Clear Sky Science · es
Un modelo de predicción híbrido para la concentración de PM2.5 basado en IMFs de alta y baja frecuencia con descomposición EMD
Por qué importan pronósticos más limpios para la vida cotidiana
Las partículas finas en el aire, conocidas como PM2.5, son lo bastante pequeñas como para penetrar profundamente en los pulmones e incluso entrar en el torrente sanguíneo. En el norte de China, donde se concentran la industria pesada y la calefacción invernal, estas partículas a menudo alcanzan niveles que pueden activar alertas sanitarias, interrumpir el transporte e incluso obligar al cierre de fábricas y colegios. Este estudio plantea una pregunta muy práctica: ¿podemos predecir con mayor precisión los niveles de PM2.5 hora a hora, de modo que ciudades y residentes reciban advertencias más tempranas y fiables antes de que el aire se vuelva peligroso?
Una mirada más cercana a la mala calidad del aire en el norte de China
Los investigadores se centraron en seis ciudades importantes del norte de China: Pekín, Tianjin, Shijiazhuang, Taiyuan, Jinan y Zhengzhou. Estas ciudades representan zonas densamente pobladas e industrializadas donde los episodios de contaminación son frecuentes, sobre todo en invierno. Con datos oficiales de monitorización, el equipo recopiló lecturas horarias de PM2.5 durante todo el año 2021, obteniendo 8.760 puntos de datos por ciudad. Detectaron que los niveles de contaminación variaban ampliamente entre las ciudades; por ejemplo, Taiyuan presentó la media más alta de PM2.5, mientras que Pekín registró la más baja. Los eventos extremos fueron llamativos: en Taiyuan, las concentraciones se dispararon hasta 652 microgramos por metro cúbico durante un episodio de polvo y contaminación en marzo, llevando el índice de calidad del aire a su nivel máximo, un claro indicio de aire gravemente contaminado.
Por qué es tan difícil predecir la PM2.5
Los niveles de PM2.5 son empujados y atraídos por muchas fuerzas a la vez: emisiones locales de tráfico y fábricas, transporte regional de polvo y humo, velocidad del viento, humedad y más. Como resultado, el registro de contaminación se comporta menos como una curva suave y más como un latido irregular y agitado. Las herramientas estadísticas tradicionales o incluso las redes neuronales modernas pueden tener dificultades con este tipo de datos: pueden captar la tendencia general pero pasar por alto picos súbitos, o funcionar en una ciudad pero fallar en otra. Estudios anteriores trataron de mejorar los pronósticos añadiendo más detalle físico (como modelos de transporte químico) o confiando exclusivamente en métodos avanzados de aprendizaje automático. Este artículo, en cambio, combina varios métodos, cada uno elegido para manejar un “ritmo” diferente en los datos.
Dividir la señal en ritmos rápidos y lentos
El paso clave es una técnica llamada descomposición en modos empíricos (EMD), que descompone la serie temporal original de PM2.5 en varios componentes más simples. Algunos de estos componentes oscilan rápidamente y capturan picos y ruido a corto plazo; otros cambian despacio y reflejan la tendencia subyacente. Los autores agrupan los primeros cinco componentes como partes de “alta frecuencia” y los restantes, junto con un residuo de tendencia, como partes de “baja frecuencia”. Las piezas de alta frecuencia, que son más irregulares y fuertemente no lineales, se introducen en una red de memoria a largo y corto plazo (LSTM), un tipo de modelo de aprendizaje profundo adecuado para aprender patrones en el tiempo. Los componentes más suaves y de baja frecuencia se pasan a un método clásico de series temporales conocido como ARIMA, que es eficaz cuando los datos se comportan de manera más regular y casi lineal.
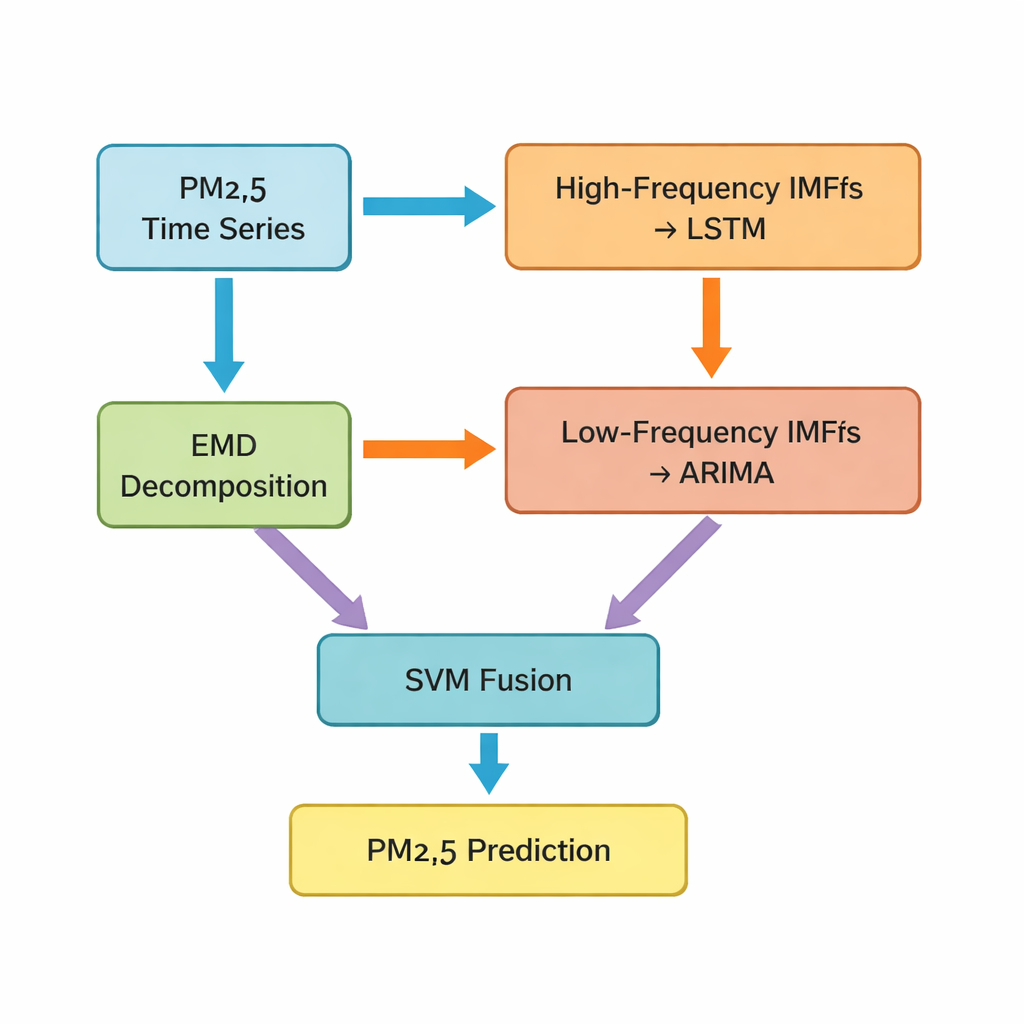
Combinar distintos modelos en un pronóstico más inteligente
Tras producir cada uno sus pronósticos parciales, el estudio encara todavía un desafío: cómo unir estas predicciones separadas en un único valor final de PM2.5 para la siguiente hora. Para ello, los autores utilizan una máquina de vectores de soporte (SVM), otro método de aprendizaje automático que aprende a ponderar y combinar las dos entradas. En esencia, la SVM actúa como un árbitro, decidiendo cuándo la visión “rápida” del mundo (patrones de alta frecuencia) importa más y cuándo debe dominar la visión “lenta” (tendencias a largo plazo). El sistema combinado, que los autores denominan Hybrid-EMDHL, se evalúa mediante varios indicadores de rendimiento, incluidos el error medio, el grado de concordancia entre predicciones y observaciones, y la capacidad del modelo para acertar la dirección del cambio —si los niveles suben o bajan—.
Alertas más claras y mejor planificación
El modelo híbrido supera a cualquiera de sus componentes por separado en las seis ciudades. No solo reduce los errores medios y los errores cuadráticos, sino que además mejora notablemente la capacidad de anticipar correctamente si la PM2.5 aumentará o disminuirá en la próxima hora —una característica crítica para emitir advertencias sanitarias a tiempo. En muchos casos, el enfoque híbrido reduce las medidas de error en más de la mitad en comparación con un único modelo de red neuronal, y su “precisión de dirección” supera 0,69, lo que significa que en algo más de dos tercios de los casos de prueba predice correctamente la tendencia. Para una persona no experta, esto se traduce en pronósticos de calidad del aire al estilo meteorológico que son más nítidos y fiables. Para los planificadores urbanos y las autoridades sanitarias, ofrece una herramienta práctica para apoyar acciones tempranas y focalizadas —como ajustar operaciones industriales o controles del tráfico— antes de que un episodio de contaminación alcance su punto máximo, ayudando a reducir la exposición y a proteger la vida diaria en algunas de las regiones urbanas más contaminadas de China.
Cita: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Palabras clave: Pronóstico de PM2.5, contaminación del aire, Norte de China, aprendizaje automático, descomposición de series temporales