Clear Sky Science · es
Integración de conocimiento para regresión simbólica informada por la física usando grandes modelos de lenguaje preentrenados
Enseñar a las máquinas a adivinar las fórmulas de la naturaleza
Muchas de las grandes ideas de la ciencia se condensan en ecuaciones elegantes: desde cómo cae una bola hasta cómo las ondas de luz se propagan por el espacio. Este artículo explora una forma nueva de ayudar a las máquinas a redescubrir automáticamente esas ecuaciones a partir de datos crudos, permitiéndoles consultar un gran modelo de lenguaje—el mismo tipo de IA que impulsa los chatbots modernos—para que sus conjeturas no solo sean precisas, sino también físicamente coherentes.
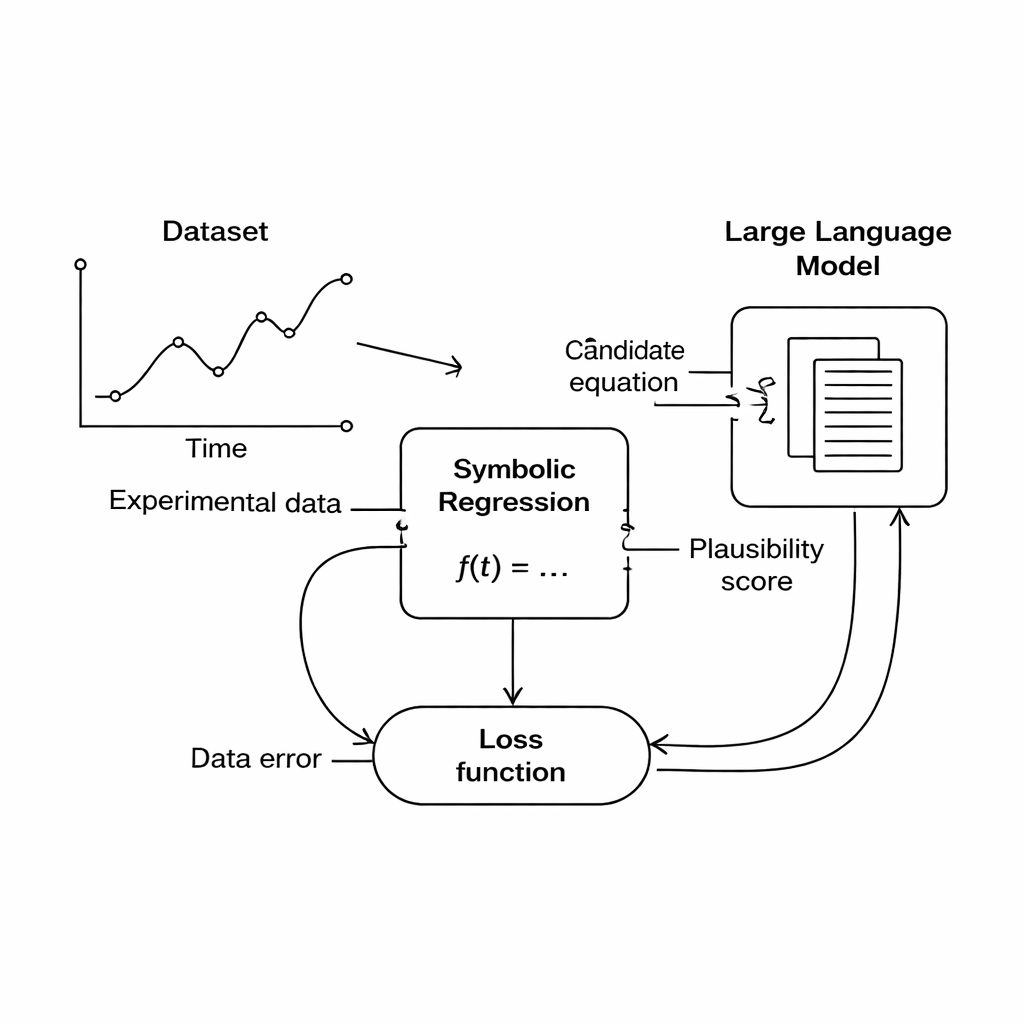
De datos brutos a leyes legibles por humanos
Los autores se centran en una técnica llamada regresión simbólica, que busca una fórmula matemática que relacione entradas y salidas medidas. A diferencia del ajuste de curvas habitual, la regresión simbólica no parte de una forma de fórmula fija; en su lugar, construye y hace evolucionar ecuaciones candidatas hasta que una se ajusta bien a los datos. Esto la convierte en una herramienta prometedora para el descubrimiento científico, porque puede potencialmente revelar nuevas relaciones que nadie haya formulado antes. Sin embargo, hay una trampa: una fórmula que ajusta perfectamente los datos puede seguir siendo un despropósito desde el punto de vista físico—por ejemplo, sumar una distancia a un tiempo o generar unidades que no corresponden a ninguna magnitud real.
Por qué sigue importando la intuición física
Para evitar tales sinsentidos, los investigadores han desarrollado versiones “informadas por la física” de la regresión simbólica que incorporan reglas conocidas de la naturaleza en la búsqueda. Estos métodos premian ecuaciones que, por ejemplo, conservan la energía o respetan la coherencia dimensional. Sin embargo, codificar este conocimiento ha requerido típicamente que expertos diseñen a mano restricciones y funciones de pérdida especiales para cada nuevo problema. Eso hace que el enfoque sea potente pero difícil de generalizar. Cada nuevo sistema físico puede necesitar su propio trabajo de diseño cuidadoso, lo que limita la accesibilidad de estas herramientas a quienes no son expertos.
Permitir que los modelos de lenguaje juzguen las ecuaciones
Este estudio propone una ruta diferente: en lugar de codificar rígidamente las reglas de dominio, usar un gran modelo de lenguaje (LLM) como un juez flexible de la plausibilidad científica. Durante la búsqueda, el motor de regresión simbólica produce ecuaciones candidatas que ajustan los datos en mayor o menor medida. Cada ecuación se traduce a texto y se envía al LLM, junto con un breve prompt que describe las magnitudes implicadas y las restricciones físicas conocidas. El LLM devuelve puntuaciones para tres aspectos: si las unidades de la ecuación tienen sentido, cuán simple es y si parece físicamente realista. Estas puntuaciones se incorporan a la función objetivo principal, de modo que el ordenador ahora equilibra “ajusta los datos” con “parece buena física” al elegir qué ecuaciones seguir mejorando.
Probando el método
Para evaluar su eficacia, los autores realizaron extensos experimentos por ordenador en tres problemas clásicos: la caída libre de una bola bajo la gravedad terrestre, el movimiento armónico simple de una masa en un resorte y una onda electromagnética amortiguada. Para cada sistema simularon miles de mediciones ruidosas bajo condiciones variadas y pidieron a tres programas populares de regresión simbólica que recuperaran las ecuaciones subyacentes, ya sea con o sin ayuda de un LLM. Probaron tres modelos de lenguaje compactos y de código abierto—Mistral, Llama 2 y Falcon—y exploraron cómo distintos diseños de prompt, desde contexto mínimo hasta descripciones completas e incluso la fórmula verdadera, cambiaban la guía del LLM. En la mayoría de los escenarios, añadir la puntuación del LLM mejoró cuánto se parecían las ecuaciones recuperadas a las leyes conocidas y las hizo más robustas al ruido, con la combinación de PySR (una biblioteca de regresión simbólica) y Mistral rindiendo generalmente mejor.
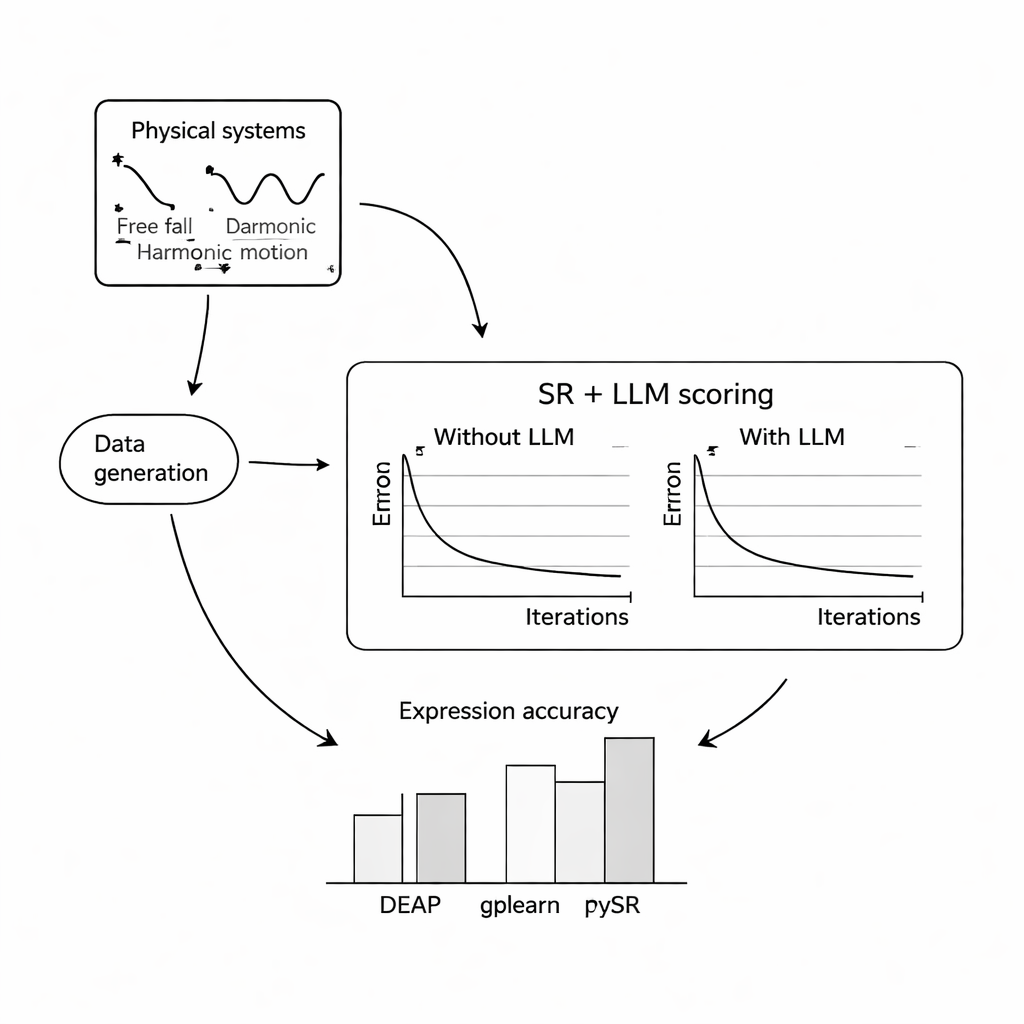
Cuando las palabras orientan las matemáticas
Un hallazgo clave es que la redacción del prompt afecta fuertemente los resultados. Cuando los prompts incluían descripciones claras de las variables, la naturaleza del experimento y, en ocasiones, la fórmula objetivo exacta, la búsqueda guiada por el LLM convergía de forma más fiable a la estructura correcta. En estos casos más ricos, las ecuaciones descubiertas a menudo eran estructuralmente idénticas a las leyes de referencia, no solo cercanas numéricamente. Los autores también probaron cómo se comporta el enfoque frente a niveles crecientes de ruido aleatorio en las mediciones. Aunque todos los métodos se degradaron a medida que los datos se volvían más ruidosos y las ecuaciones subyacentes más complejas, las versiones aumentadas con LLM tendieron a perder precisión más despacio que sus homólogas estándar, lo que sugiere que el sentido de plausibilidad del modelo de lenguaje puede actuar como una influencia estabilizadora.
Qué significa esto para futuros descubrimientos
Para el lector general, el mensaje principal es que la IA basada en texto puede hacer más que redactar ensayos o responder preguntas: también puede guiar a otros algoritmos hacia ecuaciones científicas que “suenen bien” según nuestro conocimiento actual de la naturaleza. El método presentado aquí no garantiza que toda ecuación descubierta sea correcta y sigue dependiendo de la supervisión humana y de prompts cuidadosamente formulados. Pero muestra que los grandes modelos de lenguaje, entrenados con océanos de texto científico, pueden servir como una fuente reutilizable de conocimiento de dominio, ayudando a las herramientas automatizadas a pasar de ajustar datos a ciegas a proponer leyes que los científicos pueden interpretar, verificar y desarrollar.
Cita: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Palabras clave: regresión simbólica, IA informada por la física, grandes modelos de lenguaje, descubrimiento científico, aprendizaje de ecuaciones