Clear Sky Science · es
Modelo chino de extracción de relaciones espaciales mediante la integración de características semánticas geográficas
Enseñar a las máquinas a entender dónde están los lugares
Cada día describimos ubicaciones con frases sencillas: un pueblo está al sur de un río, un parque está cerca de una universidad, una autopista atraviesa una provincia. Convertir este tipo de lenguaje cotidiano en conocimiento digital preciso es vital para mapas inteligentes, aplicaciones de navegación e investigación geográfica. Este artículo presenta un nuevo método, llamado PURE‑CHS‑Attn, que ayuda a las máquinas a leer textos en chino y a determinar automáticamente las relaciones espaciales entre lugares con mayor precisión que antes.
Por qué importa el lenguaje espacial
Las relaciones espaciales son palabras y frases que nos indican cómo se conectan los lugares en el espacio, como “dentro de”, “junto a”, “al norte de” o “a 30 kilómetros de”. Forman un puente entre el mundo real que vemos en los mapas y los conceptos que usamos mentalmente. En los sistemas de información geográfica (SIG), estas relaciones sustentan cómo se organiza, busca y analiza la información. También son fundamentales en otros campos: por ejemplo, en la combinación de imágenes satelitales, el seguimiento de movimiento en vídeo, la planificación de layouts industriales o el estudio de cómo el clima y la orografía afectan la biodiversidad. Dado que gran parte de esta información está escrita en lenguaje natural, disponer de herramientas fiables que lean textos y extraigan relaciones espaciales automáticamente es cada vez más importante.
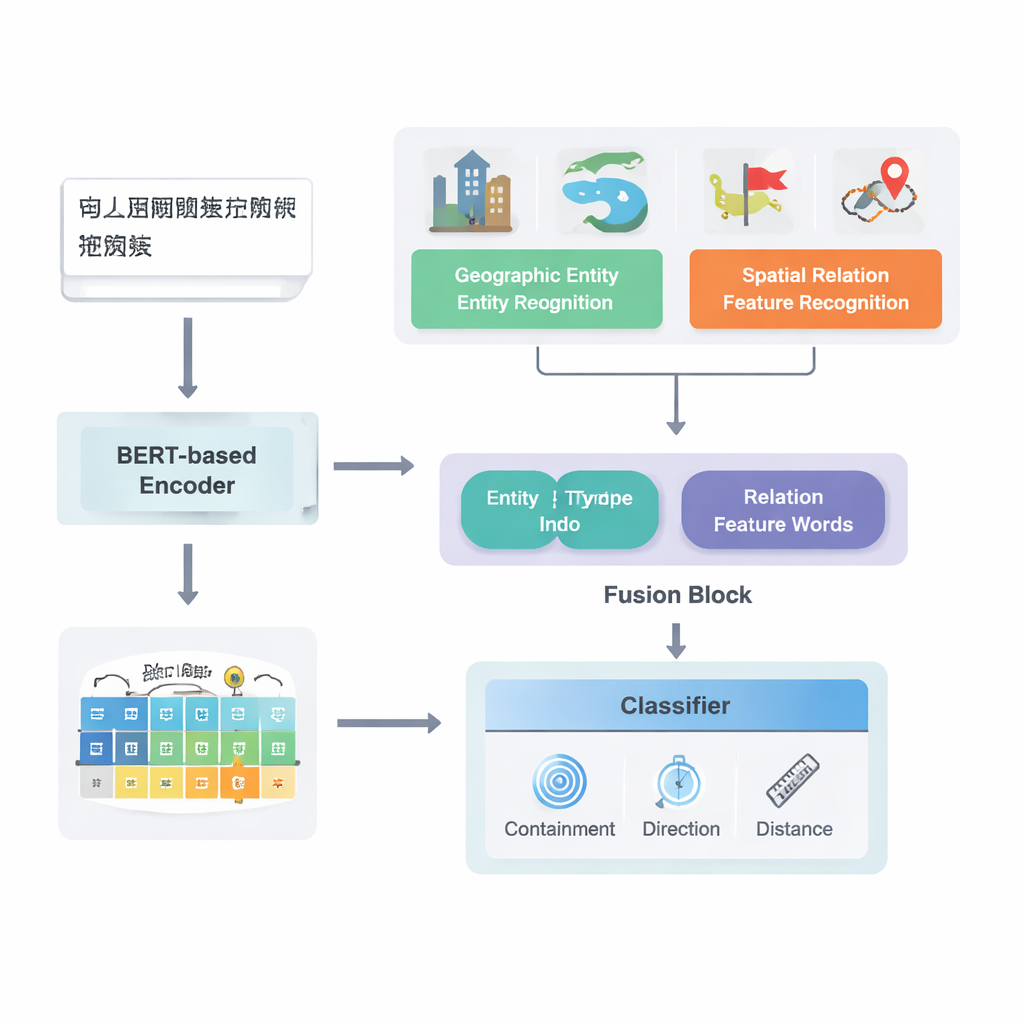
Del texto crudo a las relaciones mapeadas
Los autores se centran en textos en chino y se basan en una robusta arquitectura de aprendizaje profundo existente conocida como PURE. Su modelo mejorado, PURE‑CHS‑Attn, funciona en varias etapas. Primero, escanea oraciones para encontrar entidades geográficas como montañas, ríos, ciudades y regiones administrativas, y etiqueta cada una con un tipo (por ejemplo, superficie terrestre, masa de agua, equipamiento público, sitio histórico o división administrativa). A continuación, detecta las “palabras características” de la relación espacial, como “limita con”, “atraviesa”, “al sur de” o “cerca de”, que indican cómo se relacionan dos lugares. Un potente modelo de lenguaje, BERT‑wwm‑ext, transforma los caracteres de cada oración en vectores numéricos que capturan su significado y contexto. Estos vectores alimentan componentes separados que reconocen entidades y palabras de relación y luego pasan sus resultados a un módulo de fusión.
Fusionar el conocimiento humano con el aprendizaje automático
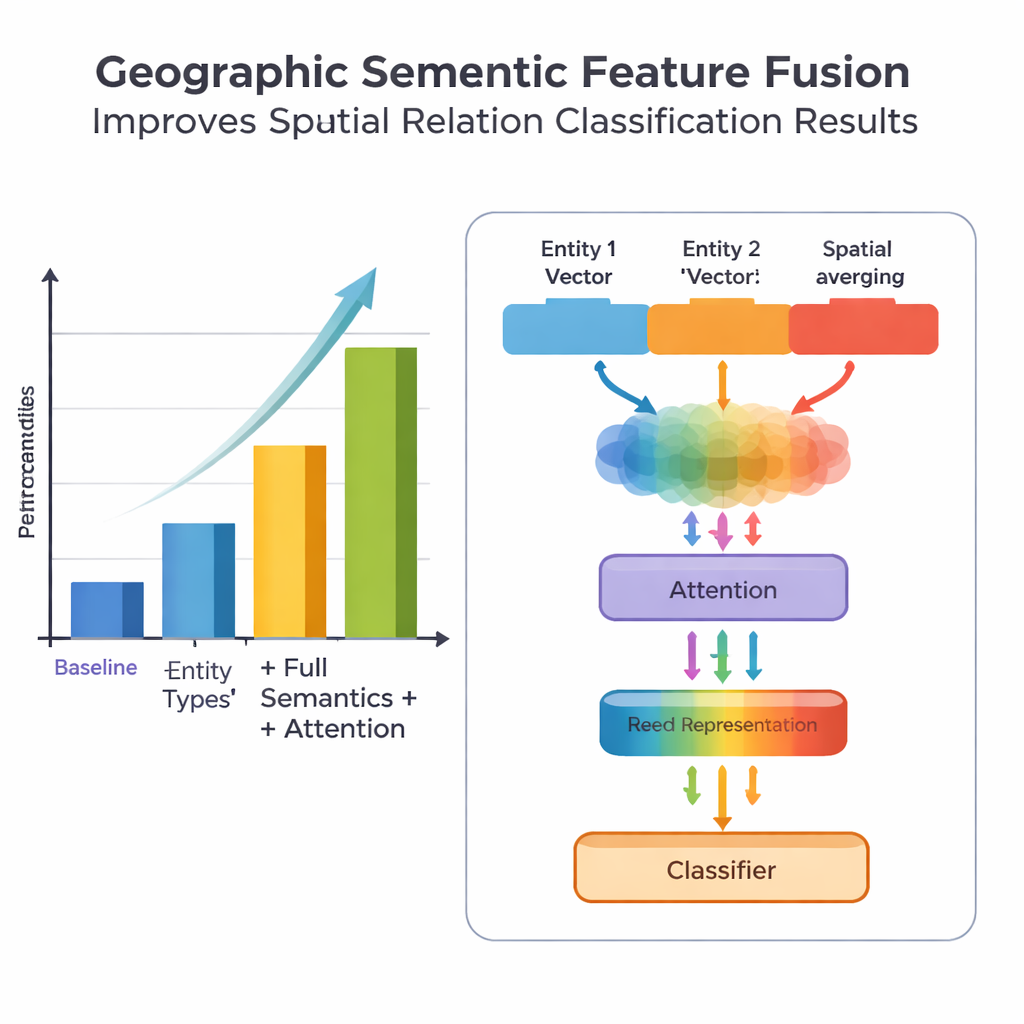
La novedad clave del trabajo reside en cómo fusiona el conocimiento geográfico con los patrones aprendidos del texto. En lugar de tratar cada palabra por igual, el modelo explota dos tipos de información semántica que los humanos usan de forma natural: el tipo de cada entidad geográfica y las palabras características espaciales que las conectan. El módulo de fusión primero combina los vectores de las dos entidades usando pesos que dependen de la frecuencia con la que distintos tipos de lugares (como dos divisiones administrativas frente a un río y un condado) participan en distintos tipos de relación. Después incorpora los vectores de las palabras características espaciales. Sobre esta “fusión básica”, los autores añaden un mecanismo de atención que permite al modelo centrarse dinámicamente en las partes más informativas de la combinación entidad‑palabra. La representación fusionada final se pasa a un clasificador, que puede asignar uno o varios tipos de relación —topológica (como contención o adyacencia), direccional (norte, sur, etc.) o basada en la distancia— entre cada par de lugares en la oración.
Poner el modelo a prueba
Para evaluar su enfoque, el equipo ensambló y anotó cuidadosamente un conjunto de datos procedente de la Encyclopedia of China: Chinese Geography, que contiene 1.381 oraciones y 368 pares de relaciones espaciales. Compararon varias versiones del modelo: una línea base que usa solo información de ubicación burda, una versión con tipos de entidad más finos, una versión que además añade palabras características espaciales y su modelo completo PURE‑CHS‑Attn con el nuevo diseño de fusión y atención. Según métricas estándar de precisión, recall y F1, PURE‑CHS‑Attn mejoró el rendimiento en aproximadamente un 7 % en precisión, 6,5 % en recall y 6,7 % en F1 respecto a la línea base. Fue especialmente sólido en el reconocimiento de relaciones topológicas y direccionales, y manejó mejor los tipos de relación raros de “few‑shot” que los modelos más simples. Al compararlo con tres sistemas recientes de vanguardia, incluido uno basado en modelos de lenguaje grandes, PURE‑CHS‑Attn quedó en un cercano segundo lugar, manteniéndose mucho más ligero y fácil de desplegar.
Desafíos y direcciones futuras
A pesar de estas mejoras, el modelo sigue teniendo dificultades con las relaciones de distancia, especialmente cuando solo existe un puñado de ejemplos de entrenamiento. Los autores muestran que su conjunto de datos contiene muy pocos casos de ese tipo, lo que limita lo que cualquier método exigente en datos puede aprender. También señalan que promediar a ciegas muchas palabras características espaciales en una oración puede introducir ruido, problema que su mecanismo de atención ayuda a mitigar pero no resuelve completamente. Mirando al futuro, sugieren dos trayectorias prometedoras: ampliar y equilibrar los datos de entrenamiento mediante aumentación, y combinar su fusión semántica geográfica con técnicas de modelos de lenguaje grandes y aprendizaje basado en prompts para mejorar aún más el rendimiento en escenarios con pocos datos manteniendo la eficiencia del sistema.
Qué significa esto para la cartografía cotidiana
En términos sencillos, esta investigación enseña a las máquinas a leer descripciones espaciales en chino de manera más parecida a como lo hacen los humanos, prestando atención a qué tipos de lugares se mencionan y a cómo se expresan exactamente sus relaciones. El modelo PURE‑CHS‑Attn demuestra que mezclar conocimiento geográfico estructurado con el aprendizaje profundo moderno conduce a una extracción más precisa y robusta de “quién está dónde, en relación con qué” a partir del texto. Esto abre el camino a sistemas SIG más inteligentes y automatizados, grafos de conocimiento geográfico más ricos y mejores herramientas para explorar cómo se describe el espacio en la ciencia, la política y la comunicación cotidiana.
Cita: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Palabras clave: extracción de relaciones espaciales, IA geoespacial, semántica geográfica, minería de texto en chino, automatización SIG