Clear Sky Science · es
Combinando fragmentación de parámetros y mezcla por grupos para defenderse del servidor no fiable en el aprendizaje federado
Por qué importa proteger los modelos compartidos
Nuestros teléfonos, hospitales y bancos están cada vez más impulsados por la inteligencia artificial. Con frecuencia, muchas organizaciones querrían entrenar juntas un modelo compartido, pero la ley y el sentido común indican que no deben agrupar sus datos en bruto en un mismo lugar. El aprendizaje federado se inventó para resolver esta tensión: cada participante entrena en su propio dispositivo y solo comparte actualizaciones del modelo. Pero este artículo muestra que incluso esas actualizaciones pueden filtrar información privada si el servidor central es curioso o deshonesto, y a continuación presenta una nueva forma de mantener tanto nuestros datos como nuestras identidades más seguros.
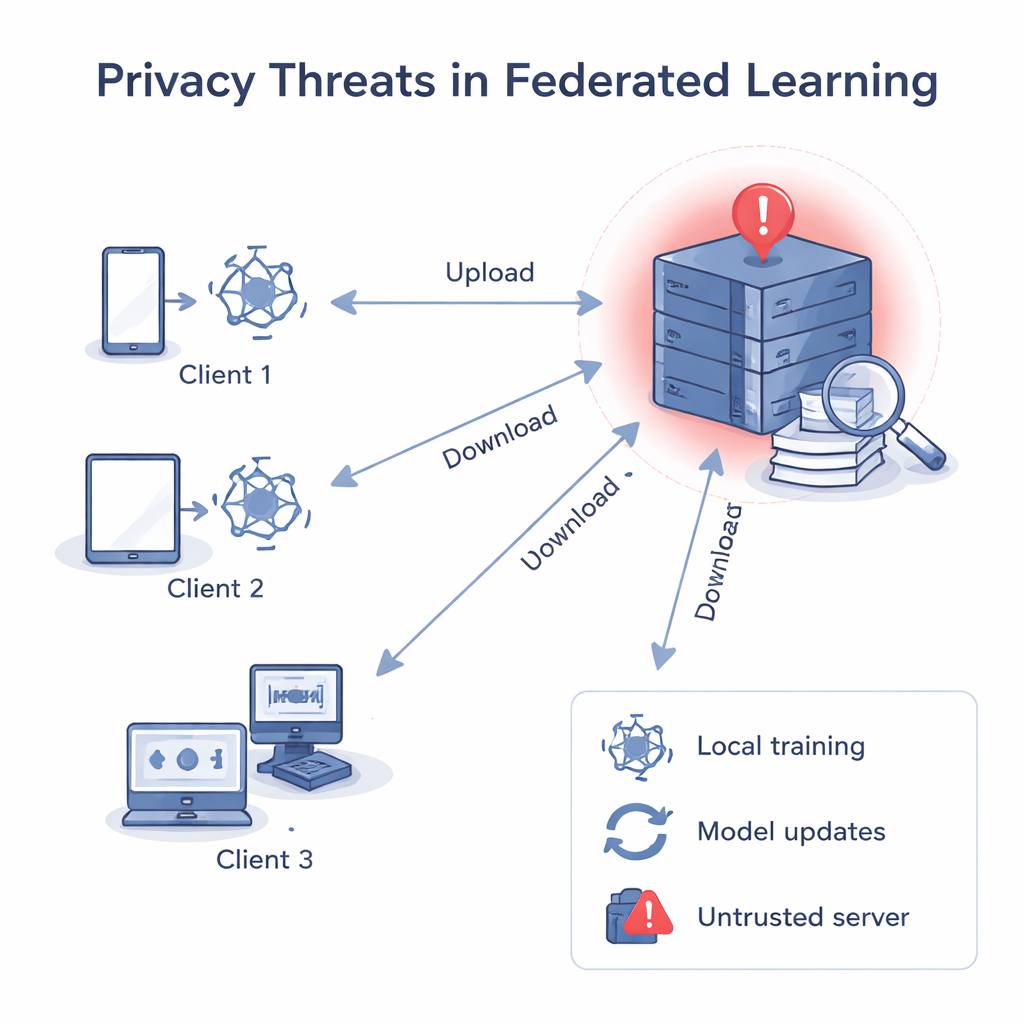
Cuando el servidor no debe ser confiable
En el aprendizaje federado clásico, un servidor central envía un modelo común, cada cliente lo mejora usando sus propios datos y luego envía el modelo actualizado de vuelta. El servidor promedia estas actualizaciones para obtener un modelo global mejor. Aunque los datos en bruto nunca abandonan los dispositivos, investigaciones previas han mostrado que los gradientes y pesos —los números dentro del modelo— se pueden “hacer retroceder” para reconstruir datos privados, como imágenes o texto, o para adivinar si un registro específico se usó en el entrenamiento. Si el servidor central no es de fiar, puede analizar por separado la actualización de cada cliente, aprender sobre los datos locales de ese cliente e incluso vincular una actualización a una persona u organización concreta.
Dividir las actualizaciones en piezas inocuas
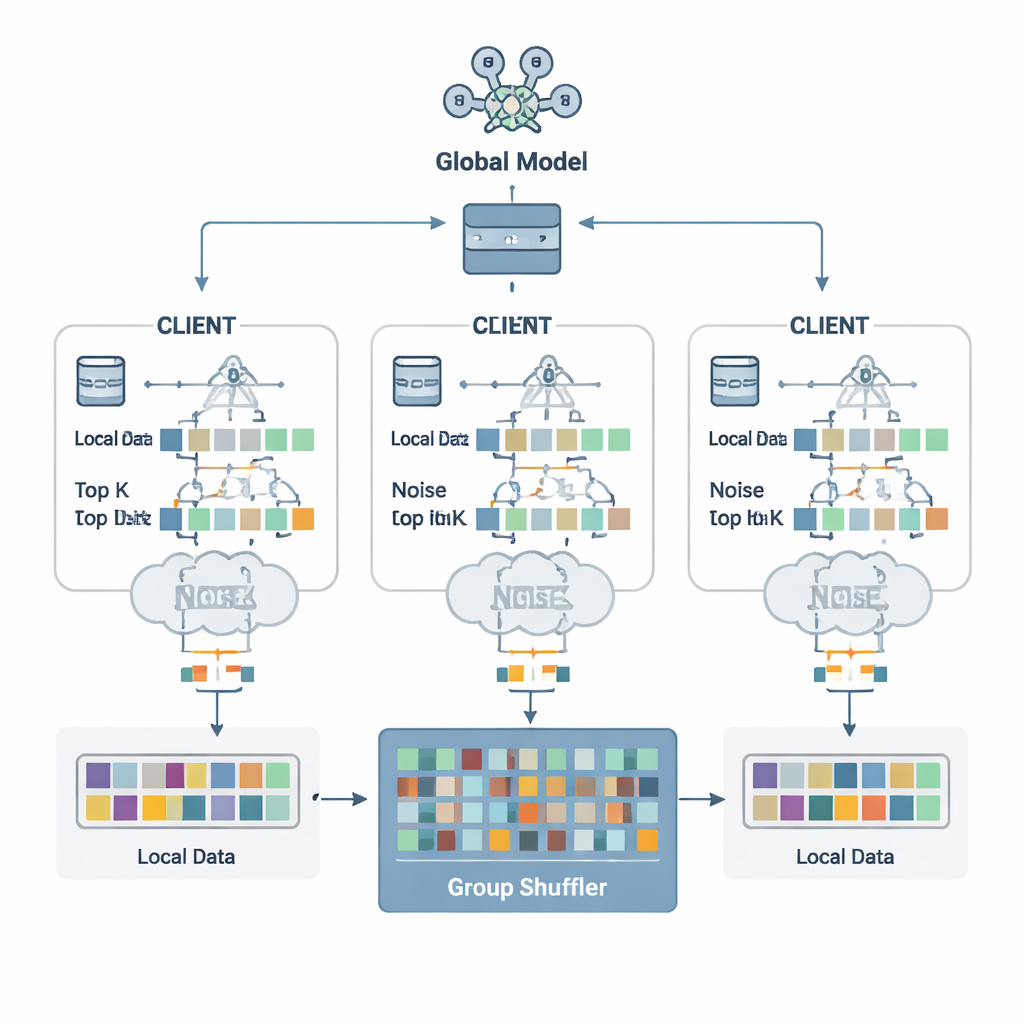
Los autores proponen un esquema de defensa llamado Defensa de Seguridad basada en Fragmentación de Parámetros y Mezcla por Grupos (SDPFGS). Su primera idea es simple pero potente: nunca enviar una actualización completa. En su lugar, cada cliente divide su actualización del modelo en varios “fragmentos” artificiales. La mayoría de estos se llenan con números aleatorios, y solo el último se ajusta para que todos los fragmentos sumen la actualización verdadera. Cualquier fragmento individual, o incluso varios de ellos, parecen ruido y revelan casi nada sobre los datos originales. Este truco matemático es similar al reparto secreto: solo combinando todas las piezas se puede recuperar el todo.
Añadir ruido y agitar la mezcla
Enviar muchos fragmentos aún podría ser costoso y, si se examinan juntos, podría permitir a un atacante inferir más. Para evitarlo, cada cliente selecciona solo los valores de fragmento más importantes: las entradas Top-K que más importan para el aprendizaje, y les añade ruido aleatorio cuidadosamente calibrado siguiendo los principios de la privacidad diferencial. Este ruido dificulta estadísticamente determinar si los datos de una persona influyeron en un valor concreto. Luego llega el segundo ingrediente clave: la mezcla por grupos. En lugar de enviar los fragmentos directamente al servidor, los clientes los remiten a un “mezclador” de confianza que mezcla fragmentos de muchos clientes en grupos antes de reenviarlos. Tras esta mezcla, el servidor ya no puede saber qué fragmento proviene de qué cliente, rompiendo el vínculo entre actualizaciones e identidades.
Mantener la precisión mientras se reducen las filtraciones
El equipo probó SDPFGS en puntos de referencia estándar de imagen y texto, incluidos dígitos manuscritos (MNIST), fotos de ropa (Fashion-MNIST) e imágenes a color (CIFAR-10 y CIFAR-100), así como en una tarea de clasificación de noticias. Compararon su método con varias técnicas de privacidad de última generación que usan solo ruido, solo mezcla o compresión simple de gradientes. En estos experimentos, SDPFGS igualó o superó de forma consistente la precisión de los métodos competidores mientras usaba menos comunicación y tiempo de entrenamiento que muchos de ellos. De manera notable, frente a ataques de inversión de modelo —donde un adversario intenta reconstruir ejemplos de entrenamiento— SDPFGS tuvo la tasa de éxito de ataque más baja, lo que significa que filtró menos sobre los datos subyacentes.
Qué significa esto para los usuarios cotidianos
Para una persona no experta, la conclusión es que “ocultar los datos” no es suficiente; también debemos ocultar lo que nuestros dispositivos envían durante el entrenamiento. SDPFGS logra esto convirtiendo cada actualización de modelo en fragmentos ruidosos y mezclados que son inútiles por sí solos pero que aún se combinan en un modelo global de alta calidad. El resultado es un escudo más fuerte contra un servidor curioso o comprometido, con solo un coste menor en precisión y eficiencia. A medida que el aprendizaje federado se extienda a la sanidad, las finanzas y los dispositivos inteligentes, técnicas como SDPFGS podrían ayudar a garantizar que las personas se beneficien de modelos compartidos potentes sin ceder las llaves de su vida privada.
Cita: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Palabras clave: aprendizaje federado, privacidad de datos, privacidad diferencial, ataques de inversión de modelos, agregación segura