Clear Sky Science · es
Un enfoque de aprendizaje por refuerzo profundo para el análisis del movimiento en la danza
Enseñar a los ordenadores a mirar la danza como lo hacemos nosotros
Desde el ballet hasta el hip-hop, la danza está llena de sutiles cambios de ritmo y postura que el ojo humano capta al instante, pero que les cuesta ver a los ordenadores. Este estudio presenta una nueva manera de hacer que la inteligencia artificial “observe” vídeos de danza más como un experto humano: pasando por alto pasos rutinarios para centrarse en momentos breves y reveladores que definen cada estilo. El resultado es un sistema que reconoce los géneros de danza con mayor precisión mientras visualiza mucho menos vídeo, lo que podría mejorar desde archivos digitales hasta tecnología para el deporte y el entretenimiento.
Por qué los vídeos de danza son difíciles para las máquinas
A primera vista, entrenar a un ordenador para reconocer estilos de danza parece simple: introducir vídeos y dejar que el aprendizaje profundo encuentre patrones. En la práctica, la mayoría de los sistemas existentes malgastan esfuerzo. Los modelos de vídeo estándar o bien procesan cada fotograma o muestrean fragmentos a intervalos fijos, asumiendo que todos los momentos son igual de importantes. Pero los estilos de danza suelen diferir en detalles diminutos—cómo gira un pie, cuándo pivota una pareja o el tiempo de una pirueta—más que en un movimiento continuo. Eso significa que muchos fotogramas son repetitivos o poco informativos, y las posturas clave pueden caer entre los puntos de muestreo fijo, lo que genera confusión entre, por ejemplo, un vals y un foxtrot.
Una forma más inteligente de ojear el vídeo
Los investigadores proponen un marco llamado Muestreo Temporal Atento basado en Refuerzo, o RATS, que trata el análisis de vídeo como una búsqueda activa en lugar de una observación pasiva. En lugar de avanzar fotograma a fotograma, el sistema divide un vídeo de danza en clips cortos y primero convierte cada clip en una descripción compacta de su movimiento usando una red convolucional 3D especializada. Estos resúmenes de movimiento se almacenan luego en memoria. Sobre esto, un agente de toma de decisiones recorre la secuencia de clips, eligiendo si avanzar con un salto pequeño, un salto mayor o detenerse y emitir una predicción de estilo. En efecto, el sistema aprende a navegar en el tiempo, deteniéndose en patrones reveladores y saltándose tramos menos útiles.
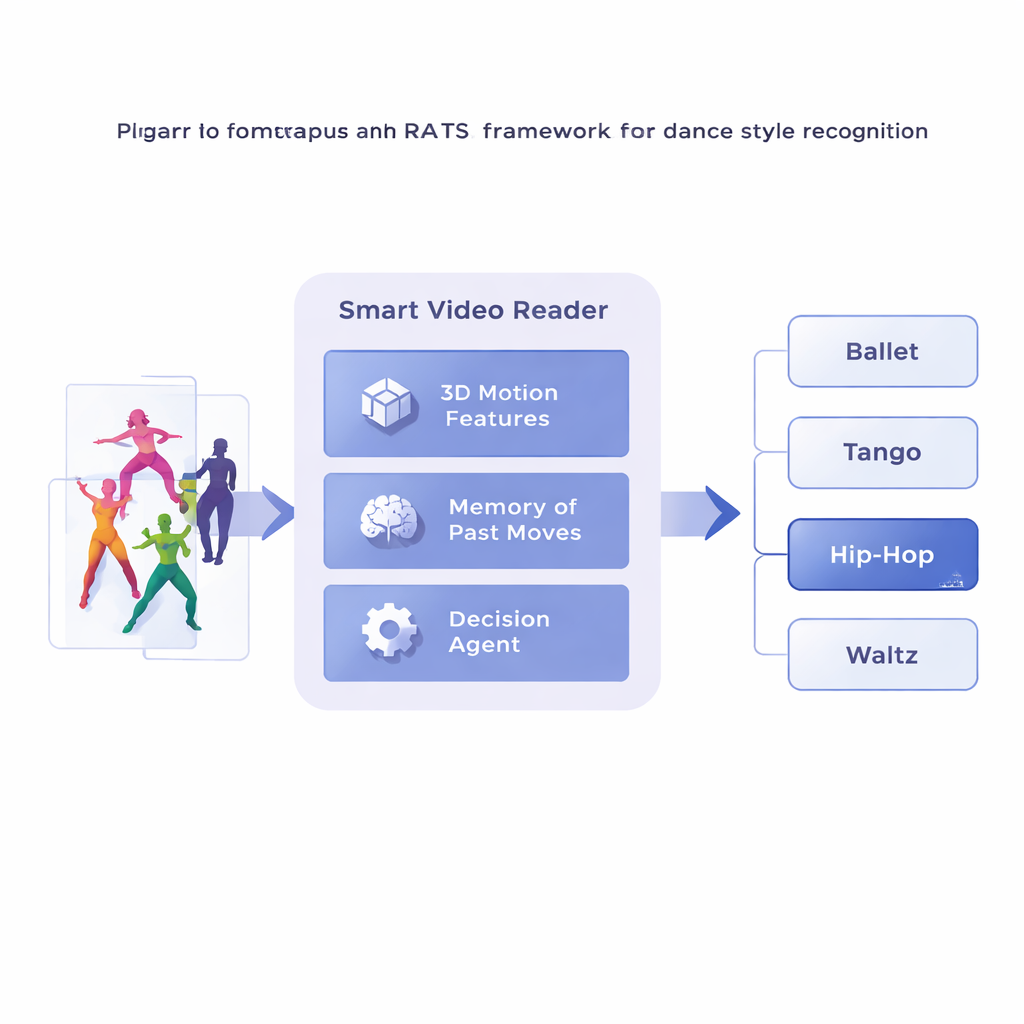
Aprender cuándo mirar y cuándo decidir
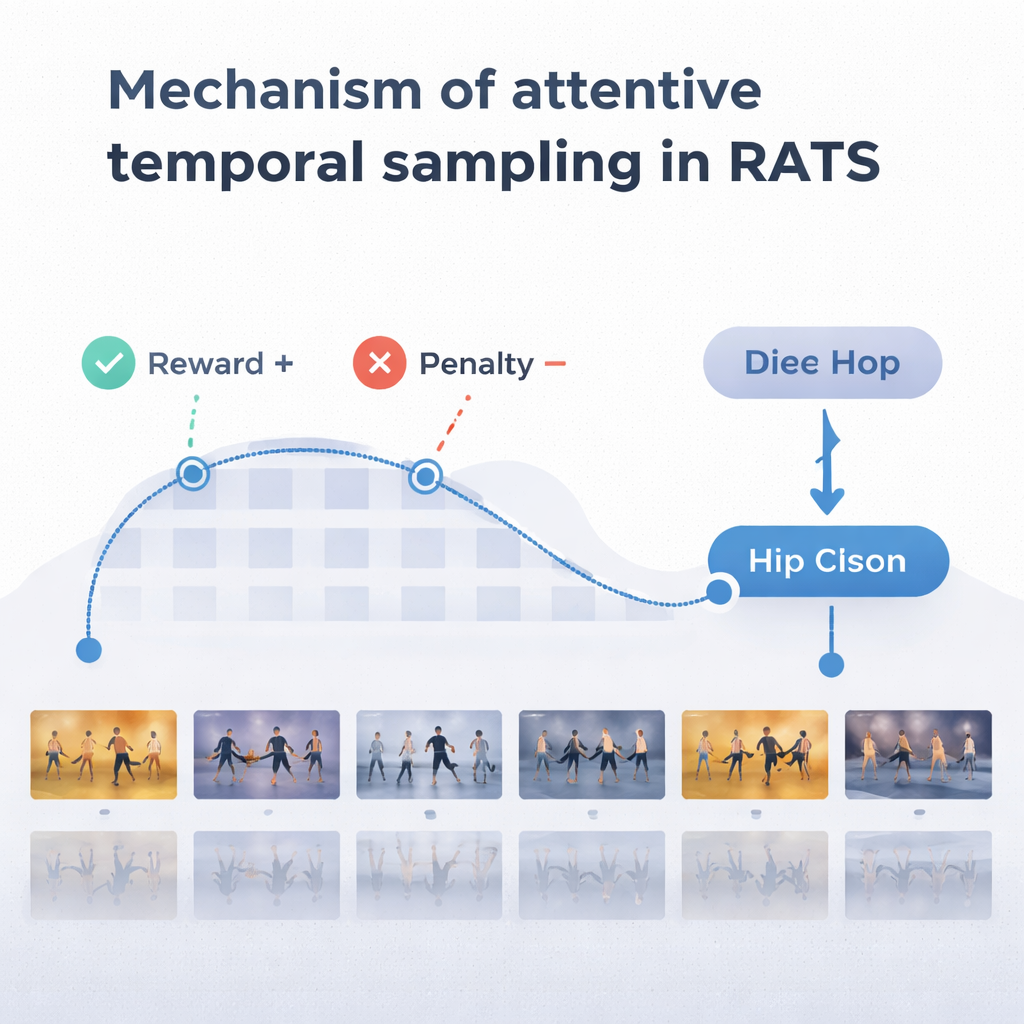
Para tomar decisiones sensatas, el agente se basa en una forma de memoria inspirada en cómo recordamos tanto el movimiento pasado como el emergente. Una red recurrente bidireccional lleva la cuenta de lo que el sistema ya ha “visto” y de cómo los clips actuales se relacionan con ese historial. En cada paso, el agente sopesa tres opciones: dar un pequeño salto para inspeccionar detalles finos como el trabajo de pies, hacer un salto mayor sobre movimientos repetitivos o detenerse y clasificar la danza. El sistema se entrena con recompensas y penalizaciones: gana una gran puntuación positiva por una decisión correcta, una gran negativa por una errónea y una pequeña penalización cada vez que avanza con un salto. Este equilibrio anima al agente a ser preciso y eficiente: esperar hasta tener suficiente evidencia, pero sin recorrer todo el vídeo.
Superando a los clasificadores convencionales de danza
El equipo probó RATS en el conjunto de datos Let’s Dance, una colección exigente de 1.000 vídeos que abarcan diez estilos, desde flamenco y tango hasta swing y cuadrilla. En comparación con varios métodos existentes, incluidas redes profundas estándar y otros modelos centrados en la danza, RATS obtuvo la mayor precisión—alrededor del 92%—y el mejor equilibrio global entre precisión y exhaustividad. También resultó estadísticamente superior a competidores fuertes, no solo diferente por casualidad. Importante: el sistema alcanzó estos resultados analizando, de media, solo alrededor del 38% de los fotogramas del vídeo. Muestrear de forma uniforme cada pocos fotogramas era más rápido pero perdía momentos cruciales y degradaba el rendimiento; procesar cada fotograma era más lento y aun así menos preciso que el enfoque selectivo.
Qué significa esto más allá de la pista de baile
Para un no especialista, el mensaje central es simple: los ordenadores pueden hacerlo mejor cuando aprenden a ser espectadores selectivos. Al enseñar a una IA a concentrarse en los “momentos dorados” en el tiempo, este trabajo demuestra que las máquinas pueden reconocer movimientos humanos complejos con mayor precisión mientras usan menos recursos. Aunque el estudio se centra en la danza, la misma idea podría ayudar a los sistemas a identificar elementos clave en rutinas deportivas, grabaciones de seguridad o cualquier vídeo largo donde los eventos importantes son breves y dispersos. En otras palabras, mirar con más inteligencia—no mirar más—podría ser el futuro de la comprensión de vídeo.
Cita: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Palabras clave: reconocimiento de baile, análisis de vídeo, aprendizaje profundo, aprendizaje por refuerzo, movimiento humano