Clear Sky Science · es
QPSODRL: una optimización de enjambre de partículas cuántica mejorada y un protocolo inteligente de agrupamiento y encaminamiento basado en aprendizaje reforzado profundo para redes de sensores inalámbricas
Redes de sensores más inteligentes para un mundo conectado
Desde la agricultura de precisión hasta los sistemas de alerta ante desastres, las redes de sensores inalámbricos vigilan silenciosamente nuestro entorno, recopilando datos de cientos o miles de pequeños dispositivos repartidos en grandes áreas. Su mayor debilidad es también su rasgo definitorio: cada sensor funciona con una pequeña batería que es difícil o imposible de reemplazar. Este artículo presenta una nueva forma de organizar y dirigir el flujo de datos en estas redes para que las baterías duren más, la información viaje con mayor fiabilidad y la red se adapte cuando cambian las condiciones.
Por qué los dispositivos diminutos necesitan gran inteligencia
En una red de sensores inalámbricos, cada nodo puede detectar, calcular y comunicarse, pero la energía es un recurso precioso. Si algunos nodos hacen demasiado trabajo, mueren antes, creando “zonas muertas” donde no se pueden recolectar datos. Para evitarlo, los diseñadores suelen agrupar los nodos en clústeres. Dentro de cada clúster, un nodo se convierte en cabeza de clúster: recopila lecturas de sus vecinos y las reenvía hacia una estación base central. Elegir qué nodos deberían ser cabezas de clúster y cómo debe saltar la información a través de la red es un rompecabezas complejo que cambia conforme las baterías se agotan. Las soluciones tradicionales basadas en reglas o en un único algoritmo a menudo se conforman demasiado pronto con patrones subóptimos o fallan cuando la forma de la red y los niveles de energía evolucionan con el tiempo.
Combinando enjambres inspirados en la mecánica cuántica con máquinas de aprendizaje
Este estudio presenta QPSODRL, un protocolo que une dos ideas potentes: un método de enjambre inspirado en la cuántica para formar clústeres y un motor de aprendizaje reforzado profundo para el encaminamiento. En la primera fase, “partículas” virtuales exploran distintas formas de asignar cabezas de clúster y miembros. Su comportamiento se guía mediante una medida de cuán uniformemente se distribuye la energía en la red, conocida como entropía. Cuando el uso de energía está desequilibrado, el algoritmo fomenta una amplia exploración de nuevos diseños de clúster; cuando la situación parece estable, afina las disposiciones prometedoras. Un paso especial de “perturbación élite” empuja ocasionalmente a los mejores candidatos en nuevas direcciones, ayudando a la búsqueda a escapar de callejones locales y evitar el uso excesivo de los mismos nodos de alta energía. 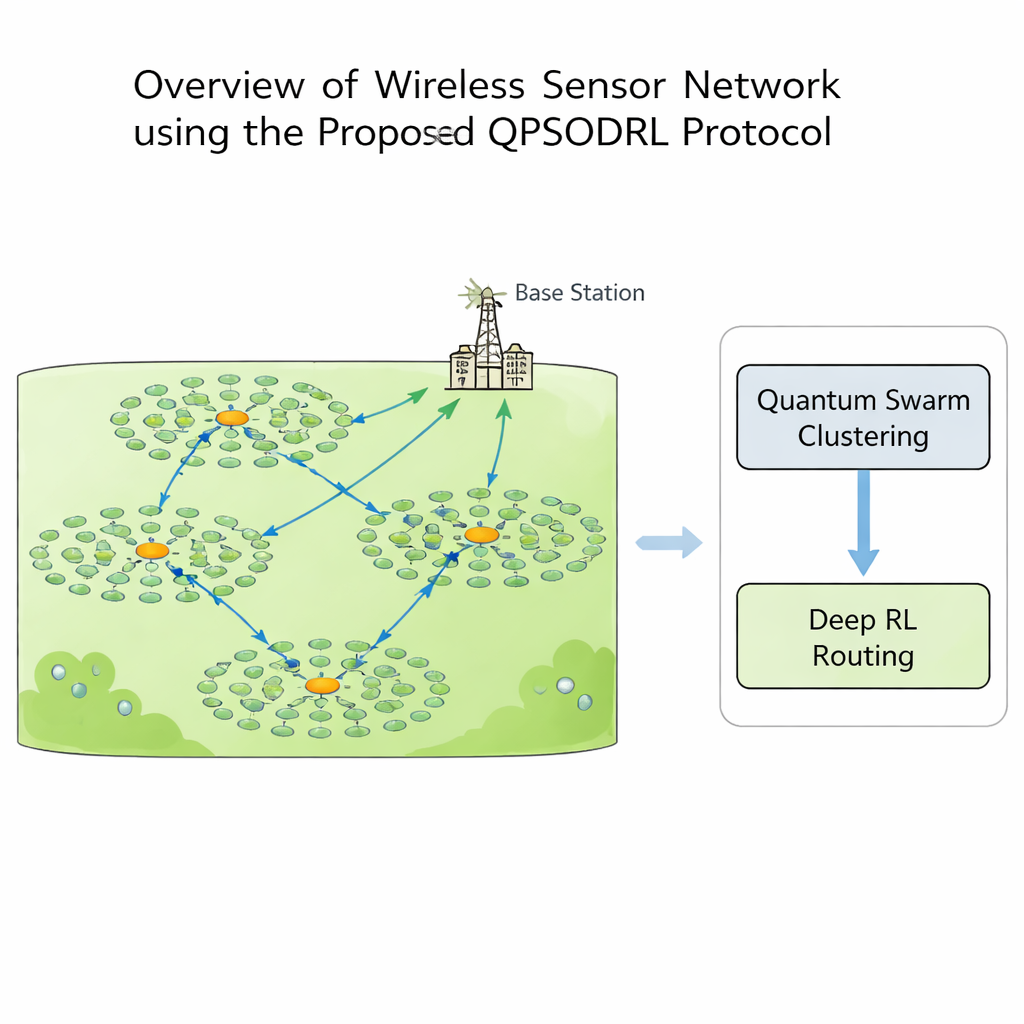
Enseñar a la red a aprender mejores rutas
Una vez formados los clústeres, la segunda fase decide cómo cada cabeza de clúster debe enviar sus datos a la estación base. En lugar de seguir rutas fijas, QPSODRL trata a cada cabeza de clúster como un agente en un proceso de aprendizaje. En cada paso, el agente observa su propia energía restante, la energía y la distancia de las cabezas vecinas y las demoras estimadas, y luego elige el siguiente salto. Una forma especializada de aprendizaje Q profundo, llamada Dueling Double Deep Q‑Network, estima cuán buena es cada elección a largo plazo. Los autores añaden un término de “entropía” para desalentar que el sistema se vuelva demasiado confiado demasiado pronto, de modo que siga explorando rutas alternativas. También diseñan un mecanismo mejorado de reproducción de experiencias que centra deliberadamente el aprendizaje en las situaciones más informativas —como cuando la energía es baja o las demoras aumentan— para que el modelo mejore más rápido en los escenarios que más importan. 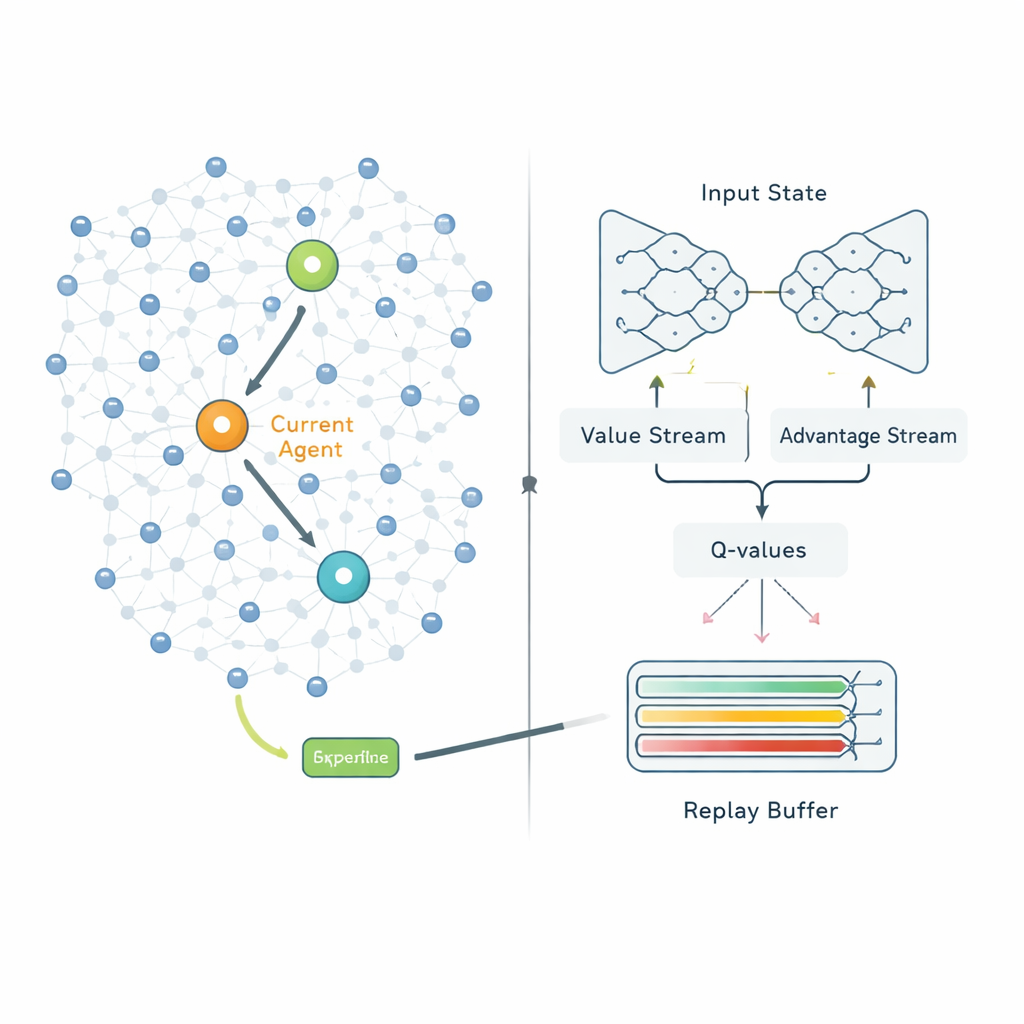
Poner el enfoque a prueba
Para evaluar el rendimiento de QPSODRL, el autor realiza simulaciones por ordenador detalladas de redes con 100 y 200 nodos distribuidos en áreas de diferentes tamaños y con distintas fracciones de nodos actuando como cabezas de clúster. El nuevo protocolo se compara con cuatro competidores recientes y avanzados que usan enjambres de partículas, optimización por ballenas, lógica difusa u otros esquemas híbridos y basados en aprendizaje. En todos los escenarios probados, QPSODRL mantiene la red activa durante más rondas de comunicación, entrega más paquetes de datos a la estación base y consume menos energía total. También distribuye la carga de trabajo entre las cabezas de clúster de forma más uniforme, como lo muestra una menor variación en la cantidad de tráfico que maneja cada cabeza. Estas ganancias son especialmente pronunciadas en configuraciones más exigentes, donde la estación base se coloca en el borde del campo, obligando a algunos nodos a realizar saltos más largos.
Qué significa esto para sistemas del mundo real
Para el público no especializado, el mensaje clave es que dotar a las redes de sensores de la capacidad de optimizar globalmente su estructura y aprender localmente a partir de la experiencia puede extender significativamente su vida útil. El agrupamiento inspirado en la cuántica de QPSODRL mantiene el uso de energía equilibrado, mientras que su encaminamiento basado en aprendizaje profundo se adapta a condiciones cambiantes sin un ajuste humano constante. Aunque los resultados se basan en simulaciones con nodos fijos y sin movimiento, sugieren que futuras implantaciones de sensores —desde ciudades inteligentes hasta observatorios ambientales— podrían funcionar durante más tiempo, fallar menos y aprovechar mejor la limitada energía de las baterías adoptando estrategias de control inteligente similares.
Cita: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Palabras clave: redes de sensores inalámbricos, encaminamiento eficiente en energía, aprendizaje reforzado profundo, optimización por enjambre, agrupamiento de redes