Clear Sky Science · es
Desacuerdo entre la evaluación humana y la de la IA de planes de tratamiento
Por qué esto importa para la atención médica cotidiana
A medida que las herramientas de inteligencia artificial (IA) empiezan a ayudar a los médicos a elegir tratamientos, surge una pregunta clave: ¿en quién confiamos más—en los humanos o en las máquinas? Este estudio analiza una posibilidad sencilla pero inquietante: los médicos y los sistemas de IA pueden discrepar no solo sobre qué tratamiento es el mejor, sino también sobre qué cuenta, en primer lugar, como un “buen” plan de tratamiento. Comprender esta brecha es esencial si queremos que la IA apoye, en lugar de distorsionar en silencio, las decisiones médicas en el mundo real.
Una prueba cara a cara del asesoramiento terapéutico
Los investigadores se centraron en dermatología, un campo en el que los médicos gestionan afecciones cutáneas crónicas que rara vez tienen una única “respuesta correcta”. Diez dermatólogos con experiencia y dos modelos de lenguaje grande (LLM)—un modelo de uso general y un modelo orientado al razonamiento—fueron invitados a redactar planes de tratamiento para cinco casos desafiantes ficticios, como eccema grave, psoriasis con comorbilidades y acné relacionado con el embarazo. Para mantener la equidad, los 60 planes se editaron a un formato común: longitud, estructura y tono similares. Se eliminaron cualquier indicio obvio de si el plan había sido escrito por un humano o por una IA, de modo que los jueces posteriores valorarían el contenido y no el estilo.
Cómo evaluaron los humanos y la IA
Los planes pasaron luego por dos rondas de puntuación a ciegas usando la misma rúbrica. Primero, el mismo grupo de diez dermatólogos valoró cada plan en calidad global de 0 a 10, teniendo en cuenta cuán efectivo, seguro, práctico y centrado en el paciente era. En segundo lugar, un modelo de IA distinto—empleado solo como juez, no como redactor—puntuó esos mismos planes con las mismas instrucciones. Crucialmente, ni los evaluadores humanos ni el juez de IA sabían quién había escrito cada plan. Esta configuración permitió a los autores aislar un factor clave: si el evaluador era humano o IA.
Los humanos prefieren a los humanos, la IA prefiere a la IA
Los resultados mostraron un claro “efecto del evaluador”. Cuando los humanos puntuaron los planes, otorgaron notas más altas a los elaborados por sus colegas dermatólogos que a los escritos por cualquiera de los sistemas de IA. Los planes generados por humanos tuvieron una media ligeramente superior y ocuparon las cinco primeras posiciones en el ranking. Uno de los modelos de IA, el sistema avanzado de razonamiento, quedó cerca de la parte baja. Pero cuando el juez de IA asumió la tarea, la imagen se invirtió. Las dos propuestas generadas por IA subieron a la cima del ranking y todos los planes de los dermatólogos humanos quedaron por debajo. En promedio, el juez de IA puntuó más alto los planes generados por IA que los generados por humanos, aun cuando estaba leyendo exactamente el mismo texto estandarizado que habían visto los dermatólogos.
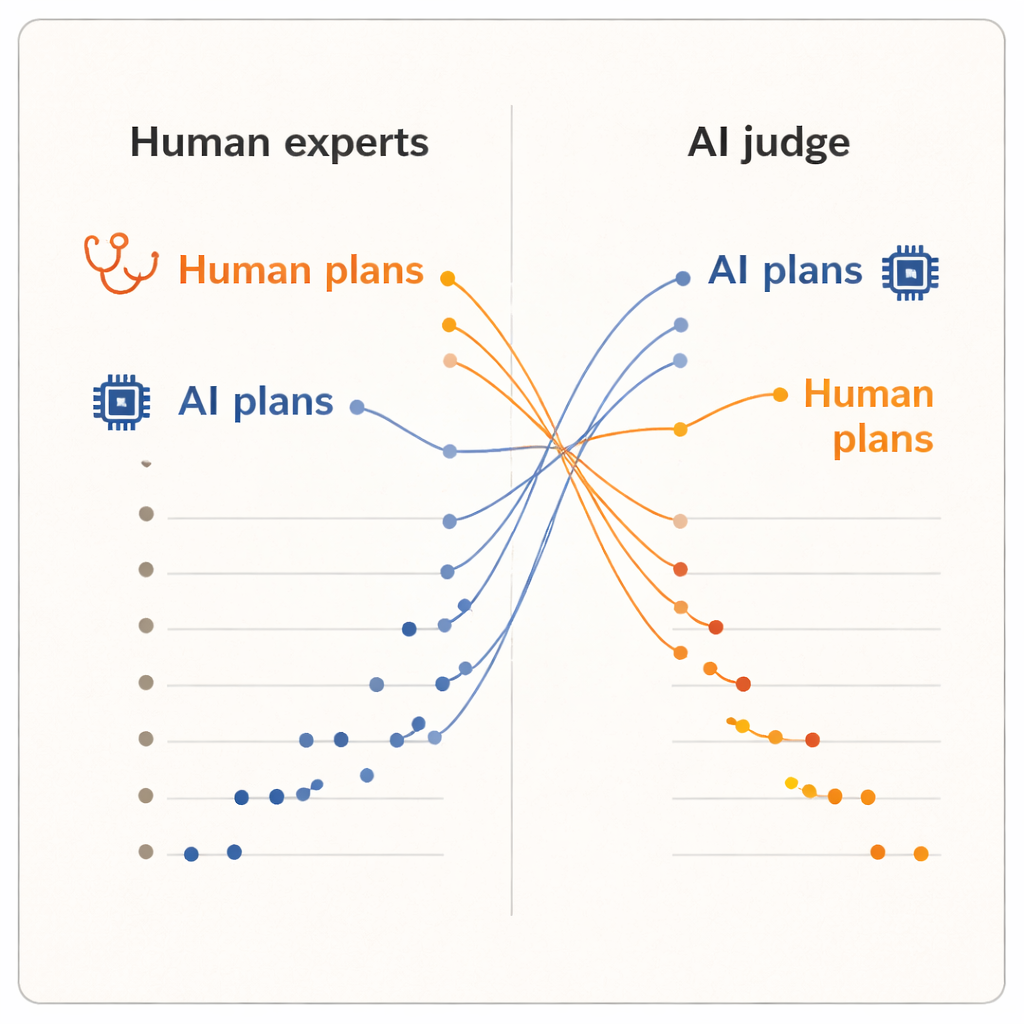
Diferentes concepciones de lo que hace un “buen” plan
Dado que los planes se normalizaron en redacción y los jueces desconocían la procedencia, los autores sostienen que esta división no puede explicarse por un pulido superficial. En cambio, sugiere que humanos y sistemas de IA traen métricas internas diferentes. Los clínicos probablemente se apoyan en la experiencia del mundo real: lo que suele ser factible en sus clínicas, cómo reaccionan los pacientes y qué compensaciones resultan aceptables en la práctica. En contraste, un juez de IA entrenado con grandes colecciones de texto puede favorecer planes que sigan patrones comunes en la literatura médica o las guías, aunque esos patrones no capturen por completo las limitaciones locales o las preferencias de los pacientes. El estudio es modesto en tamaño—solo diez clínicos, cinco casos y un único juez de IA—y mide la calidad percibida, no los resultados reales en pacientes. Aun así, la inversión es lo suficientemente notable como para plantear preguntas más profundas sobre cómo evaluamos la IA clínica.
Repensar cómo probamos y usamos la IA clínica
A partir de estos hallazgos, los autores extraen dos lecciones generales. Primero, las pruebas tradicionales de “respuesta correcta” para la IA médica pasan por alto gran parte de lo que importa en la atención real, donde los planes deben equilibrar eficacia, seguridad, coste, logística y deseos del paciente. Abogan por marcos de evaluación más ricos y multi-métricos que puntúen explícitamente estas dimensiones, utilicen múltiples jueces humanos y de IA y analicen dónde y por qué surgen desacuerdos en lugar de colapsar todo en una sola puntuación. Segundo, sugieren que las diferencias entre los juicios humanos y los de la IA pueden ser una característica, no solo un fallo. Si se usan con cuidado, los planes generados por IA podrían servir como una segunda opinión reflexiva que lleve a los médicos a revisar sus supuestos, mientras que los médicos aportan el contexto del mundo real y el juicio ético que la IA no tiene. Construir interfaces confiables y transparentes que expongan supuestos, permitan a los clínicos ajustar prioridades e inviten a la revisión crítica podría ayudar a convertir esta tensión entre perspectivas humanas y de IA en una toma de decisiones más segura y equilibrada.
Cita: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Palabras clave: apoyo a la decisión clínica, inteligencia artificial en medicina, colaboración humano-IA, planificación del tratamiento, sesgo en la evaluación