Clear Sky Science · es
Generación precisa de resúmenes de alta mediante modelos de lenguaje grande afinados con autoevaluación
Por qué la papeleo en el hospital importa de verdad
Cuando un paciente sale del hospital, la historia de su enfermedad no termina en la puerta. Los médicos de otras consultas, los médicos de cabecera y los propios pacientes dependen de un documento clave llamado resumen de alta para entender qué ocurrió en el hospital y qué hacer después. Sin embargo, redactar estos resúmenes es un trabajo lento y repetitivo que puede llevar a los clínicos ocupados media hora o más por paciente. Este estudio explora cómo las modernas herramientas de lenguaje por IA pueden ayudar a redactar resúmenes de alta más rápido y con mayor precisión, manteniendo a la vez la privacidad de los datos del paciente y el control dentro del hospital.
Convertir registros dispersos en una historia clara
La información hospitalaria está distribuida en muchos sistemas electrónicos: resultados de laboratorio en una tabla, notas de cirugía en otra, observaciones de enfermería en una tercera, y así sucesivamente. La estancia de cada paciente genera miles de fragmentos de texto. Los investigadores primero construyeron una canalización para convertir esta información dispersa y desordenada en entradas limpias que un modelo de IA pueda entender. Usando métodos para fusionar y eliminar duplicados de registros solapados, filtrar detalles privados como nombres y identificadores, corregir ortografía y estandarizar términos médicos, crearon entradas estructuradas para cada estancia hospitalaria. Este proceso se aplicó a datos de más de 6 000 pacientes sometidos a cirugía tiroidea en un gran hospital chino, produciendo ejemplos emparejados de resúmenes de alta reales y los datos en bruto a partir de los cuales fueron redactados. 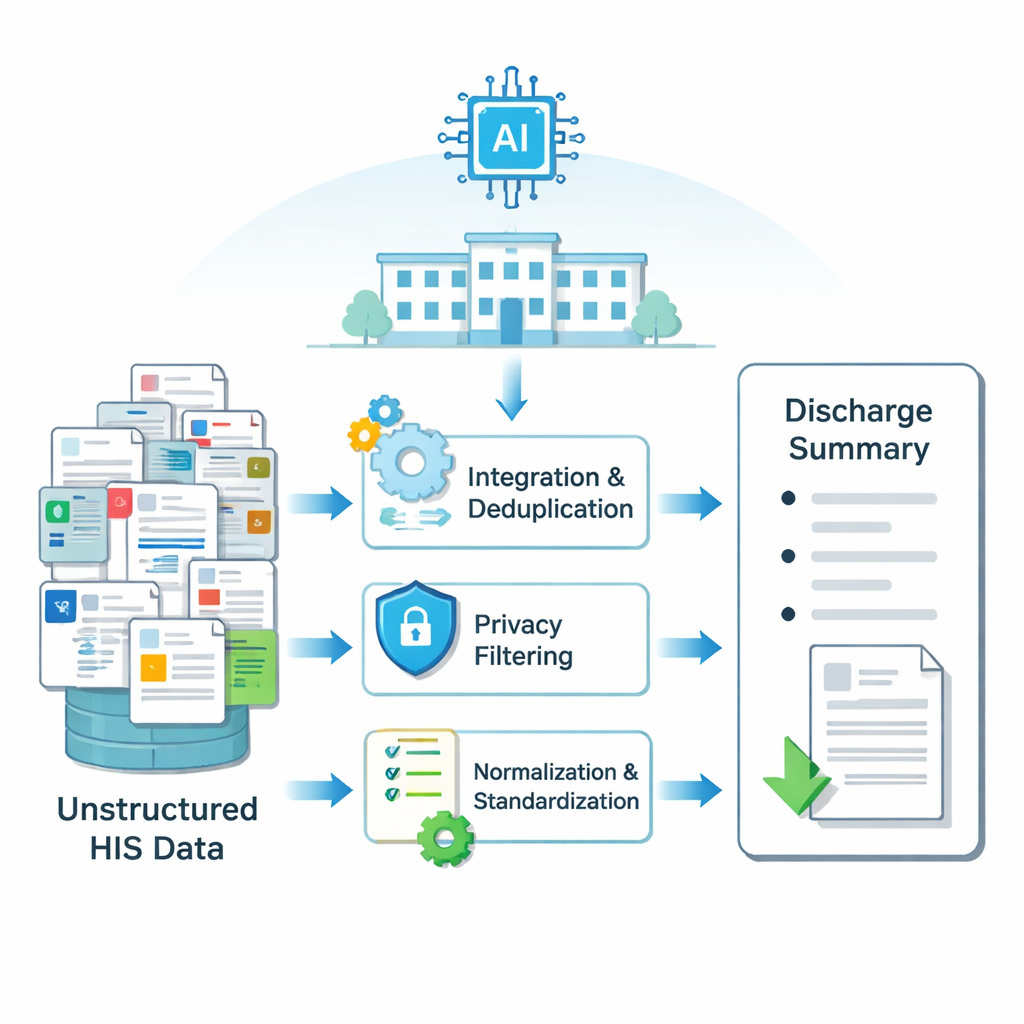
Afinar la IA para que hable el lenguaje de la medicina
Los modelos de lenguaje grande disponibles se entrenan con texto general de internet y libros, por lo que a menudo tienen dificultades con el lenguaje médico especializado y los estilos locales de documentación. El equipo comparó varias formas de “afinar” modelos existentes para que comprendan mejor los registros médicos en chino. Un método nuevo llamado adaptación de bajo rango con descomposición de pesos, o DoRA, ajusta los pesos internos del modelo de forma más dirigida que técnicas anteriores como LoRA y QLoRA. En distintos modelos, incluidos Qwen2, Mistral y Llama 3, DoRA produjo de manera consistente resúmenes más fluidos, más cercanos en significado a los escritos por humanos y con menos confusiones (según una métrica estándar llamada perplexity). En esencia, DoRA ayudó a la IA a aprender giros y terminología médica sin necesitar un reentrenamiento completo en hardware masivo.
Enseñar a la IA a revisar su propio trabajo
Incluso un modelo bien entrenado puede olvidar detalles importantes o introducir errores menores cuando redacta un resumen largo de una sola pasada. Inspirados en ideas psicológicas de pensamiento rápido “Sistema 1” frente a razonamiento más lento y cuidadoso “Sistema 2”, los autores diseñaron un bucle de autoevaluación. Primero, el modelo redacta un resumen de alta inicial a partir de los datos hospitalarios procesados. Luego, los datos originales se dividen en segmentos—como hallazgos patológicos, órdenes médicas o paneles de laboratorio—y cada segmento se vuelve a emparejar con el borrador. Se le pregunta al modelo, en efecto, “¿Se refleja todo lo de este segmento en el resumen?” Si no, revisa el texto para añadir información faltante o corregir inconsistencias. Este ciclo se repite hasta tres veces o hasta que el modelo juzga el resumen completo, produciendo una versión refinada que coincide con mayor fidelidad con el registro del paciente. 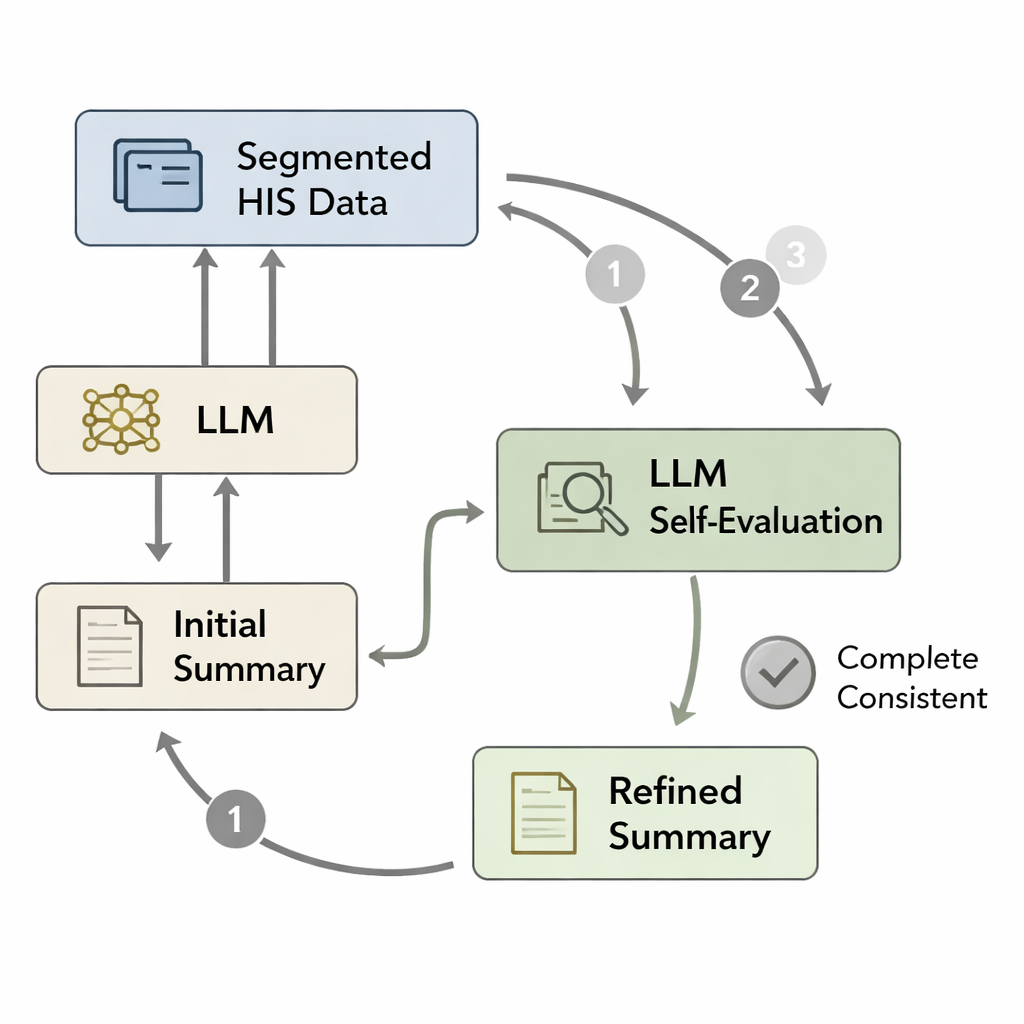
¿Qué tan bien lo hizo la IA en comparación con las personas?
Para evaluar la calidad, el equipo utilizó tanto puntuaciones automáticas como revisores humanos. Médicos e investigadores valoraron los resúmenes en precisión, exhaustividad, claridad, consistencia y utilidad para la continuidad del cuidado. El mejor sistema—la combinación del afinado DoRA con el bucle de autoevaluación—se acercó más a los resúmenes escritos por humanos en todas las medidas. Mejoró especialmente la exhaustividad, es decir, hubo menos diagnósticos, tratamientos o valores de laboratorio clave omitidos. En un ejemplo detallado, la IA inicialmente olvidó mencionar un pequeño cáncer tiroideo y una pastilla hormonal específica; tras dos pasadas de autoevaluación, ambos detalles se añadieron correctamente. De media, el sistema generó un resumen de alta en unos 80 segundos en un servidor hospitalario, frente a los 30–50 minutos que tarda un clínico en redactarlo desde cero, aunque la revisión humana sigue siendo esencial antes de que el texto pase al registro oficial.
Qué podría significar esto para pacientes y clínicos
El estudio muestra que, con un entrenamiento cuidadoso y comprobaciones internas, los sistemas de IA pueden producir resúmenes de alta lo suficientemente precisos como para considerarse aceptables clínicamente tras una rápida revisión humana. Esto no reemplaza a los médicos, pero puede desplazar su tiempo desde la mecanografía rutinaria hacia la revisión y la toma de decisiones de mayor nivel. Al mantener todo el cálculo dentro de la red hospitalaria y eliminar datos identificativos, el enfoque también respeta la privacidad del paciente. Aunque los resultados hasta ahora provienen de un solo servicio en un hospital, el marco apunta hacia un futuro en el que la IA ayude a convertir datos médicos complejos en narrativas claras y fiables en muchas especialidades, favoreciendo traslados de cuidado más seguros y una mejor comprensión para pacientes y familias.
Cita: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Palabras clave: resúmenes de alta, IA médica, modelos de lenguaje grande, documentación clínica, autoevaluación