Clear Sky Science · es
Geolocalización de usuarios sociales basada en K-medoides y una red de atención de grafos con núcleo gaussiano
Por qué tus tuits pueden revelar dónde vives
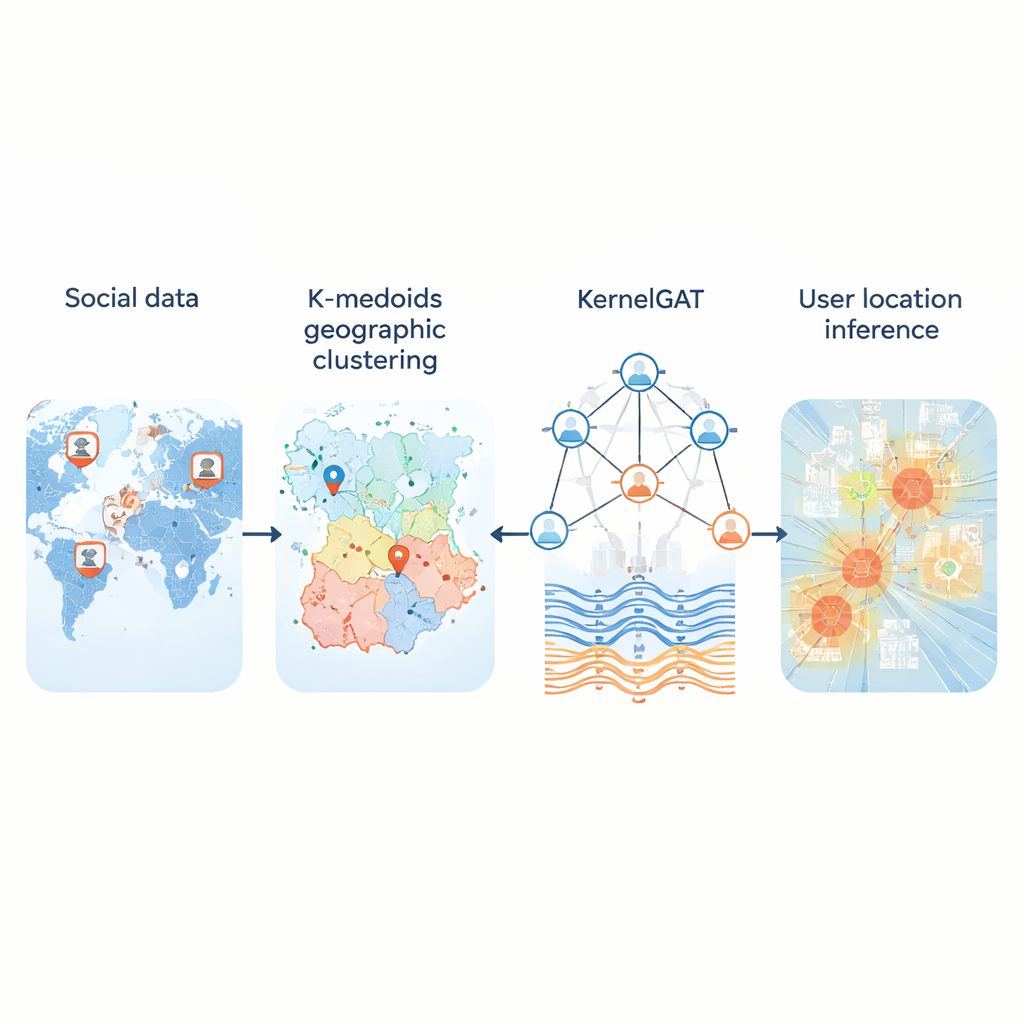
Cada día, millones de personas publican en redes sociales sin compartir sus coordenadas GPS. Aun así, esas publicaciones dejan pistas sobre dónde viven, trabajan y viajan los usuarios. Poder inferir la ubicación a partir de ese rastro público importa para todo, desde la respuesta a emergencias y el seguimiento de enfermedades hasta recomendaciones locales y servicios dirigidos. Este artículo presenta un nuevo método, denominado KMKGAT, que usa tanto lo que la gente dice como cómo está conectada en línea para estimar dónde se encuentran, con mayor precisión que enfoques anteriores.
Del ruido en línea a lugares del mundo real
Cuando los usuarios escriben tuits o microblogs, pueden mencionar nombres de lugares, usar formas de hablar locales o interactuar con amigos cercanos. Empresas como Twitter (ahora X) conocen la dirección de internet del usuario, pero los investigadores y proveedores de servicios externos normalmente no. En su lugar deben trabajar con información pública: el propio texto, los perfiles de usuario y quién habla con quién. Los métodos previos cayeron en tres categorías. Los métodos solo de contenido extraían palabras y hashtags para adivinar ubicaciones. Los métodos solo de red se apoyaban en que la gente tiende a interactuar con usuarios cercanos. Una tercera familia, más potente, combinó ambas perspectivas, pero aún tenía puntos ciegos—especialmente para personas en zonas poco pobladas y para usuarios cuyas conexiones en línea abarcan grandes distancias.
Agrupación geográfica más inteligente con centros reales de usuarios
Un problema clave es cómo convertir el globo continuo en un conjunto de regiones que un ordenador pueda aprender a predecir. Muchos sistemas dividen el mapa en una cuadrícula fija. Eso funciona razonablemente bien en ciudades pero falla en zonas rurales, donde celdas enormes abarcan cientos de kilómetros. El nuevo método sustituye las cuadrículas rígidas por agrupamiento k-medoides, una forma de agrupar usuarios de modo que cada región esté centrada en un usuario real en lugar de en un punto artificial. Esto hace que las regiones sean compactas y menos sensibles a valores atípicos, especialmente donde los usuarios son escasos. En pruebas con tres grandes conjuntos de datos de Twitter que cubren Estados Unidos y el mundo, esta partición adaptativa redujo los errores típicos en comparación con esquemas basados en cuadrículas y proporcionó “regiones de origen” más realistas para los usuarios.
Permitir que la red se enfoque en usuarios cercanos y similares
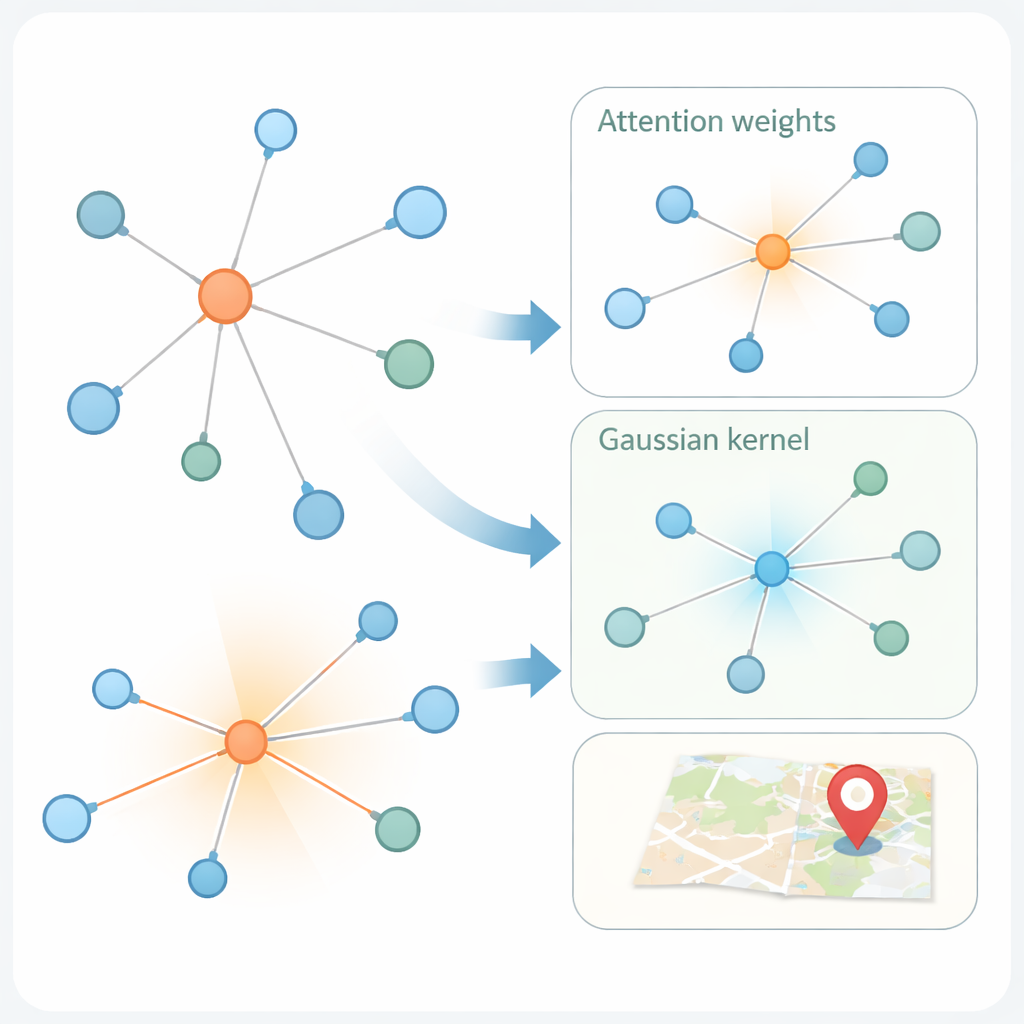
La segunda innovación está en cómo el modelo aprende a partir del grafo social. Las modernas “redes de atención de grafos” ya ponderan de forma distinta a los vecinos de un usuario, según cuán similares sean sus representaciones de características. Pero la similitud por sí sola puede ser engañosa: una cuenta en Nueva York y otra en Londres pueden usar un lenguaje parecido y aun así estar muy separadas geográficamente. KMKGAT amplía la atención con un núcleo gaussiano, un filtro matemático que favorece a vecinos cuyas características aprendidas están cerca del usuario objetivo y atenúa la influencia de los más distantes. Varios núcleos así, combinados como una mezcla de lentes, permiten al modelo capturar la localidad en diferentes escalas. Esto respeta el principio simple pero poderoso de que las interacciones en línea suelen ser más fuertes entre personas que están físicamente más cerca.
Características de texto ligeras que aún aportan pistas de ubicación
En lugar de apoyarse en pesados modelos profundos de lenguaje, que pueden tener dificultades con el estilo ruidoso y lleno de jerga de los tuits, los autores usan una técnica clásica llamada TF–IDF para convertir la colección de publicaciones de cada usuario en una bolsa de palabras ponderadas. Palabras comunes como “the” o “lol” reciben poco peso, mientras que términos raros y específicos de una región ascienden en importancia. Estas características de texto se adjuntan luego a cada usuario en el grafo social y se procesan mediante la red de atención mejorada. Curiosamente, los mejores resultados se obtuvieron cuando la mayoría de las características de texto se descartaron aleatoriamente durante el entrenamiento, lo que sugiere que solo una pequeña fracción de las palabras realmente ayuda con la localización y el resto añade principalmente ruido.
Superando el estado del arte a gran escala
Para evaluar el rendimiento, los investigadores midieron la distancia, en kilómetros, entre el centro de región predicho y las coordenadas conocidas de cada usuario, y qué porcentaje de usuarios se situó dentro de 161 km (100 millas) de su ubicación real. En los tres conjuntos de referencia de Twitter, KMKGAT igualó o superó de forma consistente a sistemas fuertes existentes, mejorando la precisión dentro de los 161 kilómetros hasta en unos pocos puntos porcentuales—una ganancia significativa en este nivel de madurez. Los beneficios fueron más claros en redes pequeñas y medianas, mientras que en un grafo global masivo el método se vio limitado por tener que muestrear solo vecinos inmediatos durante el entrenamiento.
Qué significa esto en términos cotidianos
Para no especialistas, la conclusión es que cada vez es más factible estimar dónde están los usuarios de redes sociales, incluso si nunca comparten una etiqueta de ubicación. Al agrupar a los usuarios en regiones realistas basadas en cuentas reales y al enseñar al modelo a confiar principalmente en vecinos cercanos y similares en la red social, KMKGAT acota dónde es probable que alguien viva o publique. Esto puede ayudar a los equipos de respuesta a localizar personas durante desastres, mejorar la búsqueda y las recomendaciones locales, y apoyar estudios sobre cómo se difunde la información entre lugares. Al mismo tiempo, pone de manifiesto cuánto pueden revelar nuestras interacciones ordinarias en línea sobre nuestra vida fuera de línea, subrayando la importancia de un uso responsable de los datos y de las protecciones de la privacidad.
Cita: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Palabras clave: geolocalización en redes sociales, ubicación de usuarios de Twitter, redes neuronales de grafos, servicios basados en la ubicación, privacidad en línea