Clear Sky Science · es
Identificación automatizada de entidades biomédicas contextualmente relevantes con LLMs fundamentados
Por qué importa etiquetar mejor los artículos médicos
Cada año aparecen miles de estudios biomédicos, cada uno repleto de detalles sobre genes, tipos celulares, enfermedades y tratamientos. Sin embargo, la mayor parte de esa información queda encerrada en largos PDFs, lo que dificulta que otros científicos encuentren los datos exactos que necesitan. Este artículo explora cómo la inteligencia artificial moderna —modelos de lenguaje a gran escala, o LLMs— puede extraer automáticamente estos términos biomédicos clave de los artículos de investigación, ayudando a convertir publicaciones dispersas en recursos bien organizados y buscables.
De artículos desordenados a bloques de construcción buscables
Los centros de investigación biomédica, como los Centros Colaborativos de Investigación de Alemania, dependen de datos claros y estructurados para que los estudios sean reutilizables durante años. Tradicionalmente, los investigadores tenían que etiquetar manualmente sus conjuntos de datos con entidades importantes como organismos, líneas celulares y genes, una tarea tediosa y larga. Los LLMs pueden leer artículos completos y comprender el contexto, lo que los convierte en herramientas prometedoras para automatizar este etiquetado. Pero hay una condición: decidir qué términos son realmente relevantes depende de la pregunta científica y del modo en que se reutilizarán los datos. Los autores trabajan con un esquema de metadatos cuidadosamente diseñado por el CRC centrado en nefrología “NephGen”, que indica a la IA qué tipos de entidades debe buscar y cómo deben organizarse.
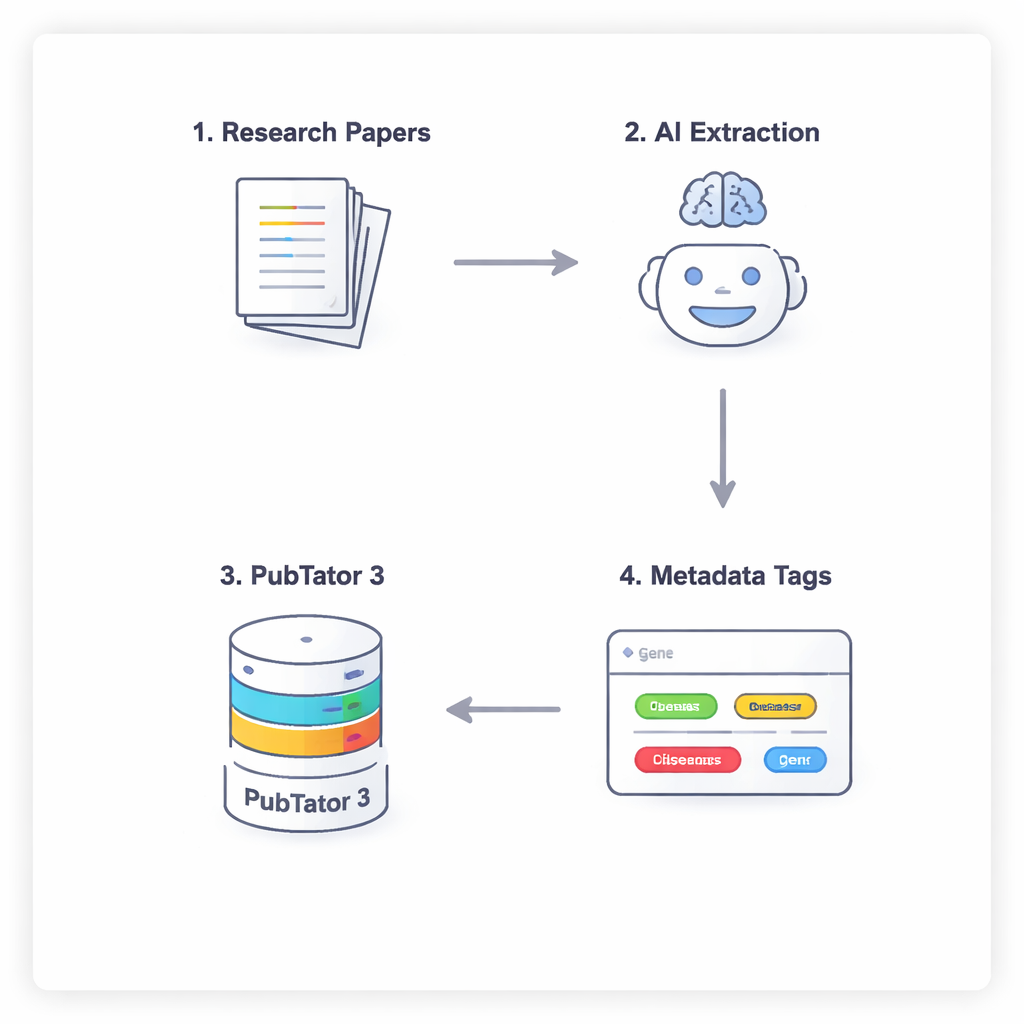
Una conversación en cuatro pasos entre la IA y una base de datos biológica
Para evitar que la IA simplemente adivine o "alucine" hechos biomédicos, los investigadores usan un proceso de cuatro pasos que obliga a los modelos a razonar con cuidado y verificarse. Primero, el modelo escanea el texto completo de un artículo (ignorando la discusión y las referencias) para sugerir entidades potencialmente relevantes. Segundo, debe consultar una herramienta externa, PubTator 3, una gran base de datos biomédica, para confirmar que cada término sugerido existe realmente y tiene un identificador reconocido. Tercero, la IA asigna cada entidad confirmada a un campo del esquema de metadatos de NephGen, que agrupa las entidades en una estructura jerárquica diseñada por humanos. Finalmente, el modelo consolida todo esto en una salida JSON estructurada, esencialmente un resumen ordenado y legible por máquina de las entidades biomédicas clave del artículo.
Probando ocho modelos de IA con investigación renal real
El equipo implementó este flujo de trabajo usando APIs de 14 LLMs diferentes y descubrió que solo ocho podían cumplir de forma fiable los requisitos estrictos, como devolver JSON válido y usar correctamente herramientas externas. Luego aplicaron estos ocho modelos a seis artículos de investigación en nefrología y pidieron a cada autor del artículo que revisara la lista final de entidades de la IA en una breve entrevista presencial. Dado que no existe un número "correcto" fijo de entidades a extraer, los autores se centraron en la precisión: qué fracción de las entidades sugeridas los científicos juzgaron correctas. Utilizando métodos de metaanálisis estadístico adaptados a proporciones próximas al 100%, estimaron la precisión de cada modelo teniendo en cuenta la variación entre artículos.
Alta exactitud, pero compensaciones en esfuerzo, coste y velocidad
En conjunto, los sistemas de IA alcanzaron una precisión global de alrededor del 91%, lo que significa que la gran mayoría de las entidades sugeridas fueron consideradas correctas. GPT-4.1, GPT-4o Mini y Gemini 2.0 Flash obtuvieron las precisiones más altas —aproximadamente entre el 94% y el 98%—, aunque sus diferencias no fueron estadísticamente concluyentes. Los modelos Gemini tendieron a proponer más entidades en total, lo que condujo a más etiquetas correctas pero también a más elementos que los humanos tuvieron que revisar. Algunos modelos más pequeños o económicos, como GPT-4.1 Nano, fueron más rápidos y baratos pero significativamente menos precisos. Los autores visualizaron estas tensiones usando fronteras de Pareto, identificando combinaciones de modelos que equilibraban precisión, número de entidades correctas, coste y tiempo de procesamiento: por ejemplo, GPT-4o Mini resultó especialmente atractivo cuando se priorizan tanto la exactitud como el bajo coste.
Por qué los humanos siguen siendo necesarios
A pesar del sólido rendimiento, el estudio subraya limitaciones importantes. Los modelos a veces confundieron información sobre el artículo publicado con detalles que no eran realmente relevantes para el conjunto de datos subyacente que usuarios futuros podrían querer reutilizar. Esta confusión refleja un reto más amplio en la minería de texto automatizada: los artículos científicos discuten mucho más de lo que termina en un conjunto de datos compartido. Por ello, los autores recomiendan que expertos humanos continúen revisando las anotaciones generadas por la IA antes de su publicación. También señalan que su evaluación cubre solo seis artículos de nefrología, por lo que se necesita una prueba más amplia en otros campos. Con el tiempo, un flujo de trabajo rutinario con humanos en el circuito podría construir un conjunto de referencia consensuado, haciendo posible medir no solo la precisión sino también cuántas entidades pasó por alto la IA.
Qué significa esto para el futuro del intercambio de datos biomédicos
El estudio muestra que, cuando se guían cuidadosamente y se fundamentan en bases de datos fiables, los LLMs modernos pueden ayudar de forma fiable a anotar artículos biomédicos, reduciendo considerablemente la carga manual de los investigadores. Los mejores modelos se acercan a la precisión de expertos al tiempo que ofrecen diferentes compromisos entre exhaustividad, coste y velocidad. Por ahora, la revisión humana sigue siendo esencial para garantizar que las anotaciones coincidan realmente con los conjuntos de datos y el contexto de la investigación. Pero a medida que las herramientas y los modelos de código abierto maduren, flujos de trabajo como este podrían convertirse en una columna vertebral estándar para convertir el aluvión actual de artículos médicos en los datos organizados y reutilizables del mañana.
Cita: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Palabras clave: minería de texto biomédico, modelos de lenguaje a gran escala, anotación de metadatos, IA fundamentada, investigación en nefrología