Clear Sky Science · es
Enfoque de aprendizaje automático para la identificación de variedades de trigo mediante imágenes de una sola semilla
Por qué importa ordenar las semillas con más inteligencia
Para agricultores y empresas de semillas, distinguir una variedad de trigo de otra es crucial. Plantar el tipo equivocado puede significar rendimientos menores, menor resistencia a enfermedades y cultivos que no están adaptados al suelo o clima local. Sin embargo, a simple vista, las distintas variedades de trigo se parecen casi idénticas. Este estudio explora cómo la inteligencia artificial y las fotografías digitales de semillas individuales pueden identificar de forma fiable variedades estrechamente relacionadas, allanando el camino para un control de calidad de semillas más rápido, barato y objetivo.
Del ojo experto a las comprobaciones con cámara
Hoy muchos sistemas de inspección de semillas siguen dependiendo de expertos humanos que juzgan visualmente la variedad y la pureza. Este proceso es lento, costoso y propenso a discrepancias, sobre todo porque muchos cultivares de trigo se diferencian solo por cambios sutiles en la forma o el patrón de la superficie. Los autores se propusieron sustituir este enfoque subjetivo por un sistema automatizado que utiliza imágenes de granos individuales tomadas en una pequeña caja con iluminación controlada. Al estandarizar cuidadosamente la iluminación, la distancia y el color de fondo, crearon un registro visual limpio de seis variedades iraníes comunes, generando decenas de miles de fotos de semillas para entrenar y evaluar modelos informáticos.
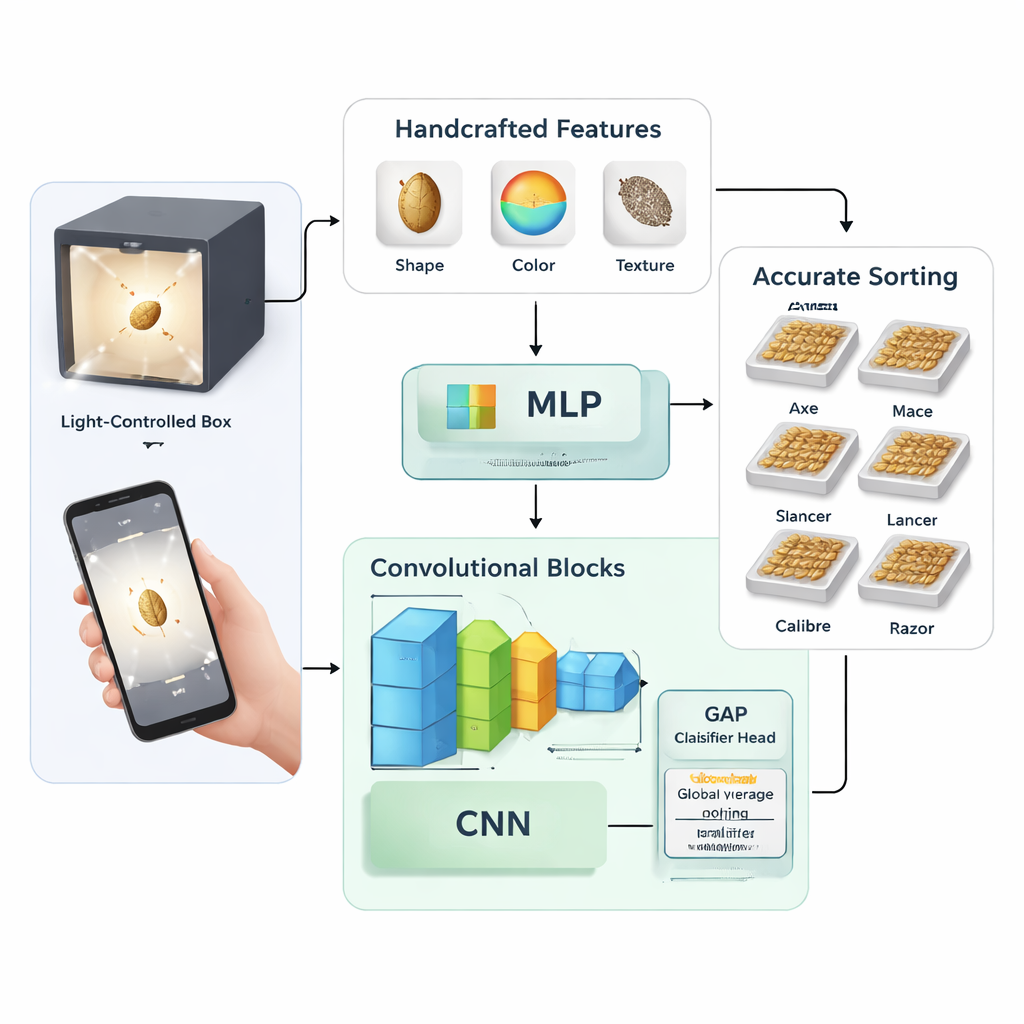
Dos maneras de enseñar a una máquina a ver semillas
El estudio compara dos estrategias generales para enseñar a una máquina a reconocer variedades de trigo. En la primera, los investigadores diseñaron manualmente 58 medidas numéricas a partir de cada imagen de semilla, incluyendo formas básicas (como longitud y área), estadísticas de color en distintos espacios cromáticos y patrones de textura. Luego usaron una técnica llamada análisis de componentes principales para condensar estas medidas en 27 características clave, que se introdujeron en una red neuronal tradicional llamada perceptrón multicapa. En la segunda estrategia, omitieron el diseño manual de características y entrenaron redes neuronales convolucionales—modelos de IA enfocados en imágenes—para que aprendieran patrones útiles directamente a partir de los píxeles brutos.
Construyendo un modelo de aprendizaje profundo ligero pero potente
El enfoque de aprendizaje profundo se probó en varias formas. Los autores diseñaron su propia red relativamente pequeña con dos a cuatro bloques convolucionales apilados y experimentaron con distintos ajustes de entrenamiento, como tasas de aprendizaje, niveles de abandono (dropout) y tamaños de lote. También compararon dos maneras de rematar la red: una clásica capa "completamente conectada" frente a un método más compacto llamado global average pooling, que reemplaza grandes capas densas por un simple paso de promediado antes de la clasificación final. Para contexto, afinaron dos arquitecturas de gran tamaño y uso extendido—Inception-ResNet-v2 y EfficientNet-B4—con el mismo conjunto de datos de trigo para ver cómo se compara un modelo pequeño y a medida frente a redes profundas de propósito general.
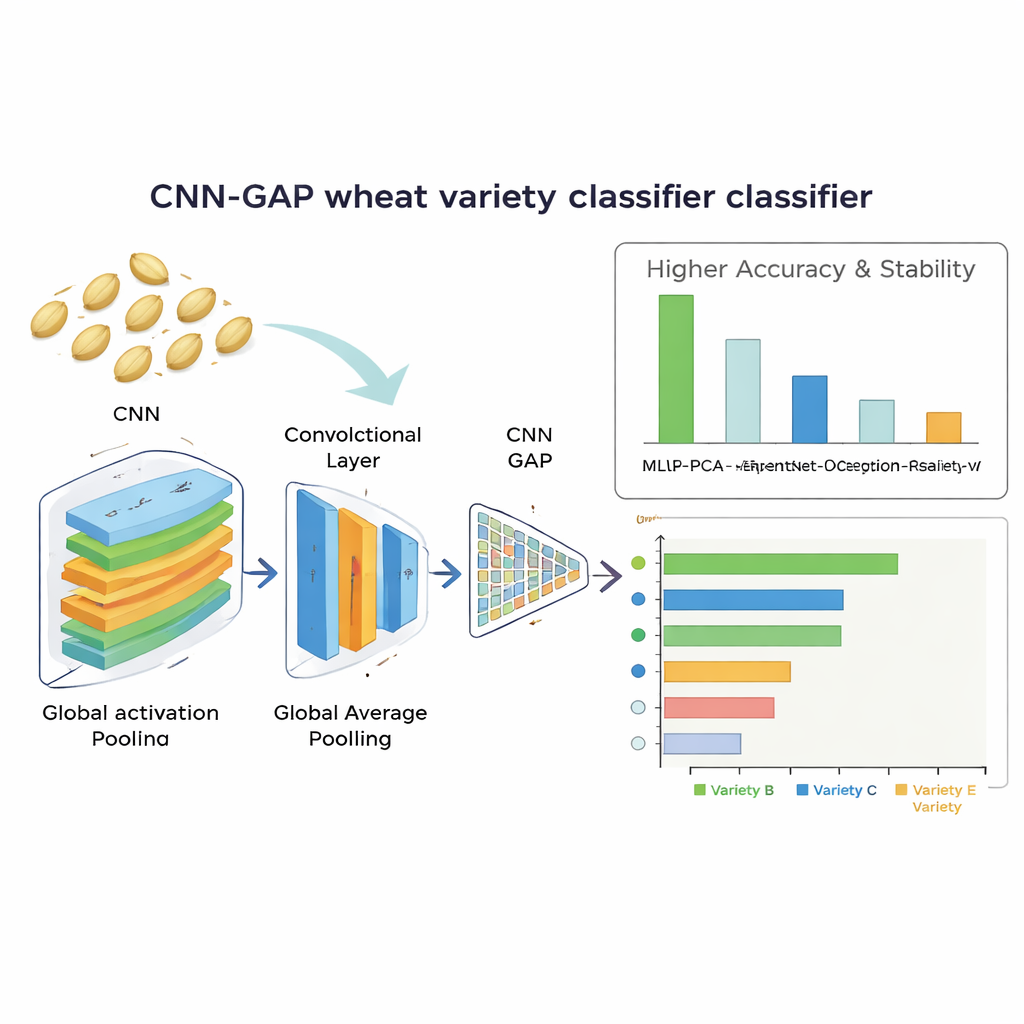
Qué tan bien el sistema lee el grano
El mejor rendimiento lo obtuvo la red convolucional diseñada a medida que empleaba global average pooling. Identificó correctamente las variedades de trigo en aproximadamente el 92% de los casos y mostró resultados muy estables en ejecuciones de entrenamiento repetidas. Este modelo no solo superó a las grandes redes preentrenadas, sino que también venció al enfoque de características manuales, que alcanzó alrededor del 86% de exactitud tras la reducción de dimensionalidad. El análisis de los patrones de confusión mostró que el modelo más ligero hizo un trabajo particularmente bueno separando variedades con aspecto muy similar, mientras que los modelos profundos de transferencia de aprendizaje tendieron a sobreajustarse al conjunto de datos limitado. Es importante destacar que la red ganadora fue eficiente: procesó cada imagen de semilla en unos 13,6 milisegundos y contenía solo cerca de 2,1 millones de parámetros ajustables, lo que la hace realista para su uso en equipos de clasificación en tiempo real y de bajo coste.
Límites, uso en el mundo real y próximos pasos
Cuando el mismo modelo se probó en un cultivo completamente distinto—semillas de garbanzo—su precisión cayó drásticamente, lo que revela que un sistema afinado para diferencias finas entre granos de trigo no se generaliza automáticamente a otras especies. Del mismo modo, dado que todas las imágenes de entrenamiento provinieron de una cámara cuidadosamente controlada, el rendimiento puede disminuir bajo iluminación variable del campo o con granos parcialmente ocultos. Aun así, el trabajo demuestra que un modelo compacto y bien diseñado de aprendizaje profundo, alimentado con imágenes estandarizadas de una sola semilla, puede distinguir de forma confiable variedades de trigo que son casi indistinguibles a simple vista. Con datos de entrenamiento más amplios y condiciones de imagen más diversas, sistemas similares podrían convertirse en herramientas prácticas para la certificación automatizada de semillas, ayudando a los agricultores a asegurar lotes de semilla más puros y cosechas más previsibles.
Cita: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Palabras clave: semillas de trigo, aprendizaje profundo, clasificación basada en imágenes, calidad de la semilla, agricultura de precisión