Clear Sky Science · es
Detección eficiente de resúmenes científicos generados por IA con un transformador ligero
Por qué importa detectar ciencia escrita por IA
A medida que la inteligencia artificial mejora en la redacción, ahora puede elaborar resúmenes científicos que resultan casi indistinguibles de los escritos por personas. Eso plantea preguntas difíciles: ¿cómo pueden las revistas, las universidades y los lectores asegurarse de que un resumen de investigación refleja realmente el trabajo de un científico y no la invención de una máquina? Este artículo aborda ese problema construyendo una herramienta rápida y compacta que puede señalar resúmenes científicos escritos por IA con gran fiabilidad, ofreciendo una defensa práctica para la integridad académica.
Creando un banco de prueba de resúmenes reales y sintéticos
Para medir y mejorar la detección de texto generado por IA, los autores necesitaron primero datos fiables. Recopilaron 5.000 resúmenes científicos del servidor de preprints en línea arXiv, abarcando cinco áreas: visión por ordenador, procesamiento de señales, biología cuantitativa, física y otros temas de informática. Para cada resumen escrito por humanos, utilizaron un gran modelo de lenguaje para generar una versión de IA a partir del título del artículo, comprobando con cuidado duplicados cercanos y eliminando pistas obvias como direcciones web o fragmentos de código. También se aseguraron de que los textos de IA y humanos tuvieran longitudes similares, de modo que el detector no pudiera basarse simplemente en estadísticas toscas como el recuento de palabras.
Un modelo compacto afinado para el mundo real
En lugar de usar un modelo enorme y costoso, los investigadores optaron por un sistema más pequeño conocido como DistilBERT, una versión simplificada de un modelo de lenguaje popular. Lo ajustaron para decidir, para cada resumen, si había sido escrito por una persona o generado por IA. El modelo procesa hasta 256 tokens—aproximadamente unos pocos párrafos—y devuelve una puntuación entre cero y uno, interpretada como la probabilidad de que el texto sea obra de una máquina. El entrenamiento y la evaluación siguieron un protocolo estricto: los datos se dividieron en conjuntos de entrenamiento, validación y prueba sin solapamientos, y el equipo informó no solo la exactitud sino también cómo se comporta el modelo cuando la tasa de falsas alarmas permitida se mantiene muy baja, un régimen que importa al acusar a autores reales de usar IA.
Cómo rinde el detector
En los resúmenes de visión por ordenador, el principal banco de pruebas, el detector fue notablemente preciso. Etiquetó correctamente 499 de 500 textos generados por IA y 495 de 500 textos humanos, logrando alrededor de un 99,4% de exactitud y una puntuación casi perfecta en una curva de rendimiento estándar. Cuando los autores restringieron el sistema a cometer como máximo una acusación falsa en cada cien casos, aún detectó alrededor del 90% de los textos de IA; con una tolerancia algo mayor de cinco falsas alarmas por cada cien, detectó aproximadamente el 97%. En comparación con una variedad de alternativas—incluyendo herramientas estadísticas más simples y otros modelos transformadores—el detector compacto se impuso de forma consistente, especialmente en escenarios más exigentes.
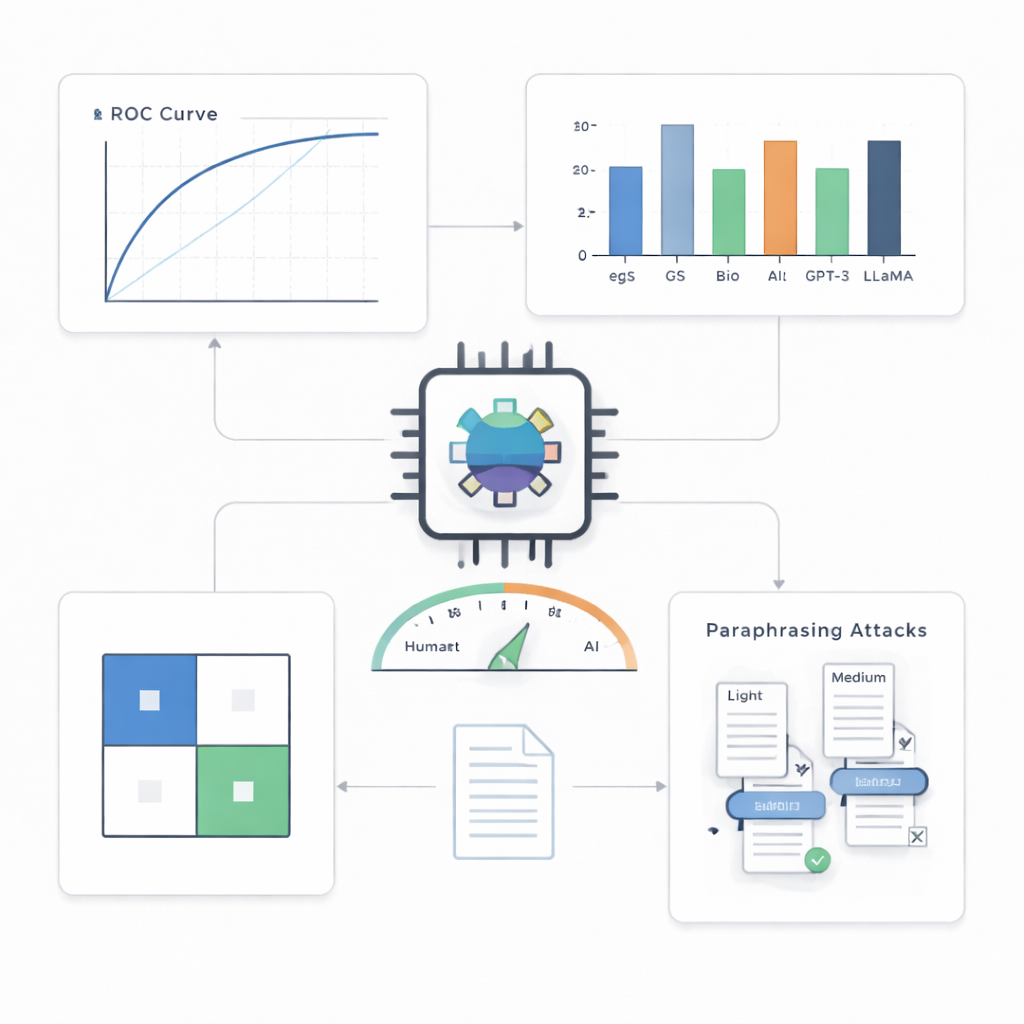
Más allá de un campo, un modelo y trucos sencillos
Una cuestión clave es si tal detector puede manejar estilos de escritura y sistemas de IA que nunca ha visto. Los autores lo probaron con resúmenes de otros campos científicos y con textos generados por varios modelos de lenguaje avanzados. A través de dominios, el rendimiento se mantuvo sólido, con solo descensos modestos, lo que sugiere que el sistema capta patrones generales de la escritura de IA más que peculiaridades de una sola área temática. Frente a modelos de IA no vistos, también funcionó bien, aunque menos perfectamente que en su entorno principal. El desafío más duro provino de ataques de parafraseo: cuando otra IA reescribió resúmenes generados por máquinas para que sonaran distintos manteniendo su significado, la detección se volvió notablemente más difícil. Bajo reescrituras de intensidad media, la proporción de textos de IA que pasaron desapercibidos subió hasta casi el 30%, lo que revela que incluso detectores sofisticados pueden ser engañados por la ofuscación deliberada.
Qué implica esto para la ciencia y sus salvaguardas
El estudio muestra que, por ahora, los resúmenes científicos escritos por IA todavía dejan rastros sutiles que un modelo bien diseñado puede detectar, incluso cuando ese modelo es lo bastante pequeño como para ejecutarse en hardware modesto. Esto hace factible que editoriales, congresos y universidades examinen grandes volúmenes de envíos sin costos informáticos enormes. Al mismo tiempo, la vulnerabilidad al parafraseo subraya que tales herramientas no son una solución mágica. Los autores sostienen que la detección de texto generado por IA debería combinarse con otras salvaguardas—como el juicio editorial, comprobaciones de plagio y requisitos de transparencia—para proteger la fiabilidad de la comunicación científica a medida que los sistemas de IA siguen mejorando.
Cita: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Palabras clave: Detección de texto IA, resúmenes científicos, integridad académica, modelos de lenguaje grandes, texto generado por máquina