Clear Sky Science · es
Evaluación de la precisión de datos nucleares aprendidos por máquina en neutrónica Monte Carlo de núcleos completos de reactores nucleares y análisis de eficiencia computacional
Por qué importan las simulaciones de reactores más rápidas
Las centrales nucleares dependen de modelos informáticos detallados para predecir cómo se comporta el combustible a lo largo de meses y años de operación. Estos modelos son cruciales para la seguridad, la eficiencia y el diseño de nuevos reactores, pero son notoriamente lentos y exigentes en memoria. Este artículo explora si el aprendizaje automático puede reducir las enormes tablas de datos nucleares que impulsan estas simulaciones—reduciendo drásticamente el coste computacional—sin sacrificar la precisión física de la que dependen los ingenieros.
Reduciendo los datos que sustentan la física
Cada vez que un neutrón simulado se desplaza por un núcleo de reactor virtual, el código consulta grandes tablas que describen la probabilidad de que el neutrón se disperse, sea absorbido o provoque una fisión. Estas tablas, llamadas bibliotecas de datos nucleares, codifican probabilidades en miles de puntos de energía para muchos isótopos presentes en el combustible y sus subproductos. Los autores se basan en un método previo de aprendizaje automático que “adelgaza” esas tablas: elimina puntos de energía redundantes preservando características agudas como umbrales de reacción y picos de resonancia, donde las probabilidades cambian rápidamente. En lugar de regenerar los datos mediante una larga cadena de procesamiento tradicional, el método edita directamente los archivos HDF5 nativos de OpenMC, conservando solo aproximadamente entre el 10 % y el 50 % de los puntos de la malla original para 23 nucleidos especialmente importantes.
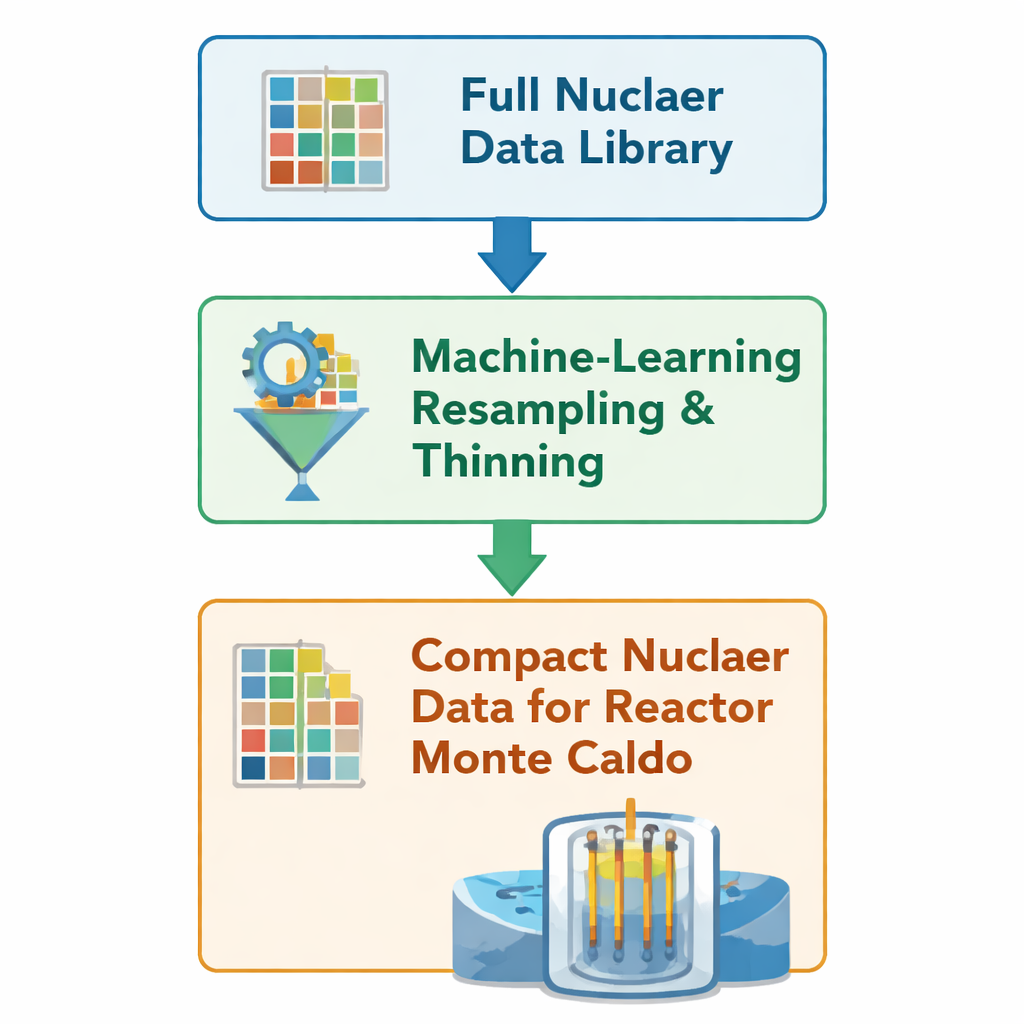
Poner la idea a prueba en núcleos de reactor completos
Para comprobar si estos datos más compactos siguen produciendo resultados fiables en escenarios realistas, el equipo ejecuta simulaciones de un año de duración de dos grandes reactores de agua a presión: un European Pressurized Reactor (EPR) y un VVER‑1000, usando el código Monte Carlo de código abierto OpenMC. Para cada núcleo realizan dos campañas idénticas salvo por los datos: una con la biblioteca completa y otra con la versión adelgazada por la máquina. Toda la geometría, condiciones de operación y parámetros numéricos se mantienen fijos; solo difieren las tablas de datos detrás de la física. Desactivan otras funciones de aceleración dentro de OpenMC para que cualquier cambio en velocidad o memoria pueda atribuirse directamente a la reducción de datos, no a cambios en algoritmos o ajustes.
Ganancias de velocidad con límites de error estrictos
El beneficio es sustancial. Para el caso EPR, el tiempo total de reloj cae en torno a un 18 %, y para el VVER‑1000 la duración de la ejecución se reduce aproximadamente un 43 %. El uso de memoria cambia de forma más modesta: el pico de uso disminuye alrededor de un 4 % en el EPR y aumenta cerca de un 5 % en el VVER‑1000, reflejando diferencias en cuánto tiempo pasa cada modelo consultando datos nucleares frente a seguir las trayectorias de partículas en la geometría. Crucialmente, las principales magnitudes a nivel de reactor se mantienen muy cercanas a las originales. A lo largo de un año completo en el VVER‑1000, el factor de multiplicación efectivo—esencialmente, cuántos neutrones produce en promedio cada fisión—no se desvía más de unas 100 partes por millón, y típicamente solo en unas pocas decenas de partes por millón. Para canales de reacción clave como la fisión en uranio‑235 y uranio‑238 y la captura de neutrones en xenón‑135 y samario‑149, las diferencias medias se mantienen muy por debajo de una décima de porcentaje.
La evolución del combustible y los venenos siguen la trayectoria esperada
Dado que el comportamiento a largo plazo del reactor depende no solo de reacciones instantáneas sino de cómo se acumulan y consumen el combustible y los productos de fisión, los autores también controlan los inventarios cambiantes de isótopos importantes. Examinaron los principales isótopos de uranio, una serie de isótopos de plutonio creados a partir del uranio‑238, y potentes nucleidos «veneno» que absorben neutrones, especialmente xenón‑135 y samario‑149. Incluso después de un año completo, las diferencias en estos inventarios entre los casos con datos completos y reducidos son mínimas: del orden de unas centésimas de por ciento para xenón y samario, y generalmente por debajo de una décima de por ciento para las especies de plutonio. El uranio‑235 y el uranio‑238, que dominan la producción de energía y el balance neutrónico del núcleo, se reproducen con una precisión mucho mejor que una centésima de por ciento. Cuando los errores relativos superan brevemente el 1 % para algunos isótopos de plutonio, ocurre al inicio del ciclo cuando sus cantidades absolutas aún son extremadamente pequeñas, por lo que el efecto práctico en el comportamiento del reactor es insignificante.
Qué significa esto para la simulación de reactores futura
Para no especialistas, el mensaje esencial es que un procedimiento de aprendizaje automático cuidadosamente entrenado puede hacer que las «tablas de consulta» nucleares dentro de simulaciones avanzadas de reactores sean mucho más pequeñas y rápidas de usar, manteniendo al mismo tiempo que el comportamiento simulado del reactor sea casi indistinguible del enfoque tradicional. El estudio demuestra esto en dos núcleos de reactor a escala industrial durante un año completo de operación, con márgenes de error que son pequeños en comparación con otras incertidumbres típicas en el análisis de reactores. Los autores enfatizan que sus conclusiones se aplican actualmente a reactores de agua a presión en régimen estacionario usando una biblioteca de datos y ajustes de código específicos, y que se requiere más trabajo para probar otros tipos de reactores y condiciones transitorias. Aun así, los resultados sugieren una vía prometedora hacia simulaciones nucleares de alta fidelidad más rápidas y eficientes, posibilitando más estudios de diseño y análisis de seguridad con recursos informáticos limitados.
Cita: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Palabras clave: simulación de reactores nucleares, aprendizaje automático, neutrónica Monte Carlo, bibliotecas de datos nucleares, reactores de agua a presión