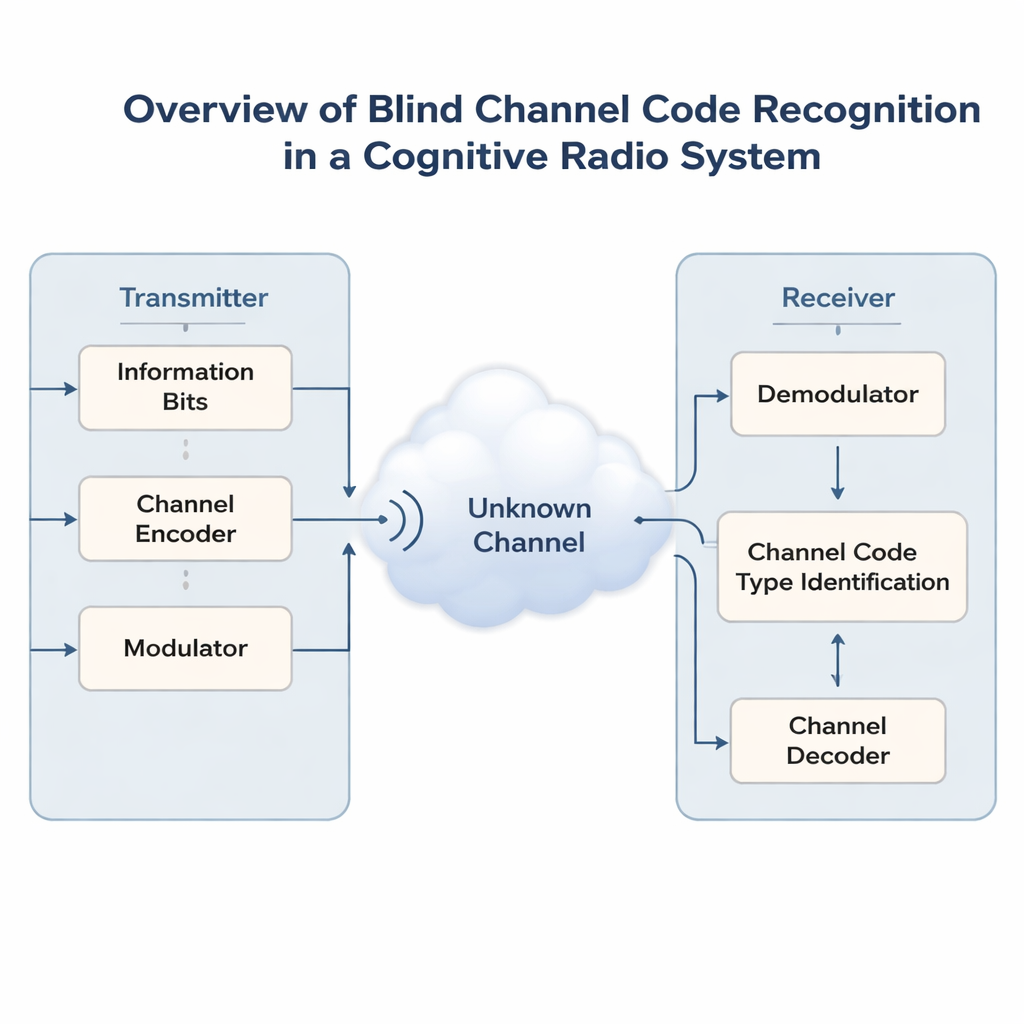
Las redes inalámbricas se están llenando a medida que teléfonos, sensores y vehículos compiten por las mismas ondas. Para evitar el caos, las futuras “radios cognitivas” deberán escuchar primero y luego compartir inteligentemente el espectro que ya pertenece a otros. Un problema clave es que estas radios a menudo no saben cómo se protegió la señal original contra errores antes de enviarla. Este artículo presenta un nuevo método de inteligencia artificial que puede adivinar el código de corrección de errores oculto utilizado en una señal —sin información previa—, facilitando que receptores inteligentes se sincronicen y comuniquen con fiabilidad.
Por qué importan los códigos de corrección de errores ocultos
Los enlaces inalámbricos modernos protegen los datos con códigos de corrección de errores, que añaden redundancia estructurada para que los receptores puedan corregir fallos causados por ruido e interferencias. Diferentes situaciones requieren distintos códigos: códigos Hamming simples, códigos más potentes como BCH y Reed–Solomon, códigos flexibles LDPC y Polar, o códigos tipo transmisión como los convolucionales y Turbo. En entornos no cooperativos —como comunicaciones militares, monitorización del espectro o bandas abiertas y compartidas— los receptores no pueden preguntar a un transmisor qué código está usando. Solo ven una secuencia de bits ruidosa. Adivinar correctamente el esquema de codificación, una tarea llamada reconocimiento ciego de códigos, es esencial antes de cualquier decodificación significativa o procesamiento de alto nivel.
Límites de métodos previos de reconocimiento
Investigaciones anteriores se centraron en una familia de códigos a la vez o dependieron de estadísticas diseñadas a mano, como la frecuencia de repeticiones de bits, el grado de aleatoriedad de una secuencia o trucos algebraicos adaptados a un código específico. Estos enfoques podrían indicar “esto es algún tipo de código por bloques” pero tienen dificultades para distinguir varios formatos populares a la vez. El aprendizaje profundo ha mejorado recientemente la situación al tratar las secuencias de bits algo así como oraciones en un modelo de lenguaje. Sin embargo, la mayoría de las redes neuronales miran solo secuencias crudas o solo características diseñadas manualmente, y típicamente manejan como máximo dos o tres tipos de códigos juntos. Su precisión cae bruscamente cuando la tasa de error de bits aumenta, que es precisamente cuando se necesita un reconocimiento robusto.
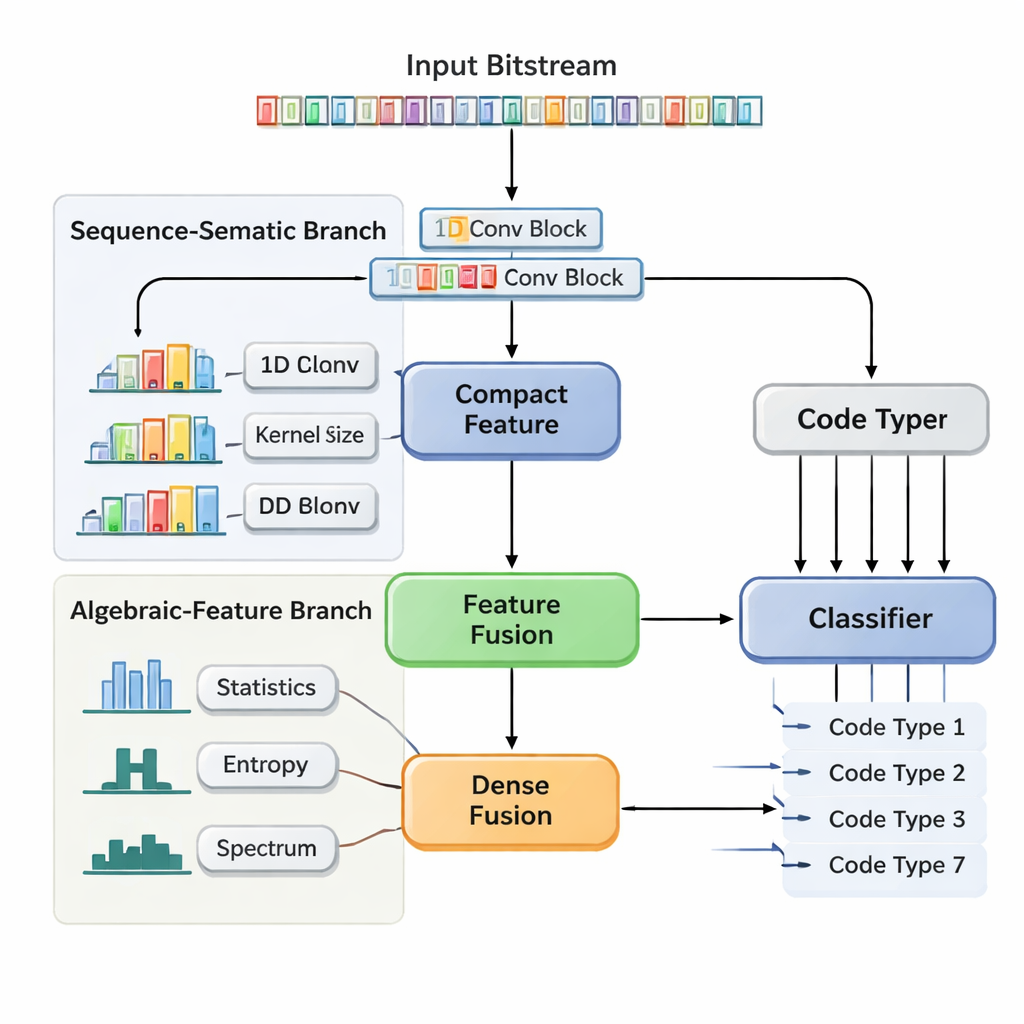
Una red neuronal de dos pistas que observa estructura y estadísticas
Los autores proponen una Red Neuronal Convolucional de Fusión de Características de Doble Rama (DBFCNN) que aborda el reconocimiento ciego de siete códigos ampliamente usados en una sola pasada: Hamming, BCH, Reed–Solomon, LDPC, Polar, convolucional y Turbo. La primera rama trata los bits entrantes como “palabras” cortas, agrupándolos en bloques de 8 bits y mapeando cada bloque a un vector denso, de forma similar a un embedding en procesamiento del lenguaje natural. Luego aplica un conjunto de convoluciones unidimensionales con tamaños de ventana y tasas de dilatación diferentes. Filtros pequeños capturan patrones de corto alcance, como la estructura compacta de códigos por bloques simples, mientras que filtros más grandes y dilatados abarcan rangos más largos, captando trazas de entrelazadores y patrones de paridad típicos de los códigos Turbo y LDPC. Un paso de pooling global comprime esto en un resumen compacto de la “huella” estructural de la secuencia.
Medidas diseñadas a mano que estabilizan el modelo
La segunda rama adopta una visión muy distinta. En lugar de bits crudos, calcula siete familias de estadísticas descriptivas que los ingenieros saben que son sensibles a las elecciones de codificación. Estas incluyen la frecuencia de corridas de bits idénticos, la complejidad de la secuencia, cuán aleatoria parece, la fuerza de su correlación con copias desplazadas de sí misma y cómo se distribuye su energía a través de las frecuencias. Medidas adicionales exploran cuán “lineal” parece el código y cómo se comportan bloques locales de bits. Dado que estas estadísticas cambian lentamente con el ruido agregado, ofrecen a la red una perspectiva estable y tolerante al ruido. Una pequeña subred neuronal transforma este vector de características en otra representación compacta. Finalmente, DBFCNN concatena las dos ramas, normaliza y regulariza las características combinadas y las alimenta a un clasificador que produce probabilidades para cada uno de los siete tipos de código.
Demostrando fiabilidad en condiciones ruidosas
Para evaluar rigurosamente a DBFCNN, los autores generaron más de un millón de ejemplos sintéticos que cubren siete familias de códigos, múltiples configuraciones de parámetros y tasas de error de bits desde casi sin errores hasta condiciones extremadamente ruidosas. Entrenaron y probaron el modelo usando procedimientos Monte Carlo cuidadosos para evitar solapamientos ocultos entre los datos de entrenamiento y de prueba. En este amplio rango, DBFCNN superó de forma consistente a tres líneas base fuertes, incluyendo una CNN dilatada multiescala previa diseñada específicamente para esta tarea. En tasas de error moderadas y bajas (tasa de error de bits por debajo de 10⁻³), la nueva red identificó correctamente el tipo de código en torno al 98% de las veces, mejorando la precisión absoluta en aproximadamente 5–11 puntos porcentuales sobre el modelo previo más potente. Incluso cuando el nivel de ruido se volvió bastante severo, DBFCNN mantuvo una ventaja clara y aún pudo reconocer varios códigos complejos con alta confianza.
Qué significa esto para las radios inteligentes del futuro
Para un público no experto, la conclusión clave es que este trabajo demuestra cómo combinar el conocimiento del dominio con aprendizaje profundo puede hacer que las radios sean mucho más autosuficientes. DBFCNN aprende el sutil “acento” de diferentes códigos de corrección de errores en secuencias de bits ruidosas escuchando de dos maneras a la vez: una rama percibe patrones locales detallados y la otra mide pistas estadísticas globales. Al fusionar estas perspectivas, el sistema suele identificar exactamente qué esquema de codificación se está usando, sin ninguna cooperación del emisor. Esa capacidad es un bloque de construcción para radios cognitivas que pueden unirse a redes desconocidas, adaptarse a entornos cambiantes y aprovechar mejor un espectro escaso, todo ello manteniendo comunicaciones fiables incluso cuando las ondas están saturadas y ruidosas.
Cita: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Palabras clave: radio cognitiva, codificación de canal, aprendizaje profundo, corrección de errores, clasificación de señales